本文已收录到:机器学习笔记 专题
- 机器学习的学习顺序、书籍和一些体会
- 朴素贝叶斯 – 根据男性特征分析女性是否嫁的问题
- 感知机 – 一种二分类线性分类模型,划分红豆和绿豆
- 逻辑斯谛回归 – 不那么生硬的划分红豆和绿豆
- 支持向量机:线性可分支持向量机与硬间隔最大化
- 支持向量机:线性可分支持向量机与软间隔最大化
- 利用集成方法提高基分类器分类性能
- 集成方法之Bagging装袋法:三个臭皮匠投票、少数服从多数
- 集成方法之Boosting提升方法:更像现实中实际学习的模型
- 决策树不仅可以做分类,还可以回归:回归树
- K-均值聚类算法,对无标签数据进行分组汇聚
- Apriori算法进行关联分析
- 使用FP-growth算法高效的挖掘海量数据中的频繁项集
- 维度是什么?数据降维方法,降维的用途
- 最广泛的降维算法:主成分分析(PCA)【原理讲解+代码】
- 人工神经网络(ANN)及BP算法原理
- 深度学习常用数据集、发展脉络和工具框架介绍
- 自编码器 – 经典的无监督学习神经网络、领会它的思想
- 卷积神经网络:卷积就是特征提取器,就是CBAPD
- 循环神经网络(RecurrentNN):有记忆的神经网络
什么是模式识别
下面有两组数字,哪组更容易记忆呢?
- 40, 27, 25, 36, 81, 57, 10, 73, 19, 68
- 50, 25, 76, 38, 19, 58, 29, 88, 44, 22, 11, 34, 17, 52, 26, 13, 40, 20
乍一看可能觉得第一行数字更容易记忆,毕竟更短。但仔细观察就会发现,第二组数字是有规律的:偶数后面是其二分之一,奇数后面是其三倍加一(这就是著名的hailstone sequence)。如果识别出了这一模式,第二组数据只需要记住这两个规则、第一个数字、以及序列长度。如果你的记忆能力超强,可以记住很长的随机数字序列,那你可能就不会去关心一组数字是否存在规律了。所以我们要对自编码器增加约束来强制它去探索数据中的模式。——这就是一种典型的模式识别。
常见的模式识别还有哪些呢?
- 背会《静夜思》很容易,但把这首诗打乱字序后再想记住,难度要大很多倍。大脑是通过一定规律将其总结的,这种规律就是我们所说的模式识别。
- 大脑天生擅长记住有意义的东西。而逻辑混乱的东西,记忆的难度是非常大的。我们阅读的书籍和文章通常都是有意义、有逻辑的,但仅凭这样记住的难度也很大,我们可以借助大脑喜欢模式化这个特质,将一本书或一篇文章拆解成一个个有意义的组块。
- 我们可以在一张很多人的合影中迅速识别出某个特定的人,即便照片上的那个人可能与现在看起来很不一样(比如照片是它的大学毕业照),我们仍能识别,这里我们运用的也是模式识别能力。
- 研究表明,专家棋手在扫视实战棋局5秒后,能准确再现20多个棋位,而新手仅能记住4到5个棋位,这也是因为专家在大脑中存储了大量有关棋局的模式。
简介
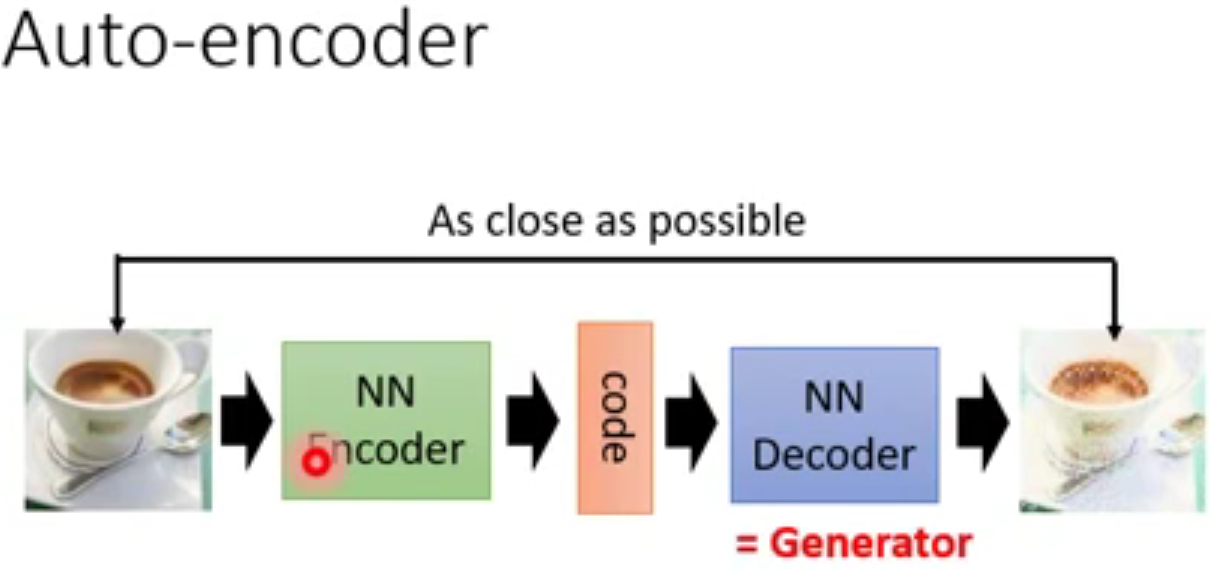
自编码器是一种能够通过无监督学习学到输入数据高效表示的人工神经网络。
自动编码器是深度学习的开创起始算法,但目前来说,自动编码机基本没用,但是思路很有意思,本篇文章主要给大家开开胃。


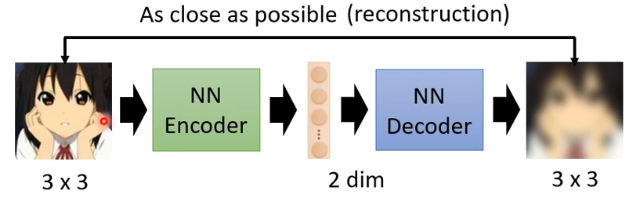
下图,编码器(encoder)将图像转化为向量,而解码器(decoder)将向量再重建成图像。

有什么用途?
- 例如左边的原始图像是一个特别长的数值串,就像前面模式识别中的第一组数字一样,我们希望通过模式识别将其像大脑一样“总结”为一组好记忆的数字。
- 还可以用来压缩图片去噪音。左边最原始的图像有很高维的数据,通过降维的方法压缩图像,间接达到去除噪音的目的。——输入数据的这一高效表示称为编码,其维度一般远小于输入数据,使得自编码器可用于降维。
- 更重要的是,自编码器可作为强大的特征检测器,应用于深度神经网络的预训练。
- 此外,自编码器还可以随机生成与训练数据类似的数据,这被称作生成模型。比如,可以用人脸图片训练一个自编码器,它可以生成新的图片。——生成对抗网络
用途之一:压缩输入的数据、提取特征、提高运算速度
现在我们先构架一个神经网络模型,这个模型是收集一张图片,接受这个图片后,神经网络给这个图片打码,最后再从打码的图片中还原。
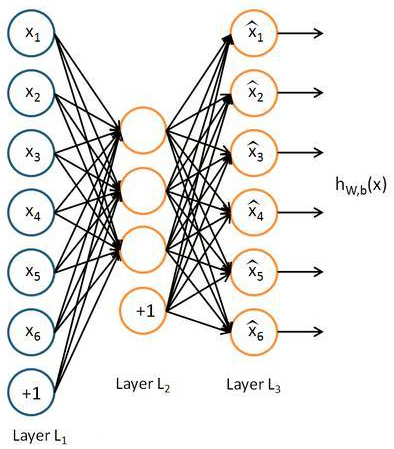
我们刚才上传给自编码模型的图片实质上是经过压缩以后再进行解压的一个过程。当压缩的时候,原有的图片的质量被缩减,解压的时候,用信息量小却包含了所有信息的文件来恢复出原来的图片。那么,为什么要这么做呢?当神经网络要输入大量的信息,比如高清图片的时候,输入的图像数量可以达到上千万,要神经网络直接从输入的数据量中进行学习,是一件非常费力不讨好的工作,因此我们就想,为什么不压缩一下呢?
提取出原图片中最具有代表性的信息,缩减输入中的信息量,然后在把缩减过后的信息放入到神经网络中学习,这样学习起来就变得轻松了,所以自编码就是能在这个时候发挥作用,从上图中的蓝色框中的X解压缩到黄色框中的x,然后用黄色的X和蓝色的X进行对比,得到预测误差,再进行反向传递,然后逐步的提高自编码的准确率,训练一段时间后将最右边的L3擦除,而在中间的黄色L2就是源数据的精髓——即重要特征。
可以从上面那个模型看出,从头到尾,我们只用到了这个输入的信息L1,并没有用到数据X所对应的数据标签,所以自编码是一种非监督学习,通常我们在使用自编码的时候通常只会使用自编码的前半部分,这个部分也叫作EnCoder编码器。
为什么可以被压缩?
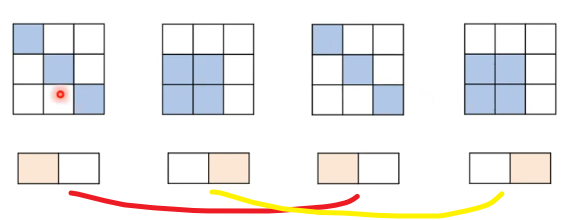
提出问题:原图像是3×3的,是9个数值,那么如何被压缩成2个数值然后还可以被还原成3×3的9个数值的呢?
答:对于图片中并不是所有的3×3的9个像素都是有效的,9个数值的变化都不会是随机的,反过来说,一个随机生成的9个数值也不太可能会组成一张有意义的图片出来,图片的9个数值之间一定是存在着模式的。——有点像上面模式识别中的两组数字的例子。
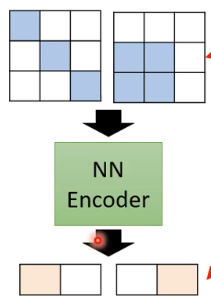
一张图片的9个数值(像素)可能只有下面的两种组合情形是一张有意义的图片。9个数字的其他组合情形出来的图片是毫无意义的。
上面的黄色框不就是把9个数值压缩到2个了吗。这就是编码器。
用途之二:压缩去噪音

用途之三:猜测字符
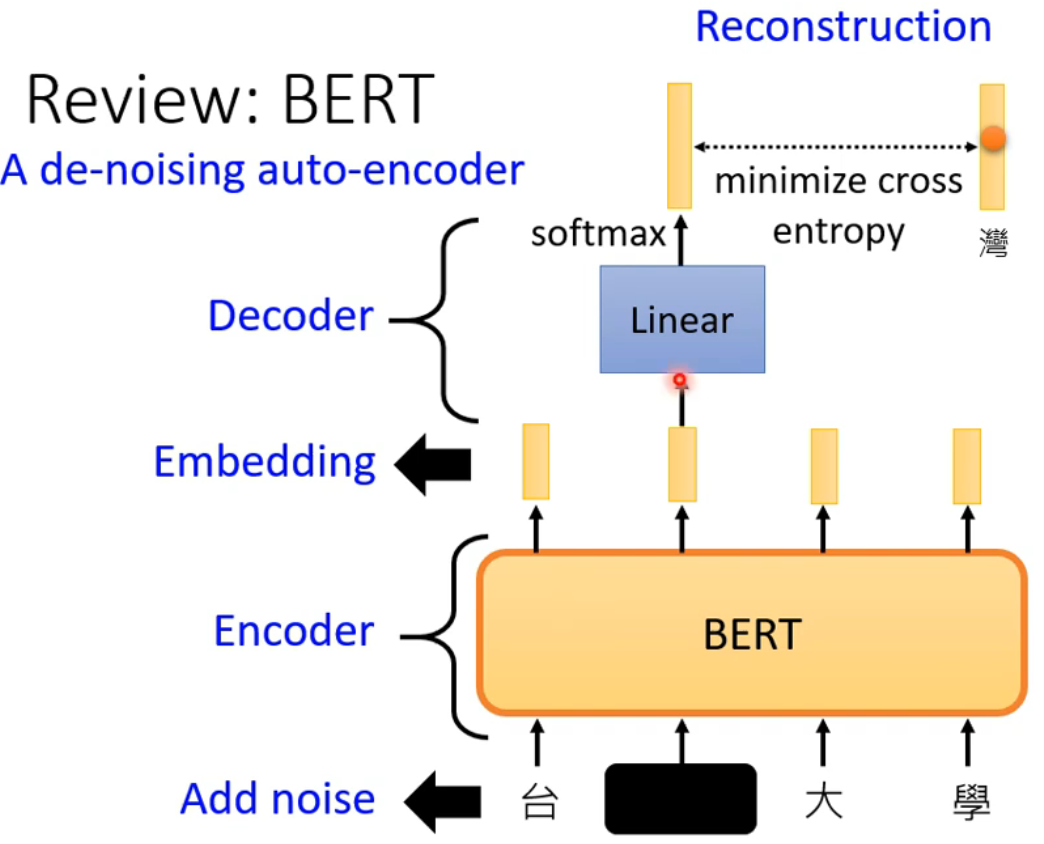
用途之四:在GAN中通过矩阵参数生成图片(类似生成器的功能)
这一部分在后面的GAN(生成对抗网络)部分讲解。
更多例子
在下图第一个例子中,我们输入一张图片,经过编码器生成向量,再通过解码器生成输出一张图片。这个向量有时候是我们不懂得什么意思的,他可能是表示出这张图像的纹理,风格等信息,但是这个向量本身很难被我们理解。
下面第二个例子是对声音做编码和解码,同样的输出的特征向量表示这段音频的内容,演说者(是谁的声音)。
第三个例子是一个句子,通过编码器可以得到语法和语义。

参考文献
https://blog.csdn.net/weixin_43198122/article/details/106134358
https://www.bilibili.com/video/BV1Wv411h7kN?p=75
https://blog.csdn.net/qq_26591517/article/details/80052589
写的很好,小白都能看懂一些
感谢支持