本文已收录到:机器学习笔记 专题
- 机器学习的学习顺序、书籍和一些体会
- 朴素贝叶斯 – 根据男性特征分析女性是否嫁的问题
- 感知机 – 一种二分类线性分类模型,划分红豆和绿豆
- 逻辑斯谛回归 – 不那么生硬的划分红豆和绿豆
- 支持向量机:线性可分支持向量机与硬间隔最大化
- 支持向量机:线性可分支持向量机与软间隔最大化
- 利用集成方法提高基分类器分类性能
- 集成方法之Bagging装袋法:三个臭皮匠投票、少数服从多数
- 集成方法之Boosting提升方法:更像现实中实际学习的模型
- 决策树不仅可以做分类,还可以回归:回归树
- K-均值聚类算法,对无标签数据进行分组汇聚
- Apriori算法进行关联分析
- 使用FP-growth算法高效的挖掘海量数据中的频繁项集
- 维度是什么?数据降维方法,降维的用途
- 最广泛的降维算法:主成分分析(PCA)【原理讲解+代码】
- 人工神经网络(ANN)及BP算法原理
- 深度学习常用数据集、发展脉络和工具框架介绍
- 自编码器 – 经典的无监督学习神经网络、领会它的思想
- 卷积神经网络:卷积就是特征提取器,就是CBAPD
- 循环神经网络(RecurrentNN):有记忆的神经网络
什么是维度?
一维度
- 数组中:形如 arr[5] = [1, 2, 3, 4, 5]。
- Series中:Series是一维数组,与Numpy中的一维array类似。
对于数组和Series来说,维度就是函数shape返回的结果,Series中函数shape中返回了几个数字,就是几维。
二维度:形如表
除外索引列,不分行列的叫一维(此时shape返回唯一的维度上的数据个数);有行列之分叫二维(shape返回行x列),也称为表。
表可以理解为Excel中的表一样,它最多只能是2维。因为3维的表没有用——人的大脑无法想象,也无法编辑。所以表必须像实体表格一样,至多有2维。
多维度:由多张表组成
多张表:当一个数组中存在2张3行4列的表时,shape返回的是(2, 3, 4)。
当数组中存在2组2张3行4列的表时,数据就是4维,shape返回(2, 2, 3, 4)。

一张表的维度:由特征数量决定
针对表来说,表是一个特征矩阵或者是DataFrame。它的维度是是样本的数量或特征的数量(可以理解为特征矩阵中列数量),一般无特别说明,指的都是特征的数量。除了索引之外,一个特征是一维,两个特征是二维,n个特征是n维。

一个图像的维度:由特征向量的数量决定
对图像来说,维度就是图像中特征向量的数量(即坐标轴数量)。
对于人类而言,我们无法想象出、也无法看到三维以上的坐标系。所以只有3维以下的数据,我们才能可视化画出来。
降维算法中的”降维“,指的是降低特征矩阵中特征的数量。
目的有两个:
- 让算法运算更快,效果更好
- 数据可视化
如何降维?降维技术有哪些?
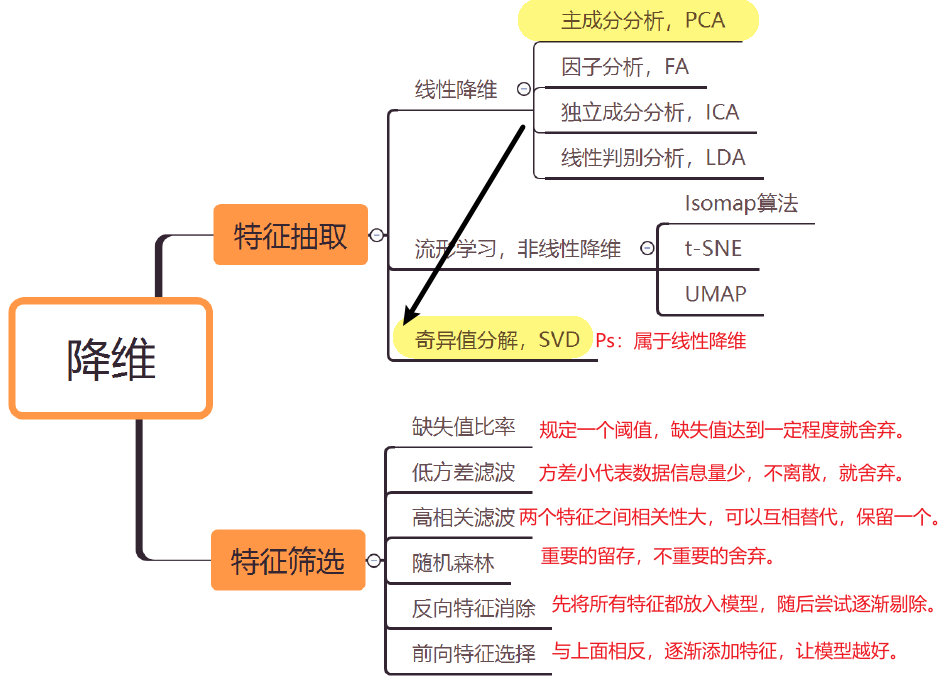
在降维技术中,PCA的应用是目前最为广泛的。在多元统计分析中,主成分分析(英语:Principal components analysis,PCA)是一种统计分析、简化数据集的方法。
后续会讲解奇异值分解SVD。
降低维度有哪些用途?
- 降低维度就是减少特征值。一个数据集中特征会有非常多,通过降低维度可以把关键特征提取,略去掉无效的特征,提高效率。
- 另一方面,有时候我们自己内部的数据有些字段、特征涉及到保密隐私,不方便公开出去可以经过降维后隐藏掉真实的意义,这样做也不会影响数据本身的价值,外界人士只要按照我们公开的特征建模即可,无需关心字段本身的含义。