本文已收录到:机器学习笔记 专题
- 机器学习的学习顺序、书籍和一些体会
- 朴素贝叶斯 – 根据男性特征分析女性是否嫁的问题
- 感知机 – 一种二分类线性分类模型,划分红豆和绿豆
- 逻辑斯谛回归 – 不那么生硬的划分红豆和绿豆
- 支持向量机:线性可分支持向量机与硬间隔最大化
- 支持向量机:线性可分支持向量机与软间隔最大化
- 利用集成方法提高基分类器分类性能
- 集成方法之Bagging装袋法:三个臭皮匠投票、少数服从多数
- 集成方法之Boosting提升方法:更像现实中实际学习的模型
- 决策树不仅可以做分类,还可以回归:回归树
- K-均值聚类算法,对无标签数据进行分组汇聚
- Apriori算法进行关联分析
- 使用FP-growth算法高效的挖掘海量数据中的频繁项集
- 维度是什么?数据降维方法,降维的用途
- 最广泛的降维算法:主成分分析(PCA)【原理讲解+代码】
- 人工神经网络(ANN)及BP算法原理
- 深度学习常用数据集、发展脉络和工具框架介绍
- 自编码器 – 经典的无监督学习神经网络、领会它的思想
- 卷积神经网络:卷积就是特征提取器,就是CBAPD
- 循环神经网络(RecurrentNN):有记忆的神经网络
逻辑斯蒂回归模型
一个思考:回想感知机模型,划分出来的一条线非常“生硬”的把两类点划分开,但是真的可以说距离超平面左侧0.001的距离和距离超平面右侧0.001距离的两个点有着天壤之别的区分吗?

提出问题:我们想找到一个在区间上连续可微的函数,使得不像原来的感知机那样“生硬”。
- 解决极小距离带来的天壤之别问题?
- 如何让最终的预测式子连续可微?
——使用逻辑斯蒂回归
逻辑斯谛回归定义
$P(Y=1|x) = \frac{e^{w^{T} x} }{1+e^{w^{T} x} } = A$
$P(Y=0|x) = \frac{1}{1+e^{w^{T} x} } = B$
A+B=1,若A>B,则输出1。
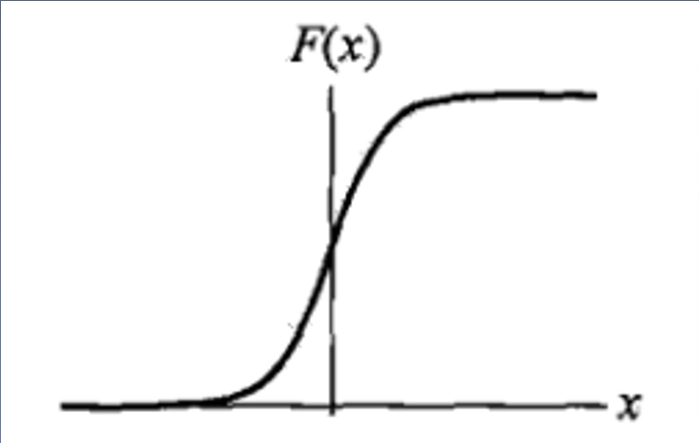
好处:
- 整个函数连续可微。
- 因为存在A+B=1的关系,所以可以输出概率。
学习策略&算法
参数估计
使用极大似然估计估计模型参数w和b,从而得到逻辑斯谛回归模型。
设:$P(Y=1|x) = \pi (x), P(Y=0|x) = 1-\pi (x)$
似然函数为:$\prod_{i=1}^{N} {[\pi (x_{i} )]} ^{y_{i}}[1-\pi(x_{i})]^{1-y_{i}}$
对数似然函数为:
$L(w)=\sum_{i=1}^{N}log( [\pi (x_{i})]^{y_{i}}[1-\pi (x_{i})]^{1-y{i}})$
= $\sum_{i=1}^{N}(log [\pi (x_{i})]^{y_{i}}+log[1-\pi (x_{i})]^{1-y{i}})$
= $\sum_{i=1}^{N}(y_{i}log [\pi (x_{i})]+(1-y_{i})log[1-\pi (x_{i})])$
= $\sum_{i=1}^{N}(y_{i}log [\pi (x_{i})]+log([1-\pi (x_{i})])-y_{i}log([1-\pi (x_{i})]))$
= $\sum_{i=1}^{N}(y_{i}log \frac{\pi (x_{i})}{1-\pi (x_{i})} +log([1-\pi (x_{i})]))$
= $\sum_{i=1}^{N}(y_{i}log \frac{P(Y=1|x)}{P(Y=0|x)} +log(P(Y=0|x)))$
= $\sum_{i=1}^{N}(y_{i}log e^{w^{T}x } +log\frac{1}{1+e^{w^T}x} )$
= $\sum_{i=1}^{N}(y_{i}{w^{T}x } +log{(1+e^{w^T}x})^{-1}$
= $\sum_{i=1}^{N}(y_{i}{w^{T}x } -log{(1+e^{w^T}x}))$
Ps:在机器学习中,没有特殊说明一般log的底数都是e,即ln。

损失函数得到w的估计值
对L(w)求极大值,得到w的估计值。现在问题转变未对上面的对数似然函数求最优化问题,最优化方法有很多种,在逻辑斯蒂回归中我们采用的方法一般是梯度下降法和拟牛顿法。
全批量梯度上升算法
接下来使用梯度上升算法。首先对似然函数L(w)求w的偏导:
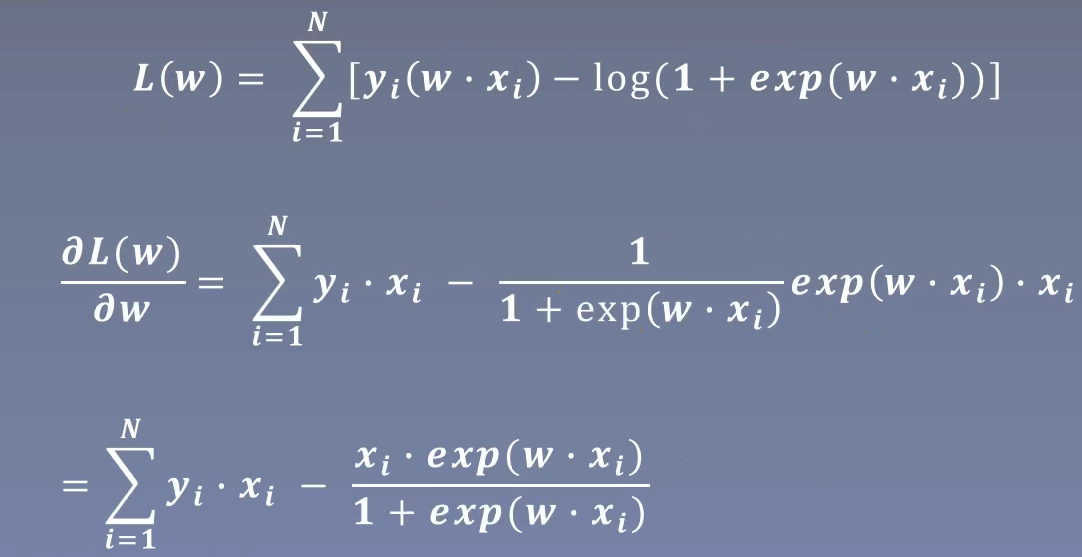
$=\sum_{i=1}^{N}x_{i}(y_{i}-\frac{e^{(w^Tx)}}{1+e^{(w^Tx)}}) $
$=\sum_{i=1}^{N}x_{i}(y_{i}-{\pi (x_{i})}) $
全批量梯度上升法的迭代公式:
$w := w + \alpha \sum_{i=1}^{N}x_{i}(y_{i}-\pi (x_{i}))$
全批量梯度上升法公式:
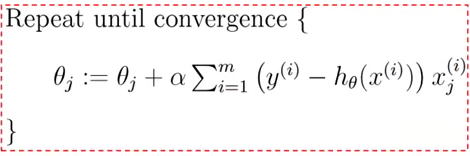
上图算出的$\theta $是一个向量。还有一种随机梯度上升法,接下来我们比较下全批量梯度上升法和随机梯度上升的区别和各个优势。
改机:随机梯度上升法
下图是随机梯度上升法的公式,算出的$\theta $是一个值。
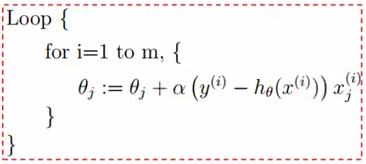
参考文献:
https://www.bilibili.com/video/BV1i4411G7Xv?p=6