本文已收录到:机器学习笔记 专题
- 机器学习的学习顺序、书籍和一些体会
- 朴素贝叶斯 – 根据男性特征分析女性是否嫁的问题
- 感知机 – 一种二分类线性分类模型,划分红豆和绿豆
- 逻辑斯谛回归 – 不那么生硬的划分红豆和绿豆
- 支持向量机:线性可分支持向量机与硬间隔最大化
- 支持向量机:线性可分支持向量机与软间隔最大化
- 利用集成方法提高基分类器分类性能
- 集成方法之Bagging装袋法:三个臭皮匠投票、少数服从多数
- 集成方法之Boosting提升方法:更像现实中实际学习的模型
- 决策树不仅可以做分类,还可以回归:回归树
- K-均值聚类算法,对无标签数据进行分组汇聚
- Apriori算法进行关联分析
- 使用FP-growth算法高效的挖掘海量数据中的频繁项集
- 维度是什么?数据降维方法,降维的用途
- 最广泛的降维算法:主成分分析(PCA)【原理讲解+代码】
- 人工神经网络(ANN)及BP算法原理
- 深度学习常用数据集、发展脉络和工具框架介绍
- 自编码器 – 经典的无监督学习神经网络、领会它的思想
- 卷积神经网络:卷积就是特征提取器,就是CBAPD
- 循环神经网络(RecurrentNN):有记忆的神经网络
衡量频繁项集的标准
支持度
支持度就是几个关联的数据在数据集中出现的次数占总数据集的比重,或者说几个数据关联出现的概率。一般取值为[0, 1]。
有两个想分析关联性的数据X和Y,则对应的支持度为:
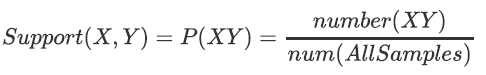

支持度是一种重要度量,因为支持度很低的规则可能只是偶然出现。从商务角度来看,低支持度的规则多半也是无意义的,因此,支持度通常用来删去那些无意义的规则。
置信度
置信度体现了一个数据出现后,另一个数据出现的概率,或者说数据的条件概率,一般取值范围为[0, 1]。
两个想分析关联性的数据X和Y,X对Y的置信度为:

置信度阈值 -> 关联规则。
置信度度量通过规则进行推理具有可靠性。对于给定的规则X→Y,置信度越高,Y在包含X的事务中出现的可能性就越大。置信度也可以估计Y在给定X下的条件概率。
置信度的缺点在于该度量忽略了规则后件中项集的支持度。
前件和后件
前件和后件:对于规则{X}->{Y},{X}叫前件,{Y}叫后件。
提升度
提升度计算:含有Y的条件下同时含有X的概率与X总体发生的概率之比。
提升度表示X->Y的置信度与后件Y的支持度之比。取值可能<1、=1、>1我们重点关注>1的提升度(表示有效的强关联规则), 提升度<=1则是无效的强关联规则 。
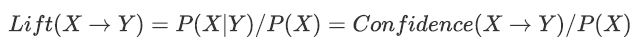
从超市订单中寻找商品关联性,算法示例

薯片的支持度:$\frac{4}{5} $
可乐的支持度:$\frac{3}{5} $
铅笔的支持度:$\frac{3}{5} $
羽毛球的支持度:$\frac{4}{5} $
洗衣液的支持度:$\frac{1}{5} $
题目会告诉我们最小支持度,本题给出的最小支持度为0.2。
频繁项集
下面将支持度>0.2($\frac{1}{5} $,具体这里的临界条件可以根据需要确定)的商品提取出来:只有A、B、C和D。所以得到1-频繁项集:

A、B、C和D两两组合得到2-项集合,然后计算A,B两种商品的支持度,依然将>0.2的保留下来。计算方法如下:
A、B的支持度计算就是将同时购买A和B的订单算作一次有效订单,作为分子,分母不变还是订单总个数。


计算某一集合的子集

终止条件&得到所有的频繁项集
以此类推,循环:


例如{(A,B)}的置信度是A出现的条件下B出现的概率(即条件概率),
$P(A \to B) = P(B\mid A) = \frac{P(AB)}{P(A)} = \frac{2}{4} $
代码实现
jupyter源代码:Python代码_Apriori算法及关联规则
参考文献:
上海杉达学院《数据挖掘》吴玉佳 期末复习题
https://www.bilibili.com/video/BV1Vi4y1R7id
https://www.bilibili.com/video/BV15Z4y1p7ev