本文已收录到:机器学习笔记 专题
- 机器学习的学习顺序、书籍和一些体会
- 朴素贝叶斯 – 根据男性特征分析女性是否嫁的问题
- 感知机 – 一种二分类线性分类模型,划分红豆和绿豆
- 逻辑斯谛回归 – 不那么生硬的划分红豆和绿豆
- 支持向量机:线性可分支持向量机与硬间隔最大化
- 支持向量机:线性可分支持向量机与软间隔最大化
- 利用集成方法提高基分类器分类性能
- 集成方法之Bagging装袋法:三个臭皮匠投票、少数服从多数
- 集成方法之Boosting提升方法:更像现实中实际学习的模型
- 决策树不仅可以做分类,还可以回归:回归树
- K-均值聚类算法,对无标签数据进行分组汇聚
- Apriori算法进行关联分析
- 使用FP-growth算法高效的挖掘海量数据中的频繁项集
- 维度是什么?数据降维方法,降维的用途
- 最广泛的降维算法:主成分分析(PCA)【原理讲解+代码】
- 人工神经网络(ANN)及BP算法原理
- 深度学习常用数据集、发展脉络和工具框架介绍
- 自编码器 – 经典的无监督学习神经网络、领会它的思想
- 卷积神经网络:卷积就是特征提取器,就是CBAPD
- 循环神经网络(RecurrentNN):有记忆的神经网络
聚类可以解决实际中的什么问题?
聚类是一种无监督学习方法,所谓无监督学习就是数据没有标签。
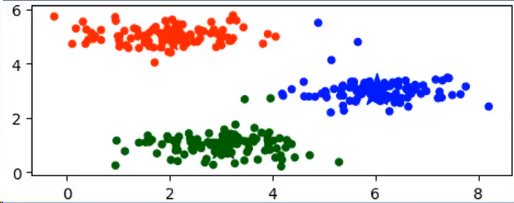
物以类聚人以群分,聚类顾名思义就是将一些属性相似的东西归结在一起。
现实中,例如银行对客户群,哪些客户是可以盈利的,而哪些客户是不仅不挣钱还要赔钱的。我们可以将他们划分出来,以便后续的营销使用。这就是客户群划分所能利用的聚类。

社交软件例如微信好友之间的联系,联系较多的人我们可以将他们聚集在一起,认为关系比较好。
异常数据存在异常特征,发现孤立点可以排查是否发生信用卡诈骗、黑客攻击等。

聚类都有哪些算法?
聚类算法有很多种,例如原型聚类、密度聚类、层次聚类等。
在西瓜书中讲解的聚类算法较多,有需要的同学可以研读西瓜书中的第九章聚类算法。
在《统计学习方法》书中主要讲解了层次聚类。
在《机器学习实战》这本书中,聚类算法只讲解了一个K均值算法(K-means)。
但实际上聚类算法有非常多:

聚类算法
举个例子:
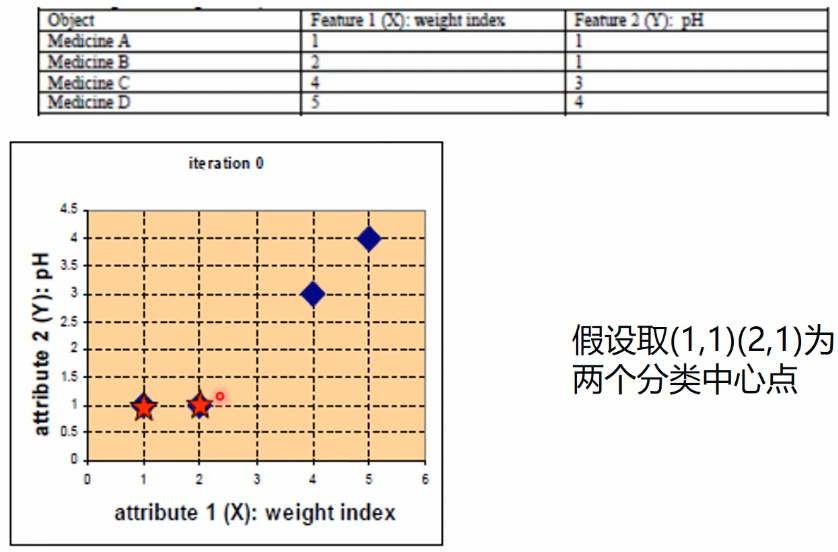
现在有四个对象A、B、C和D,拥有特征1和特征2。(请注意,这里和有标签的有监督学习不同,y并不是标签而是一个特征)
取初始重心点
计算样本点到质心的距离
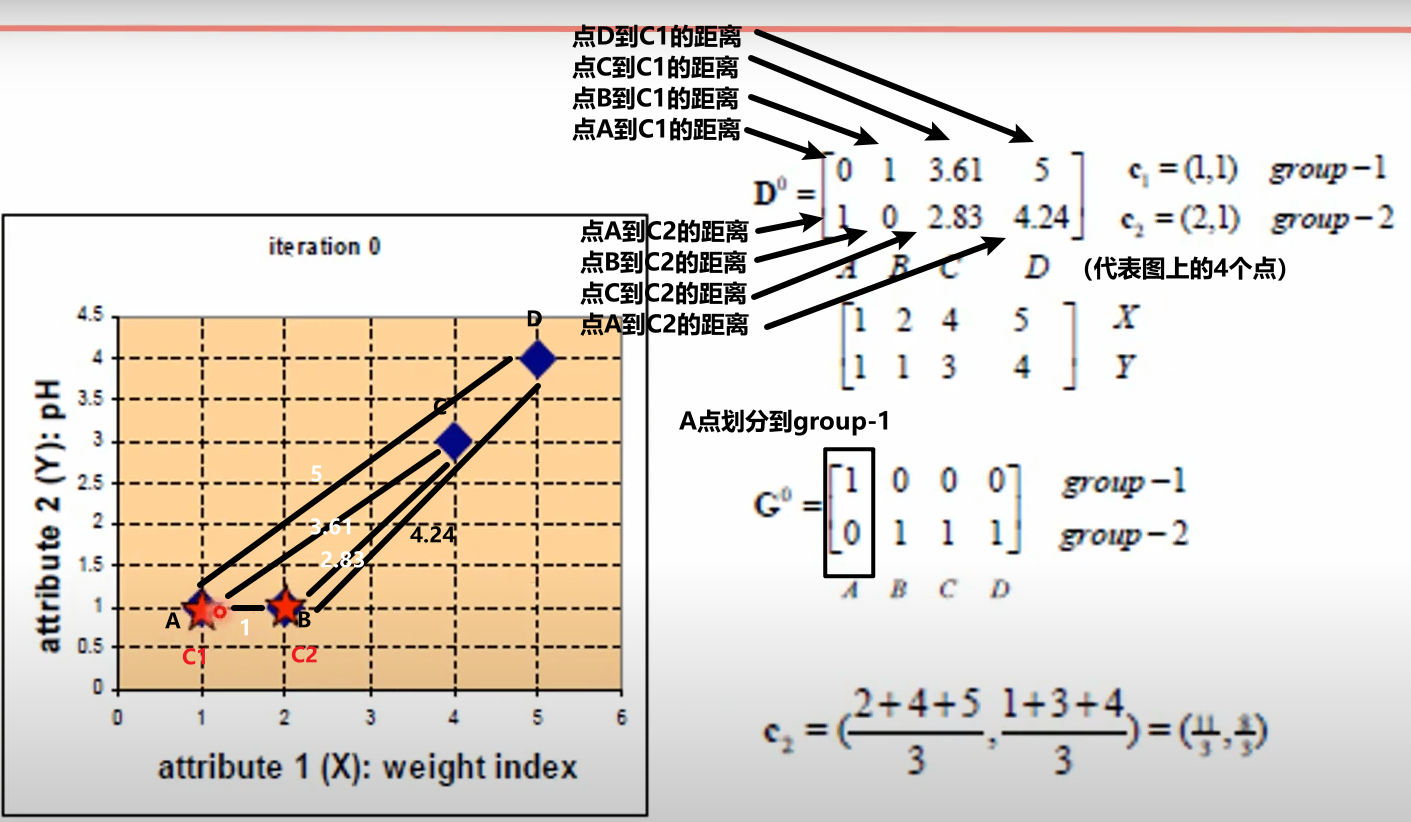
更新样本的簇
根据A、B、C、D四个点到C1、C2的距离远近,距离C1近的划分到C1类,距离C2近的划分到C2类。
现在,A划分到group-1、B、C、D划分到group-2。
重新计算重心
因为A点就是在C1上的,所以重心没有变化。
B、C、D三个点距离C2都是有距离的,需要计算C2的点位(三个点的重心)。计算的方法是算数平均数。
得到新的C2坐标:
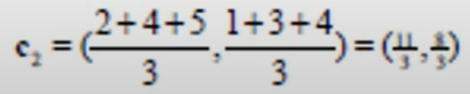
继续计算,不断的更迭C1、C2坐标:
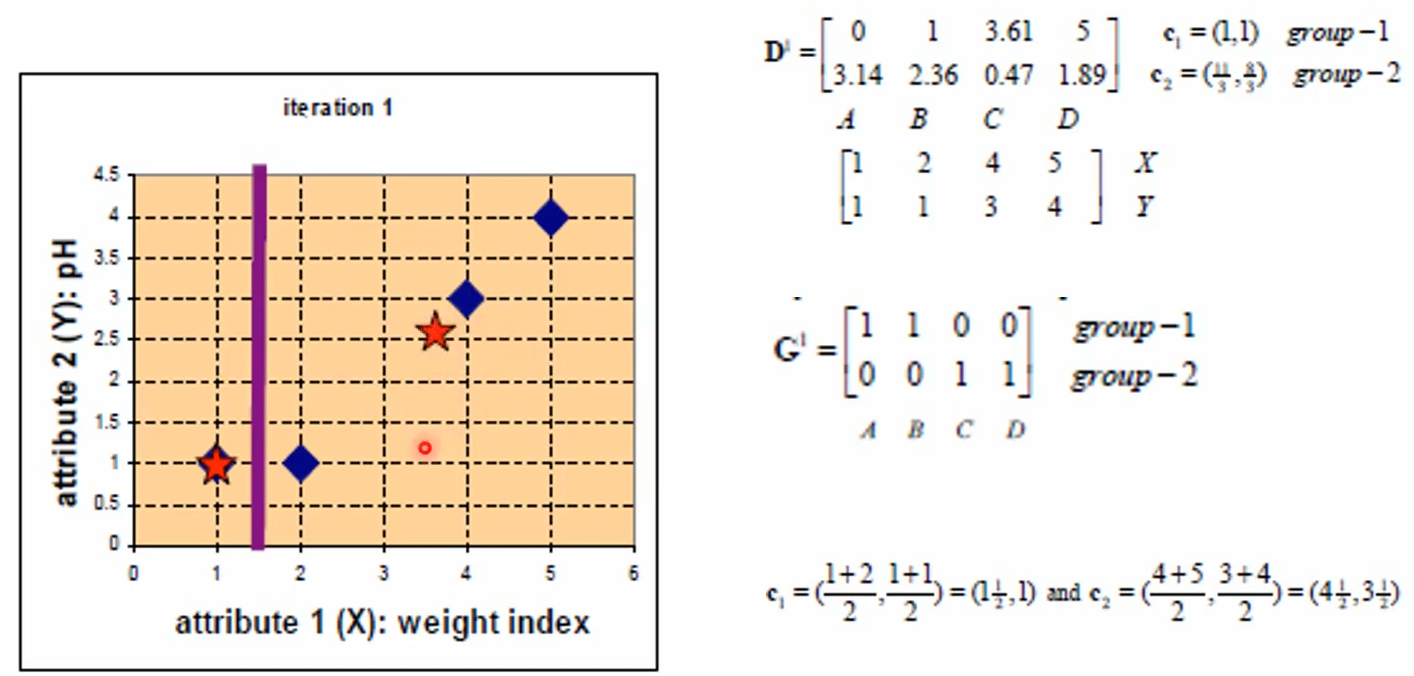
继续更迭C1、C2坐标:
终止条件
直到C1、C2重心点坐标不发生变化,终止循环。

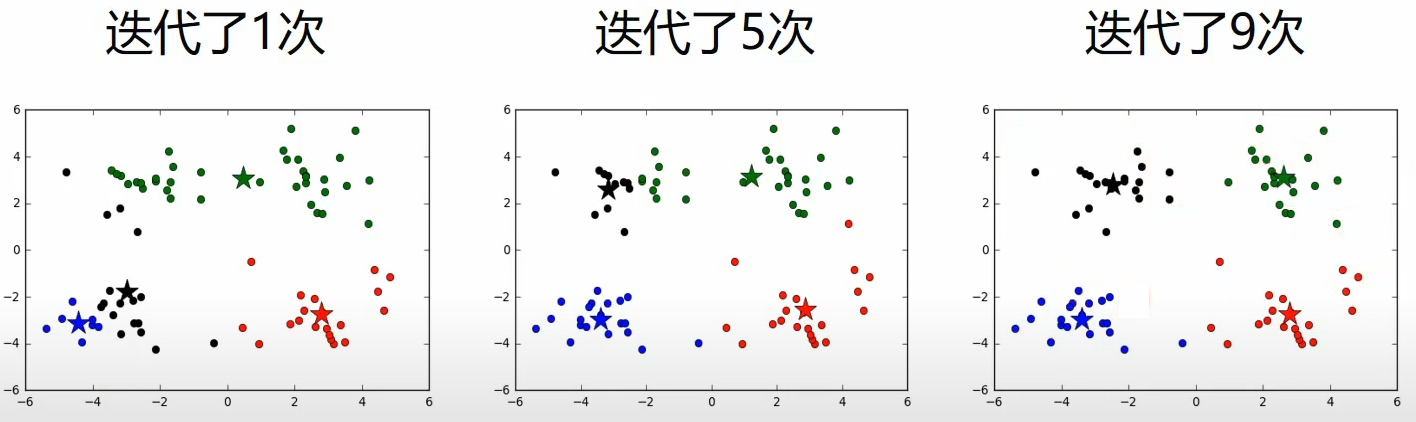
python实现k-means
jupyter源文件:python实现K-MEANS
问题一:局部最小值,初始点的选取也会影响聚类效果
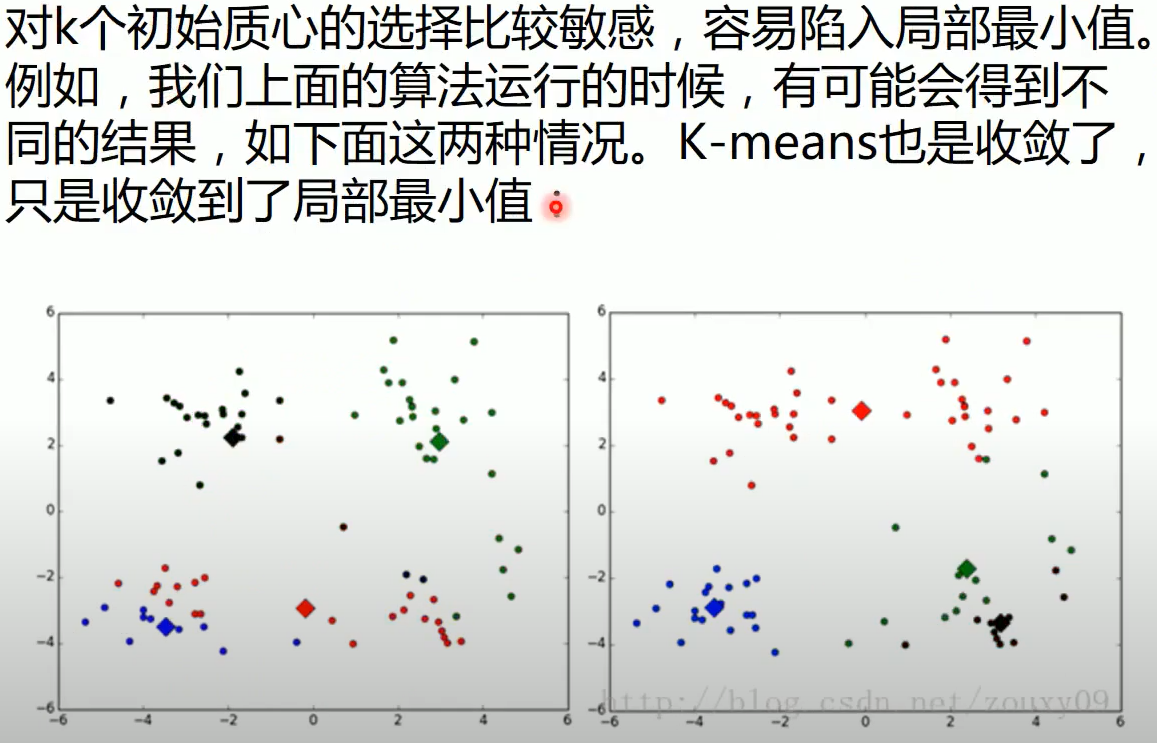
下图的初始点选取较差:

而这张图的初始点选取效果较好:
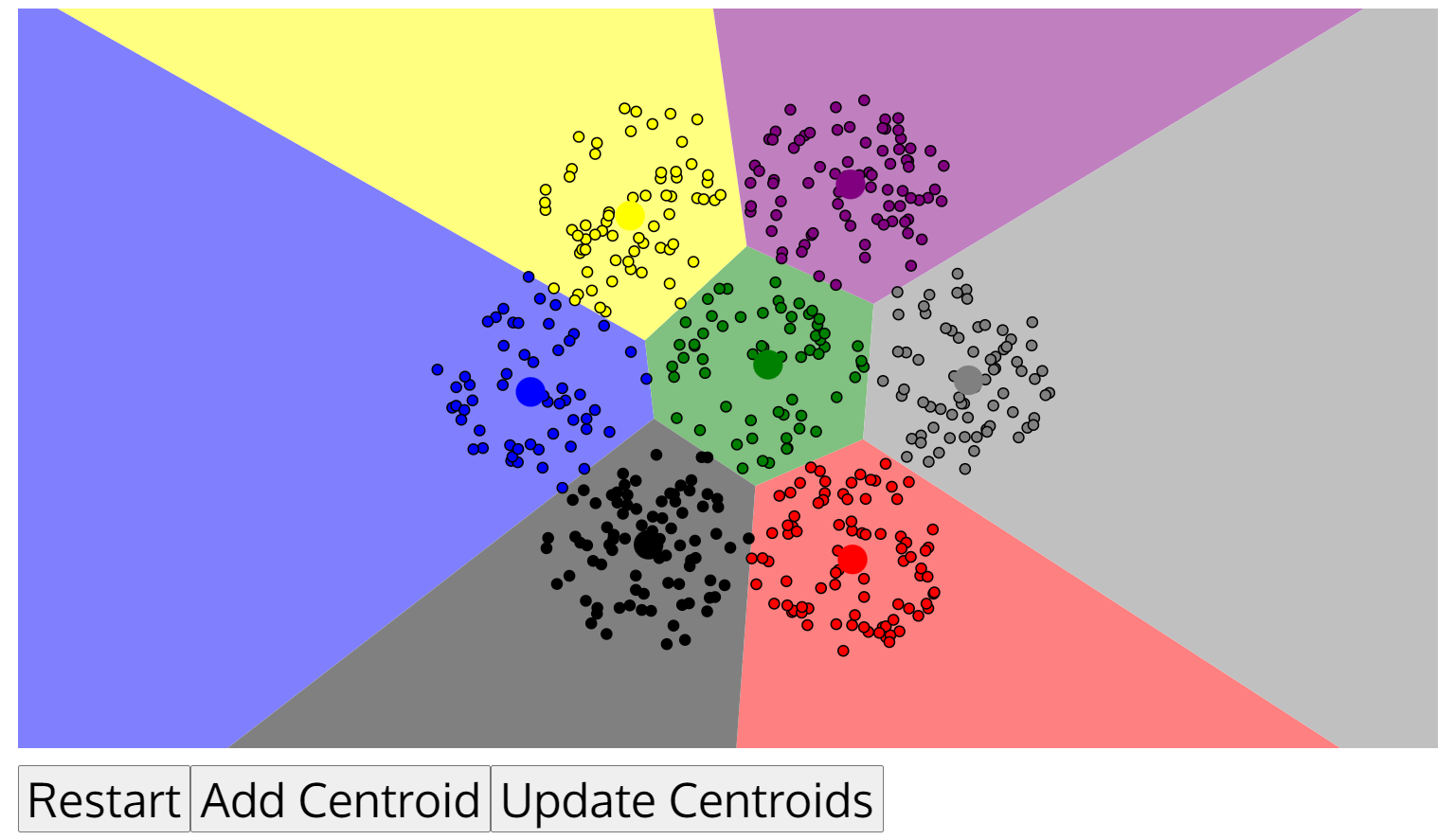
来源:https://www.naftaliharris.com/blog/visualizing-k-means-clustering/
不同初始点对最终聚类的效果有很大的影响,而初始点的选取又是随机的,那么该如何解决这个局部最优问题?
解决方法:多次尝试
进行多次随机初始化,计算代价函数,选择代价函数最小的一次作为最终聚类结果(是选择最好的一次结果,已经进行了多次重复聚类,而不是一开始就“预测”哪种方式初始化能得到最好的效果)。

数据集:kmeans
jupyter文件:python实现K-MEANS_优化1_代价函数应用
问题二:K值如何选择?聚成几类更合适?
K值是由用户所指定的,观察下图K值分别指定为3和5得到的两张聚类结果:

左边蓝色太稀疏了,明显再切分以下更合适。而右边的右上角蓝色和红色那么近,划分为一类更好。
那么问题来了?K值如何选取?得到一个最好的聚类效果。换句话说聚成几类更合适?
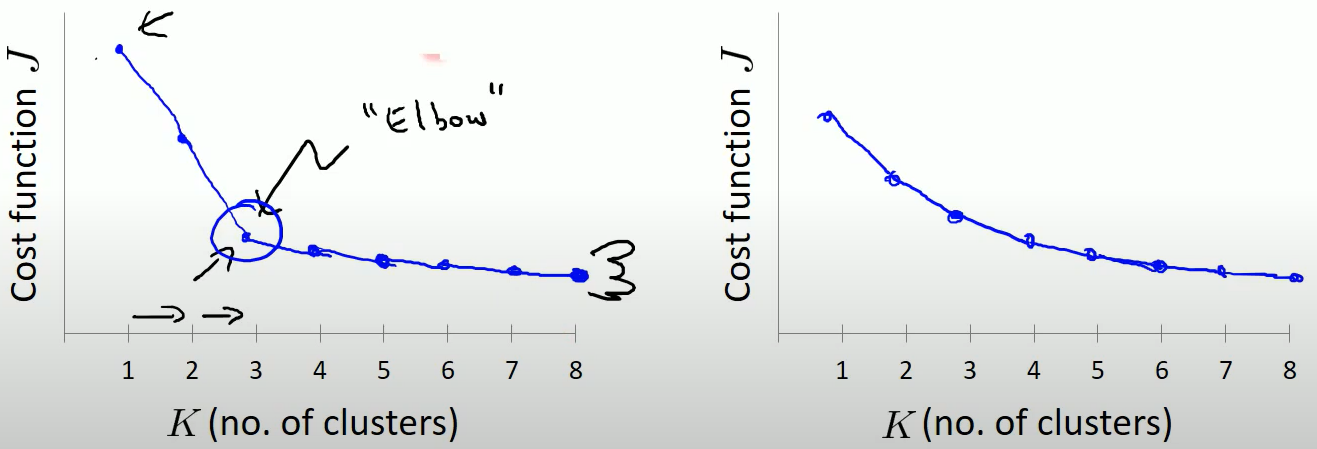
解决方法:肘部肘部法
上面问题一中通过多次尝试初始化k-means函数得到很多代价函数loss值,值的变化是越来越小的:
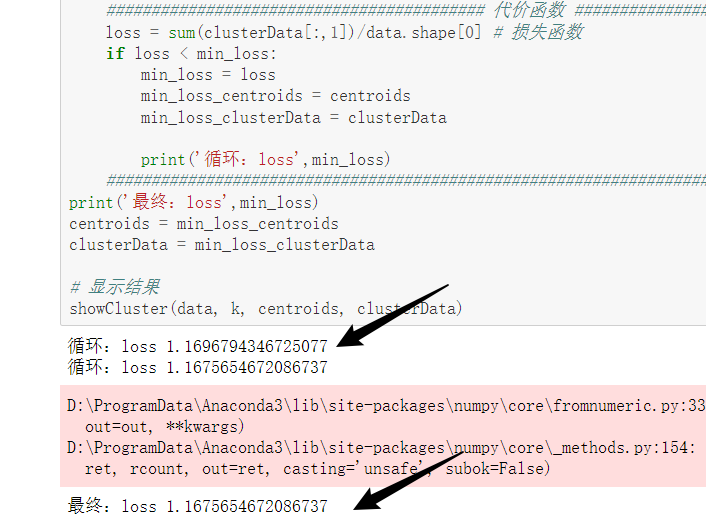
将每次loss值存起来画一个折线图,图中当K=3时会出现一个肘部,这是理想的聚类个数。

数据集:kmeans
jupyter文件:python实现K-MEANS_优化2_肘部法
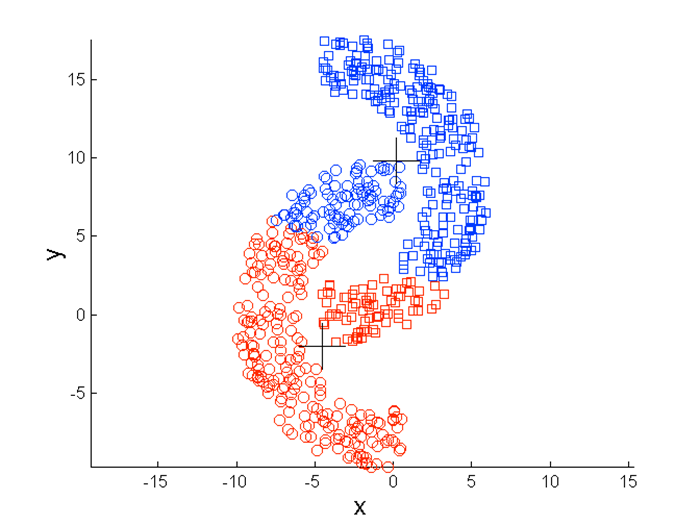
问题三:K均值的局限性:非圆形数据
使用上述的K-means算法会聚类成下面的样子:
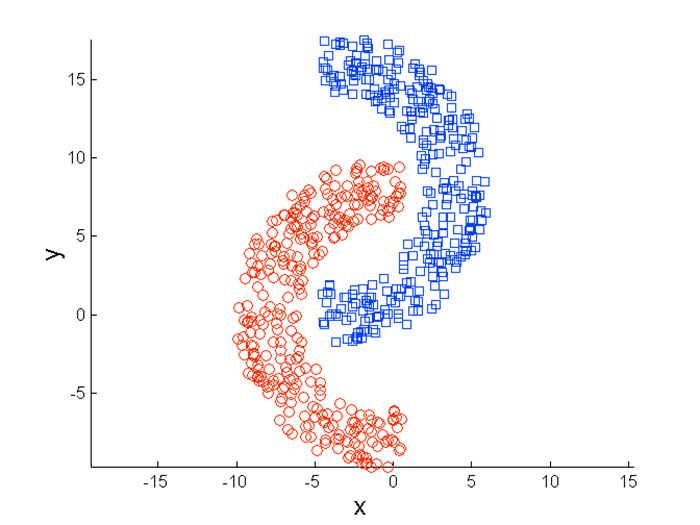
而实际应该下图才对:
聚类不理想的一种情况:

来源:https://www.naftaliharris.com/blog/visualizing-k-means-clustering/
因为K-means是按照距离聚类的,所以这种类型的数据就不太适用。
这种情况可以使用密度聚类法。——例如 DBSCAN 算法。
解决方法:基于密度聚类
具体算法介绍会开一篇新的文章。
问题四:数据比较大的时候,收敛会很慢
解决方法:使用 Mini-Batch
具体算法介绍会开一篇新的文章。
参考文献:
https://www.youtube.com/watch?v=Tf_iP0r8Cns&list=PLzw77domqr9s5upGq1vaCZK2dO1_0ir0p&index=60