本文已收录到:CMU数据库系统学习笔记 专题
视频、课件
视频:https://www.bilibili.com/video/BV1Z3411x7aS?spm_id_from=333.880.my_history.page.click
为什么要关心并行执行?
前面的第一部分我们只研究了单线程情况下的执行问题,但是并行执行却是我们不得不考虑的问题:
提升性能:
- 提升吞吐量
- 降低延迟
增强的响应性和可用性。
潜在地降低总拥有成本(TCO)。什么是TCO:简单的来说就是衡量一台机器使用寿命、价格、处理总数据量、电费这些成本后得出来的参数。可以衡量机器的性价比。
并行与分布式
分布式数据库:数据库分布在多个资源中。分布式有很多节点,分布式的数据库节点之间非常远。访客只要连接上一个节点就可以访问多个节点,好像是在单个节点一样。单节点数据库和分布式数据库,查询的结果是一样的。
并行数据库:资源都是在一块的。多线程在同个机器高速的查询。线程之间通信是非常可靠的(通过内存是简单可靠的)。
处理模型、线程模型
多用户,执行计划如何处理的。我们以worker作为一个抽象的“在数据库中工作的人”。
关于进程与线程的区别是操作系统课程中研究过的,可以移步 –> 清华大学操作系统课程笔记:进程和线程
每个worker一个进程(process)
为每个worker分配一个进程procecss,进程之间共享一段内存空间用于进程通信。以下三种数据库采用进程模型,每个worker一个进程:

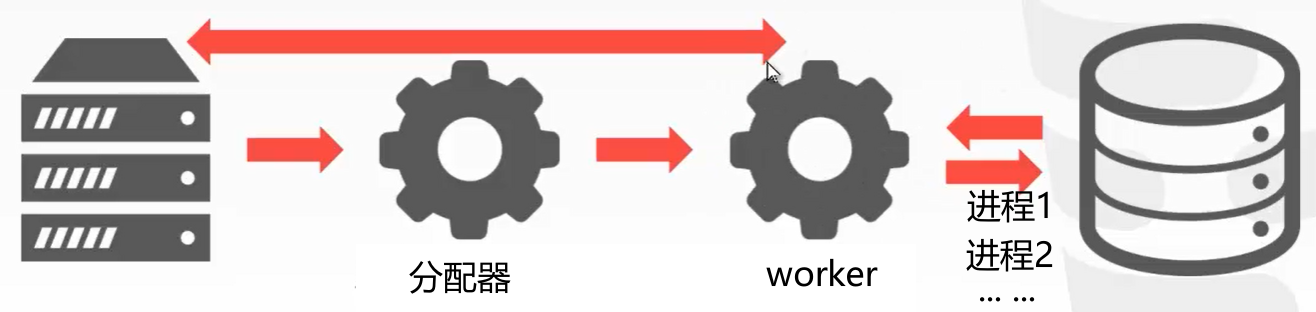
如果并发量太大,每个worker一个进程,这样进程会非常多。下一步我们考虑建立一个进程池用于分配。
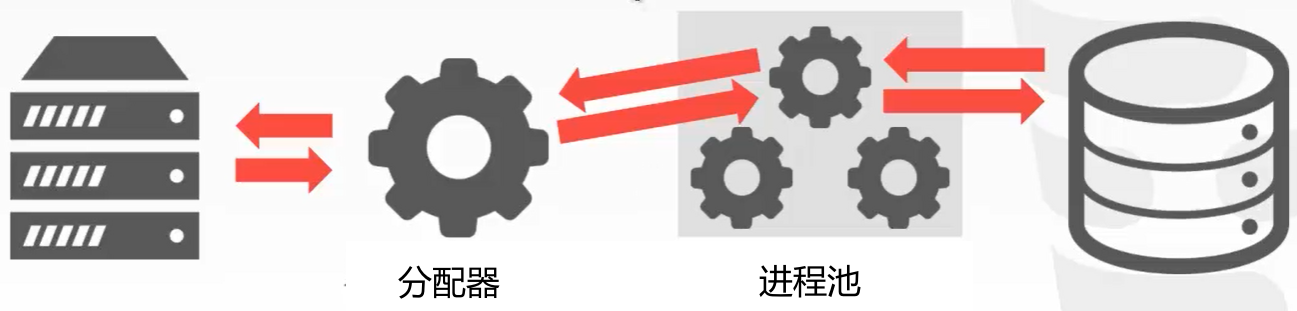
进程池
以下数据库采取进程池:

每个worker一个线程(thread)
在此之前,不同的操作系统提供的线程API不同,甚至有的不提供线程API。使用线程就很麻烦。
在此之后的发展过程,操作系统逐渐统一了线程相关的API接口供应用程序使用。所以后来的数据库系统也逐渐采用线程模型来运行。

MySQL仅仅只有一个进程在运行。(上面还有一个,不知道为什么?)但至少不是多进程了。
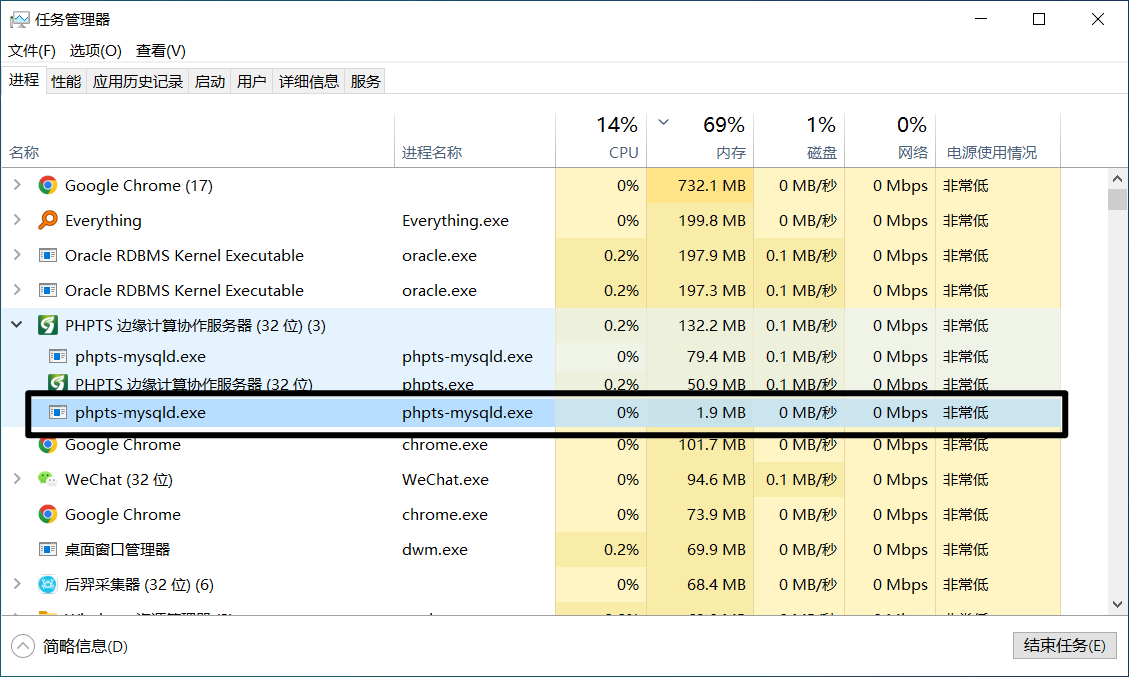
优点:线程之前的调用由DBMS自行负责。同一个进程之下的所有线程都是共享内存的,通信很方便。
缺点:一个线程崩溃会导致整个进程崩溃。

很多数据库用来多线程,但并不是每个SQL语句之内都是并发的。是多个SQL语句之间并发执行的。单条语句并发运行我们后面讨论。
针对每个执行计划该如何调度?
针对每个执行计划,数据库系统需要知道在哪执行、什么时候执行、怎么执行。
- 一个执行计划需要切分成多少任务?
- 每个任务需要占用多少CPU资源?
- 哪些CPU资源执行哪些任务?
- 单个任务结果输出到哪里?子任务如何聚集?
尽量用自己的数据库来控制这些事情,不要用操作系统,他很傻。
两种并发执行
多SQL语句之间并发执行
多个不同用户执行查询SQL,他们之间并发执行。
如果并发查询之间是只读的,那么他们之间的冲突很小。如果并发查询是更新的话,这就是并发控制。——这是一大类问题,在事务中我们讨论。
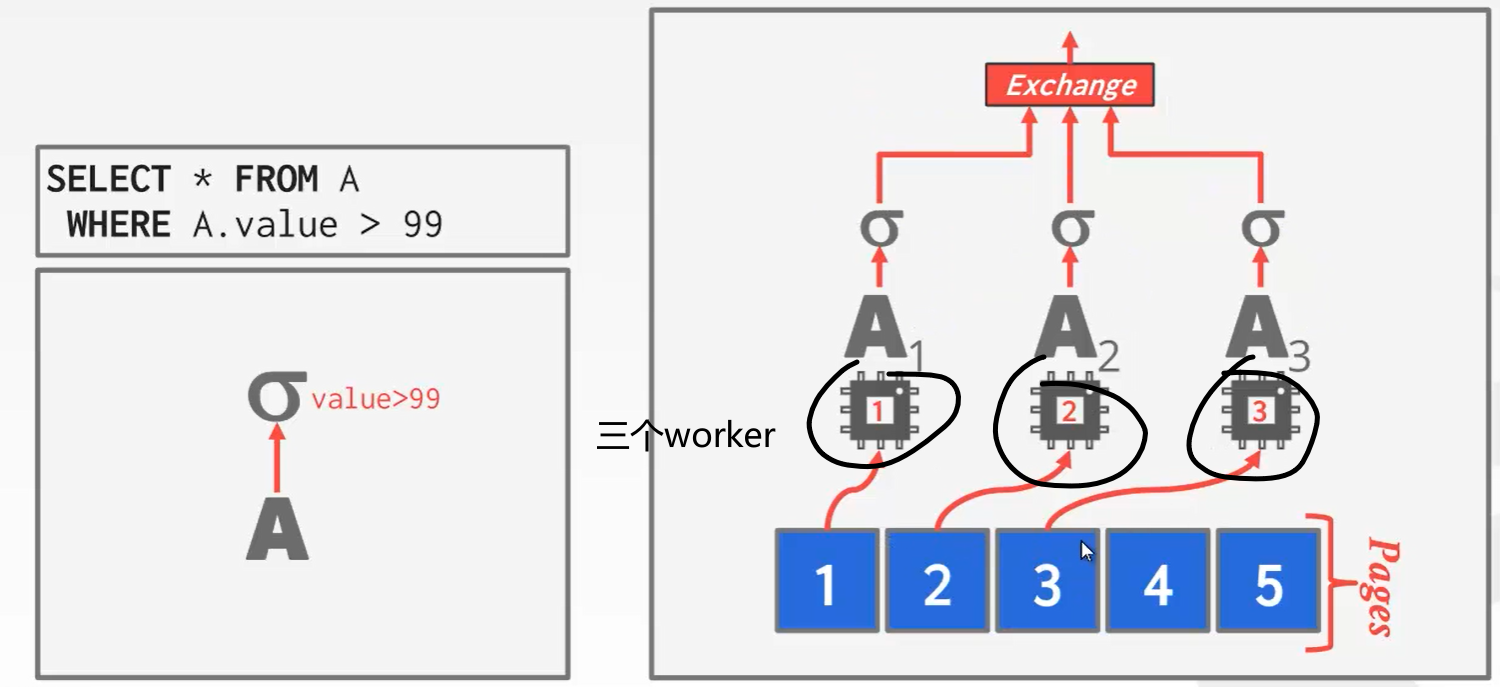
单个执行查询SQL中如何并发执行
可以提升单个查询的性能。思想很像生产者消费者问题。 –> 去回顾下生产者消费者问题
成熟的数据库每个算子都有并发版本。并发算子的实现有两大思路,一个是把数据切分给不同的worker处理;另一个是将算子分配给每个worker处理,有点像流式处理。
举个例子:并发版本的hash join。
第一个worker执行完之后去第4个page:
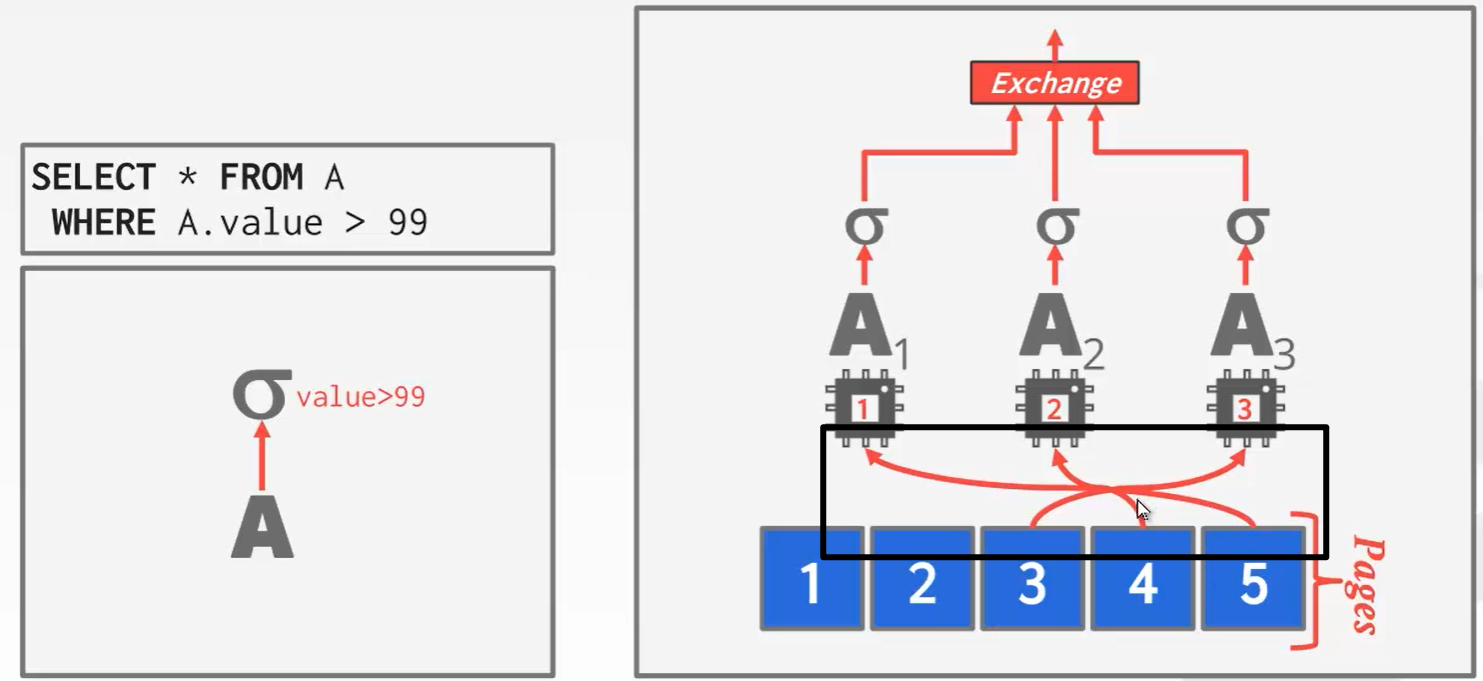
最终由Exchange进行汇聚,并发的调用下面的worker。
exchange算子有三大类:汇聚、分发、重分配

执行时候如何做并发机制
举例:

如果垂直切分,流式处理。相当于把不同的算子分配给worker流式处理。

混合模式:两种并发都有,我们来看下例子:
将算子切分交给不同的worker处理,同时将pages也划分成不同的worker来处理。是一种混合并发模式。

磁盘I/O并发优化
前面我们变着法的研究数据在内存中如何优化,如何并发使其处理更快。但是数据库系统的瓶颈基本是磁盘的性能,甚至说,如果我们一会儿读取磁盘某一部分,一会儿又另一部分,这种离散的对磁盘读取,很可能还是适得其反。下面来研究磁盘I/O如何并发优化。
跨多个存储设备拆分DBMS:
- 一个数据库划分存储在多个磁盘上。这样可以在磁盘层面分离出DBMS,在磁盘的层面上多并发。有点像RAID。
- 一个数据库存在一个磁盘上
- 一个表存在一个磁盘
- 一个表切分在不同的磁盘上
其实本质都是将数据切分开。
多盘并发、磁盘阵列
在操作系统、文件系统、RAID(磁盘阵列)层面上做优化。

优点是RAID0磁盘阵列可以加速磁盘速度。缺点是减少磁盘利用度。关于RAID可参考 –> https://www.ixigua.com/6764516794855064071
数据库分区
把单个表分区。
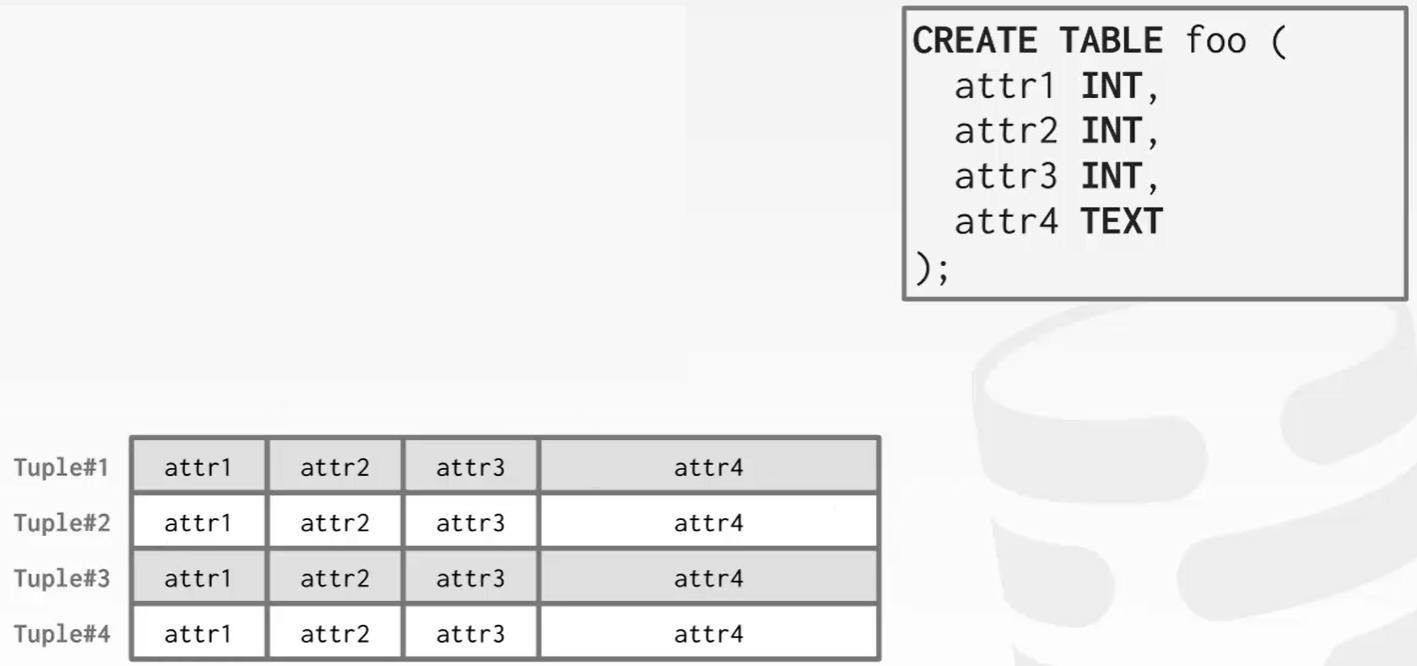
把这个表分成两部分,将其存放在不同的磁盘上,利用磁盘并行优化。
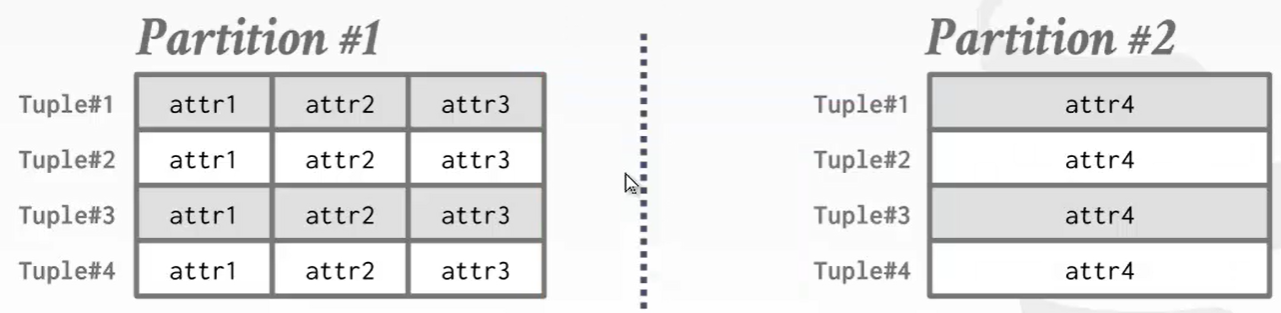
另外,我们发现最后一个字段非常的大,所以又长又冷的数据我们尽量拆分开。如果DBMS不支持表分区你也要尽量在数据库设计的时候拆分成两张表。
如果数据库系统支持的话,可以使用分区键(partitioning key)来实现表分区。
目前这种表分区技术很多数据库都已经实现了。
题外话:最初的分布式数据库就从分区表来的,所以数据库机器之间是不是也可以区分。——分布式数据库的来历