本文已收录到:机器学习笔记 专题
- 机器学习的学习顺序、书籍和一些体会
- 朴素贝叶斯 – 根据男性特征分析女性是否嫁的问题
- 感知机 – 一种二分类线性分类模型,划分红豆和绿豆
- 逻辑斯谛回归 – 不那么生硬的划分红豆和绿豆
- 支持向量机:线性可分支持向量机与硬间隔最大化
- 支持向量机:线性可分支持向量机与软间隔最大化
- 利用集成方法提高基分类器分类性能
- 集成方法之Bagging装袋法:三个臭皮匠投票、少数服从多数
- 集成方法之Boosting提升方法:更像现实中实际学习的模型
- 决策树不仅可以做分类,还可以回归:回归树
- K-均值聚类算法,对无标签数据进行分组汇聚
- Apriori算法进行关联分析
- 使用FP-growth算法高效的挖掘海量数据中的频繁项集
- 维度是什么?数据降维方法,降维的用途
- 最广泛的降维算法:主成分分析(PCA)【原理讲解+代码】
- 人工神经网络(ANN)及BP算法原理
- 深度学习常用数据集、发展脉络和工具框架介绍
- 自编码器 – 经典的无监督学习神经网络、领会它的思想
- 卷积神经网络:卷积就是特征提取器,就是CBAPD
- 循环神经网络(RecurrentNN):有记忆的神经网络
卷积
- 卷积计算是一种有效的特征提取方法,卷积核可以有效提取图像特征。
- 一般会用一个正方形的卷积核,按指定步长,在输入特征图上滑动,遍历输入特征图中的每个像素点。每一个步长,卷积核会与输特征图出现重合区域,重合区域对应元素相乘、求和再加上偏置得到输出特征的一个像素点。
卷积核的选取
卷积核的值是给定的,然后通过反向传播来更新这些值。
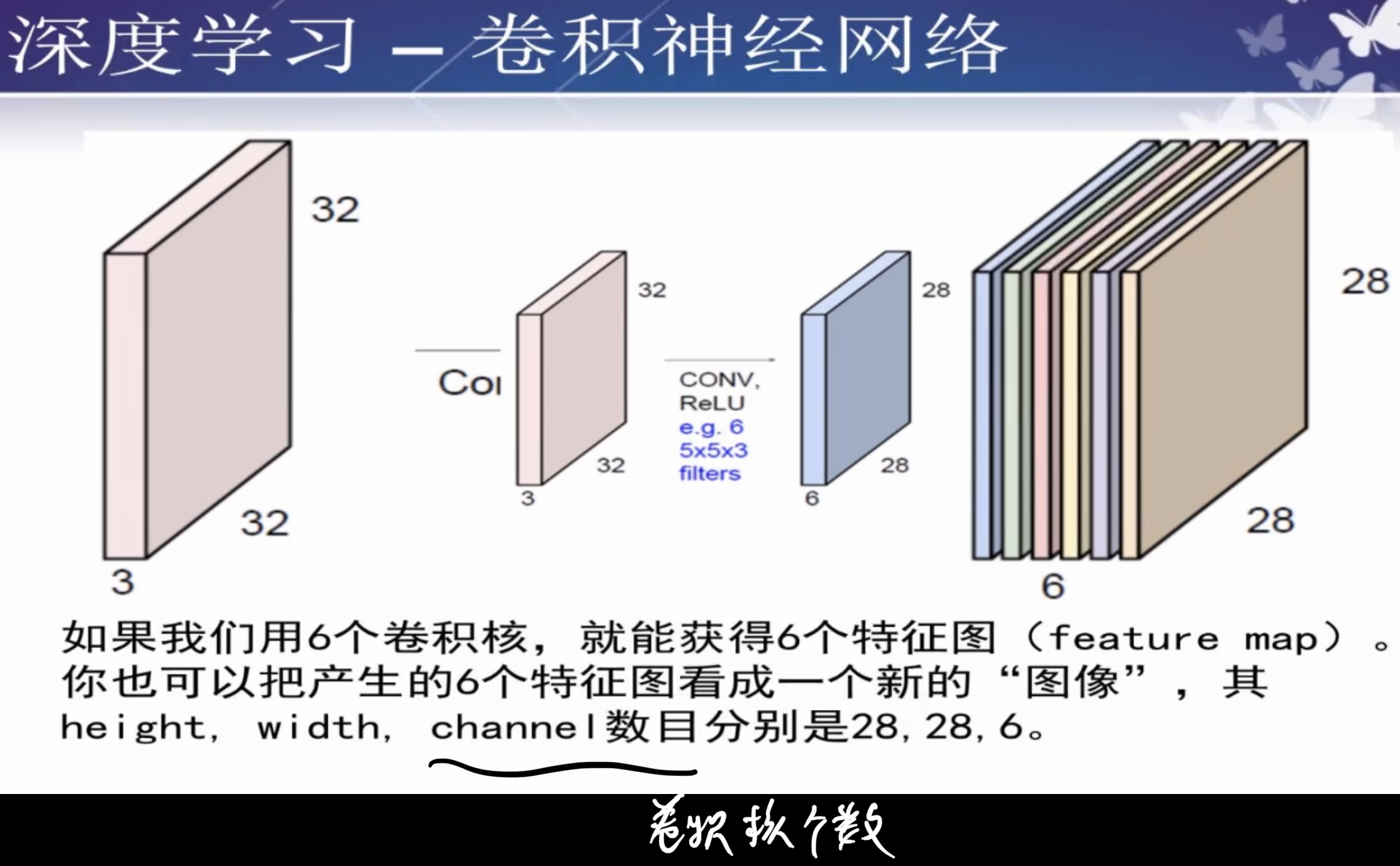
如果输入的特征是单通道灰度图(左),使用3x3x1的卷积核;如果是三通道的彩色图则使用3x3x3的卷积核,或者是5x5x3的卷积核。
要使得卷积核的深度与输入特征图的深度一致。

每个卷积核中的每个颗粒存储着卷积核提供的默认的带待训练的参数,在每次反向传播时,会被梯度下降法更新。

卷积核的个数就是特性图的个数

每个卷积核都有一个偏置参数。Ps:在caffe和tensorflow模块中都有选项供选择是否含有偏置。
针对不同的特征,会有不同卷积核(可参考opencv中提供了哪些卷积核)。
Ps:
- 卷积核的值不用算,针对不同问题,可选专门的卷积核。
- 卷积核的参数是待训练的参数,初始化的时候可以随机生成。
- 值是给定的,然后通过反向传播来更新这些值。
共享权重
卷积就是利用立体卷积核实现参数空间共享。
卷积神经网络可以看作多层共享权重的神经网络。

卷积计算过程
计算方法:一般会用一个正方形的卷积核,按指定步长,在输入特征图上滑动 ,遍历输入特征图中的每个像素点。每一个步长,卷积核会与输入特征图出现重合区域,重合区域对应元素相乘、求和再加上偏置项得到输出特征的一个像素点。

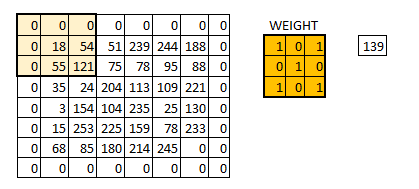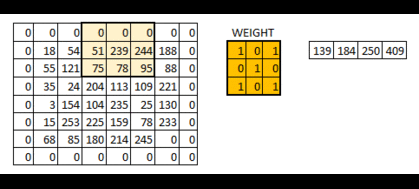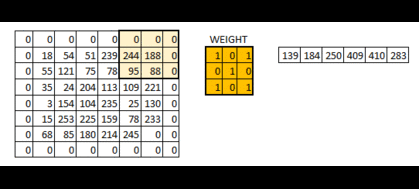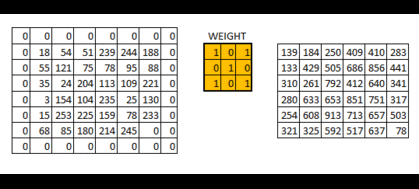
对于每一个卷积核,要有一个单独的偏置(b1 b2 b3 b4)。请注意移动的步伐也是有步长的。卷积核的个数也可以有多个。
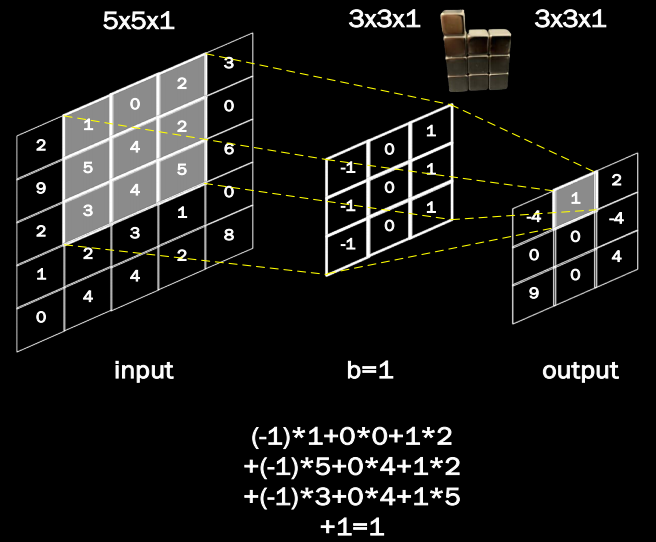
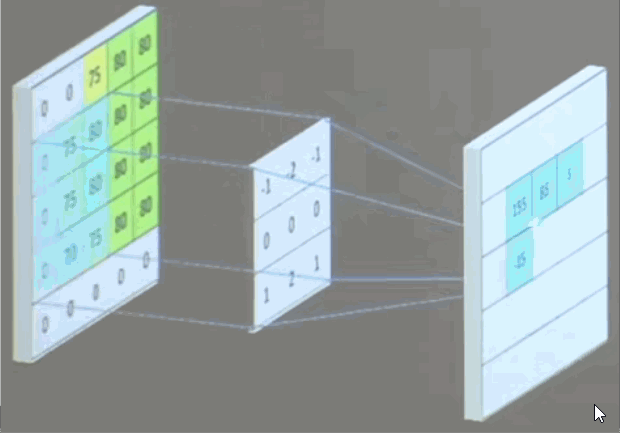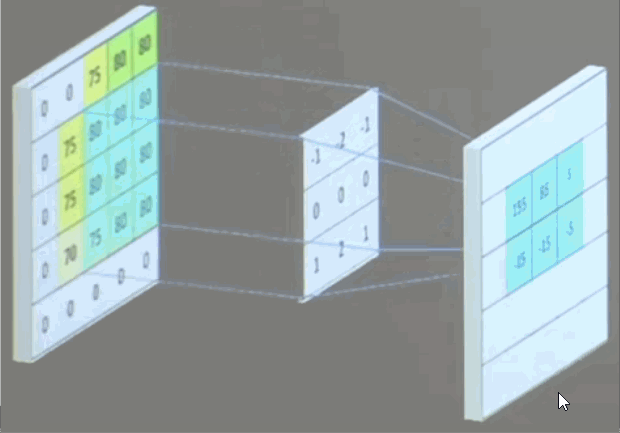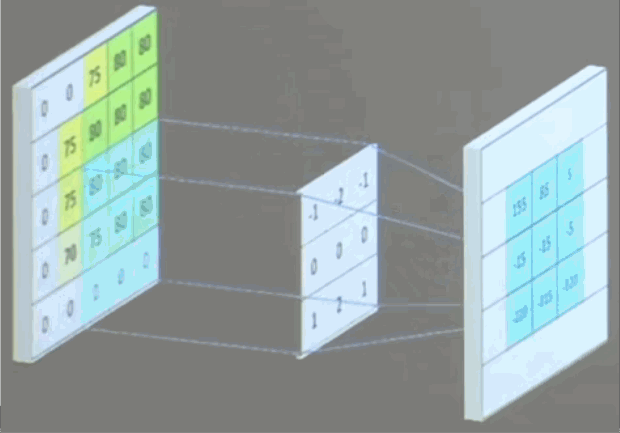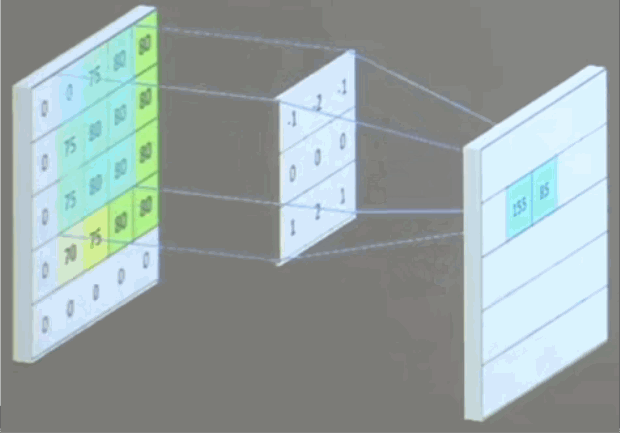
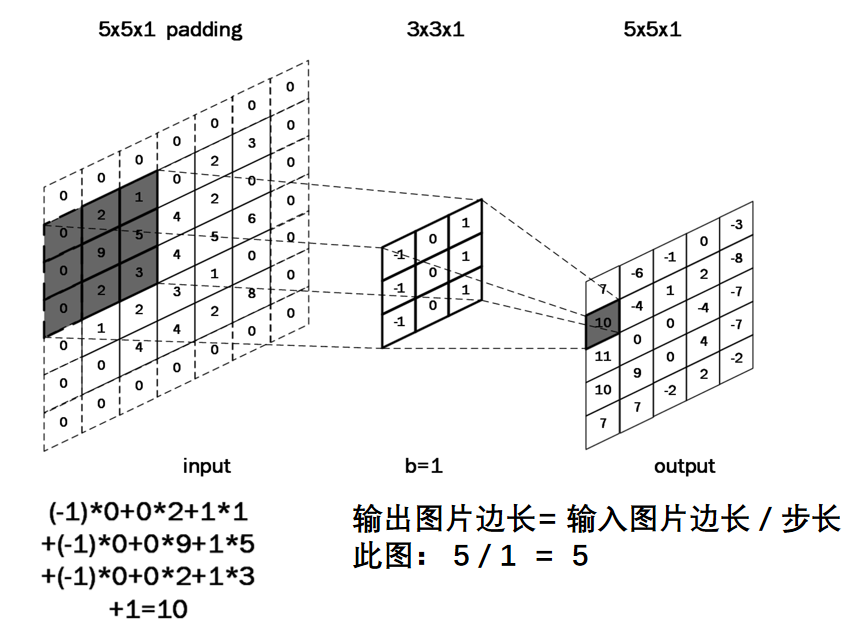
eg:使用一个3x3x1的卷积核对5x5x1的图像卷积计算:
对于三通道数据:
使用3x3x3通道的卷积核,滑动步长为1。
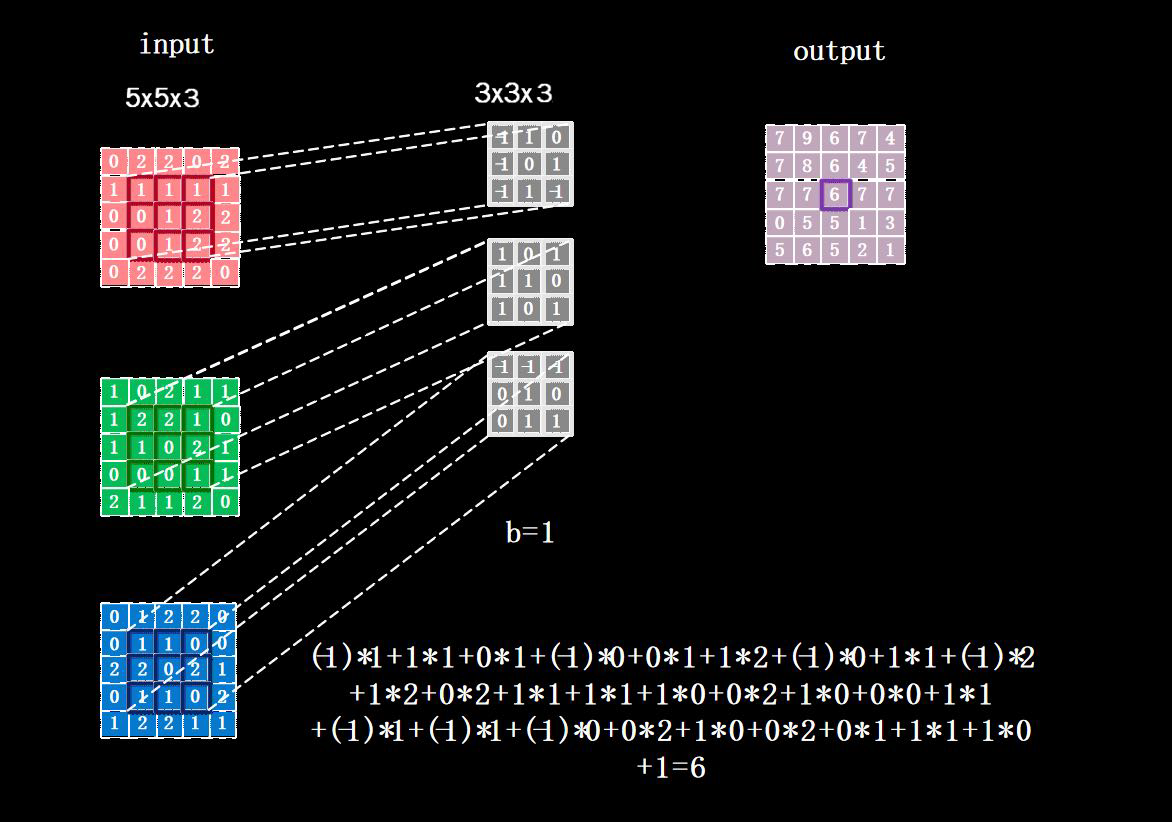
如果有n张卷积核,那就会输出n张特征图。
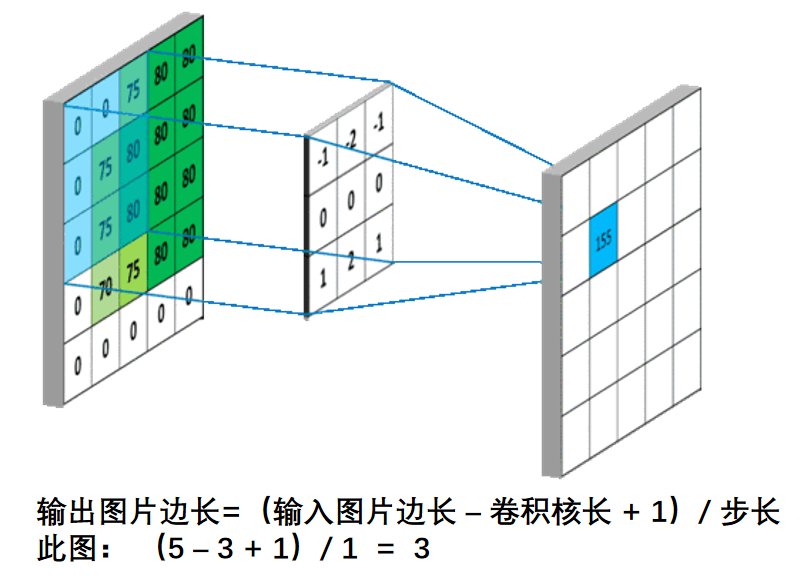
补充:输出特征图长宽计算公式
输入图片为5×5,卷积核为3×3,假设步长为1,得到的输出特征图为3×3。总结出下面的计算公式:
补充:感受野
卷积神经网络各输出层每个像素点在原始图像上的映射区域大小。野就是“视野”,输出收到多大输入范围的影响,就说它的“视野”有多大,也就是特征保留的范围有多大。
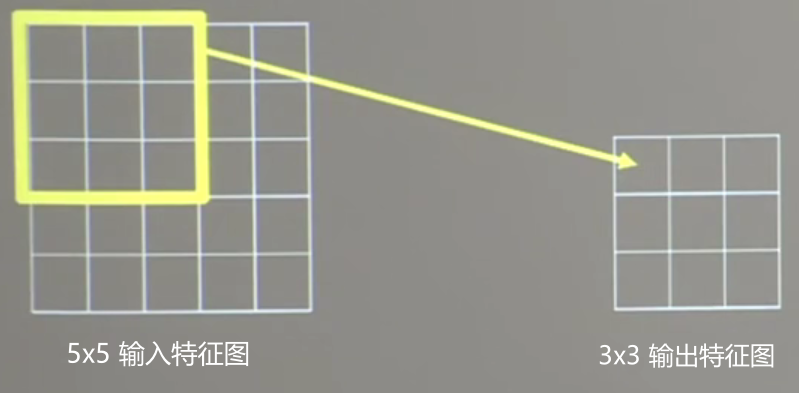
如上图所示,用一个3×3的卷积核对一个5×5的输入特征图进行卷积计算,得到的输出特征图是一个3×3的,映射到原始输入图片是一个3×3的区域,所以他的感受野是3。再用一个绿色的3×3卷积核再次对3×3图像进行卷积,得到一个1×1的输出特征图,这个特征图映射到原始图像(最左边的图)是一个5×5的区域,所以他的感受野为5。

如果对原始图像直接用5×5的卷积核卷积,得到的是1×1的输出特征图,这个特征图映射到原始图像是一个5×5的区域,所以感受野为5。

发现:同样的5×5原始图片。通过两个3×3的卷积核和通过一个5×5的卷积核的作用得出来的都是一个感受野为5的特征提取图。他们的特征提取能力是一样的。
选择两个3×3的还是一个5×5的卷积核呢?
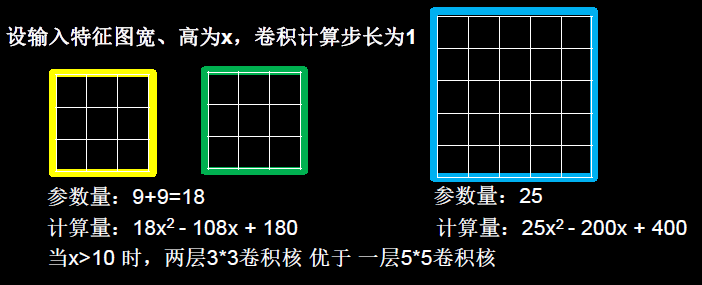
简述下计算公式是怎么推出来的。
特征图长宽:第一个3 * 3卷积核(黄图)输出特征图的边长为(x – 3 + 1)。——根据上一小节公式
特征图像素点个数:因为特征图都是正方形,所以共有(x – 3 + 1)^2个像素点。
单个像素点计算次数:每个等于卷积核的参数个数,每个参数都需要与原始图像做乘法运算,后累加。所以每个像素点需要进行3 * 3 = 9次乘加运算。
总计算量:(3*3)*(x – 3 + 1)^2
黄色的特征图计算量已经计算好了,还有个绿图,他也是相同的计算量。
所以使用两个3×3的卷积核一共计算量为2*(3*3)*(x – 3 + 1)^2次。
右边蓝图5×5的卷积核计算量为(5*5)*(x-5+1)^2次。
补充:全零填充——padding补0
全零填充:
在tensorflow中,提供了选项参数是否使用全零填充:

批标准化(Batch Normalization)
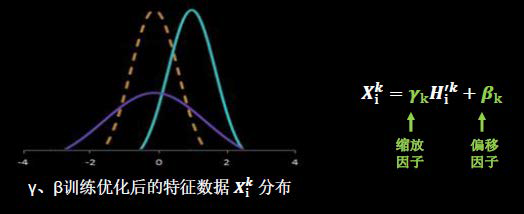
因为输入图像有些数值非常的偏离,使用标准化处理可以使数据符合以0为均值,1为标准差的分布。把偏移的特征数据重新拉回到0附近。

BN操作将原本偏移的特征数据重新拉回到0附近,使得输入数据微小的变化也能够被捕获到。
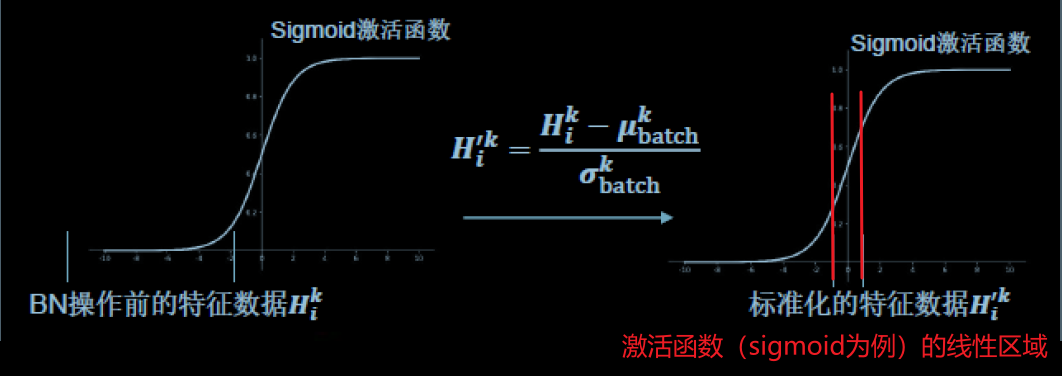
BN操作的另一个重要步骤是缩放和偏移,缩放因子γ以及偏移因子β都是可训练参数。
可以优化特征数据分布的高低和宽窄分布。

池化(pooling)
作用:减少特征数量(降维)。
池化的主要方法有两种,最大值池化和均值池化。
- 最大值池化可提取图片纹理。
- 均值池化可保留背景特征。
最大池化:

均值池化:

舍弃
为了缓解神经网络的过拟合,在训练的时候通常要随机舍弃隐藏层的部分神经元,在使用神经网络的时候再将其恢复。
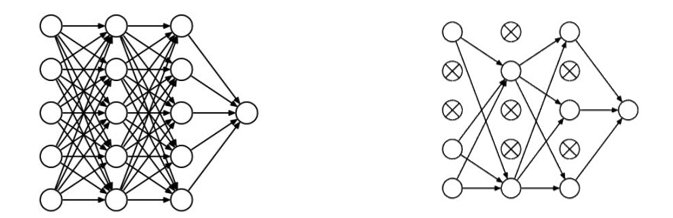
在TensorFlow中提供参数供我们舍弃一定比例的神经元:

卷积神经网络总结

———后续的部分单独另起一篇文章作为实例讲解———
cifar10数据集
卷积神经网络搭建实例
实现经典的五个卷积神经网络

参考文献:
https://www.bilibili.com/video/BV1Cg4y1q7Xq?p=26