本文已收录到:CMU数据库系统学习笔记 专题
课程小结
视频:https://www.bilibili.com/video/BV1Jq4y1B7ce/?spm_id_from=333.788
之前的课程中我们研究了存储引擎、缓存池和访问方法(哈希表与树索引)。本节开始研究算子。

研究四个议题:
- 算子算法。例如 排序、join等具体是怎么执行的。
- 用什么样的方案执行查询?
- 数据库在执行的时候在内存中的运行架构?
执行计划
执行计划是树形的:
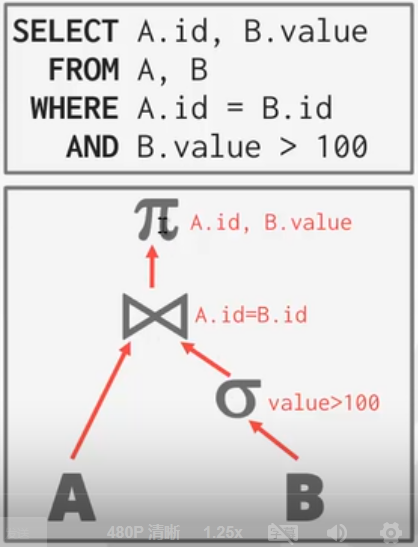
面向硬盘的数据库系统
需要注意的是本课程中的数据库系统是面向硬盘的,即假设硬盘存储巨量数据,不能指望这些面向硬盘的数据库系统所有的结果都保存在内存中。
本节主要讨论两种算子,即排序和聚集。
为什么要排序?
因为数据库系统查询的返回值的顺序是不定的。如果不加 order by 就不要指望他有任何顺序,这是完全无序的。所以需要排序。
不仅仅是 order by 需要排序,像 DISTINCE 、GROUP BY 指令也需要有排序这个需求。
DISTINCE 指令的主要工作是先排序,然后去重。
GROUP BY 是分组聚合指令,需要把相同的类型聚集在一起,更需要用到排序操作。
排序算法
可以使用最常见的内部排序算法,冒泡排序、快速排序、归并排序等。前提是这些数据都能放在内存中。如果数据非常大呢?
外部归并排序
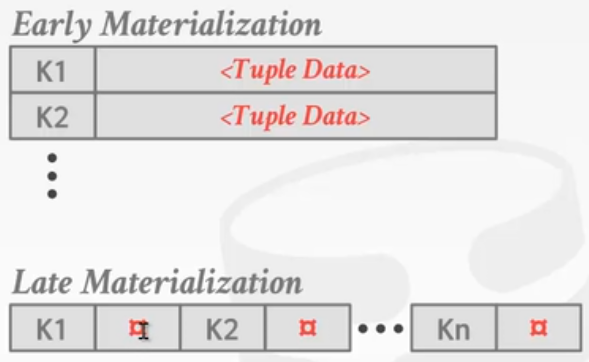
Early Materialization(早物化),意思是说key好比年龄,tuple data好比这个人的其他信息例如姓名、学号、班级等等信息,这些信息不是按年龄排序的key,但是我们也让这些信息跟随着key一同排序。
Late Materialization(晚物化):考虑到有些行数据的tuple data过多,一同排序比较影响效率,就只让key参与排序。
两路归并排序:

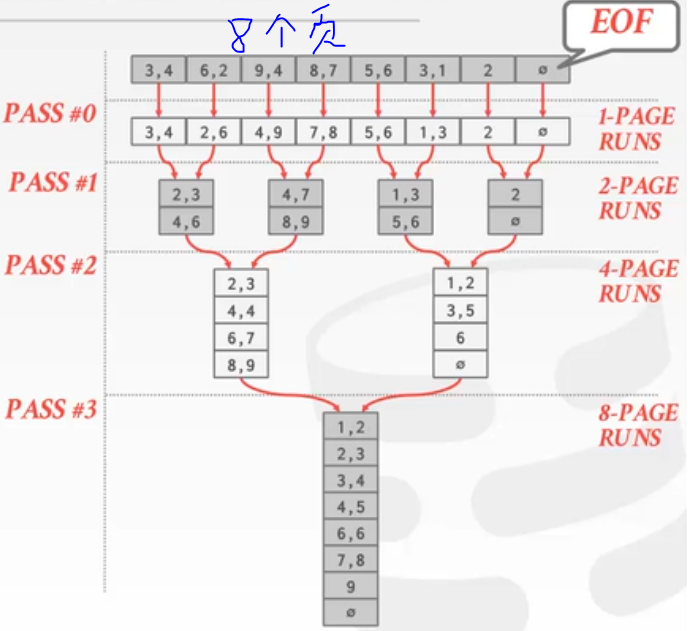
两路体现的是每次读取两个页,如果是三度就是每次读取三个页,三个页做merge操作。使用这种算法我们内存中只需要三个页就可以完成。
在MySQL中一个页才16kb,现在服务器的内存远不止这么少。改进优化:
- 预读取,上一个page读取在内存中做排序的过程中,可以先预读取下一页:
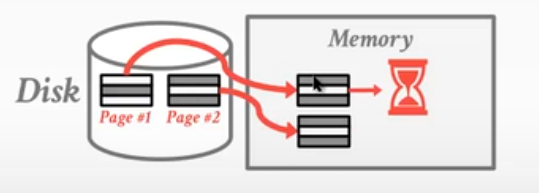
- 可以做N路归并排序,N代表页数、B代表缓存池。缓存池的大小越大,排序的轮数越少。
提醒:B+Tree 的叶子结点是已经排好序了,如果一个表中的字段他有主键了,并且是索引,那就说明这个字段在 B+Tree 中的叶子结点已经排好序了,直接用就行。——前面的聚簇讲过索引,可回顾——点击去ctrl + f搜索“聚簇”即可找到。
聚集算法
排序聚集:利用排序去做去重
先筛选,把 grade(等级)是B和C的sid和cid字段 筛选出来,然后做投影去除其他无用列,最后排序后删除(Remove Columns)重复的cid。

这样做可以通过排序来实现去重的目的。但是有些 DISTINCE 和 GROUP BY 操作是想涉及排序的,例如 DISTINCE 的目的仅仅是想去重,这时候如果我们非要进行排序就浪费了。下面使用哈希聚集可以解决这个问题。
外部的哈希聚集
先给我们要聚集的字段以它为key做一个哈希表。给他们映射到磁盘上。其核心思想是利用哈希碰撞。
把碰撞的key放在同一个桶里。接下来需要 REHASH。因为相同key的因为碰撞放在了同一个桶中,但是还可能有的key就是因为本身hash函数导致的碰撞被放在了同一个桶中。——这不是我们想看到的。

REHASH(再次hash):将桶里的key进行第2次哈希,因为相同的key得到的hash一定也是相同的,所以可以把key本身不同导致的因为hash缺陷而误放在一个桶的key给筛选出来,剩下的在一个桶里的一定就是key相同的key了。
上面的外部哈希聚集是单纯解决去重问题的,那如果是聚集起来是为了计算呢?例如下面的SQL是为了计算平均值:

解决方法就是记录中间结果,二次hash table中再增加一列value列, value 记录下 (个数, 总和),如果是平均值就保存个数和总和;如果是min就保存最低值;如果是sum就保存总和 … …最后再根据计算函数进行计算即可。

这样我们就解决了聚集计算(GROUP BY)的问题。