本文已收录到:CMU数据库系统学习笔记 专题
视频课程(中字幕)、课件
数据库存储(上)
数据库存储(下)
课件:
引言
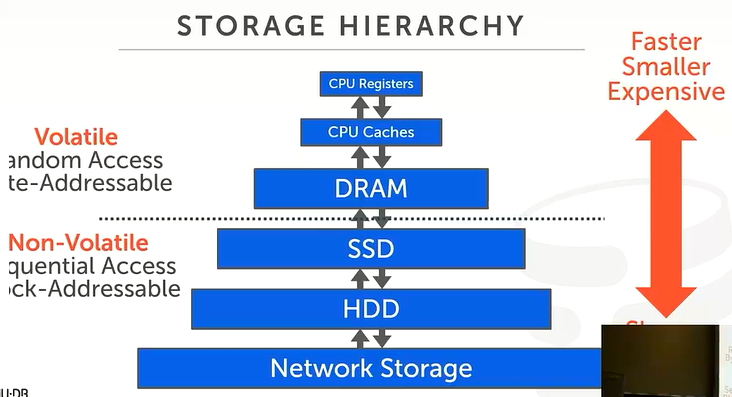
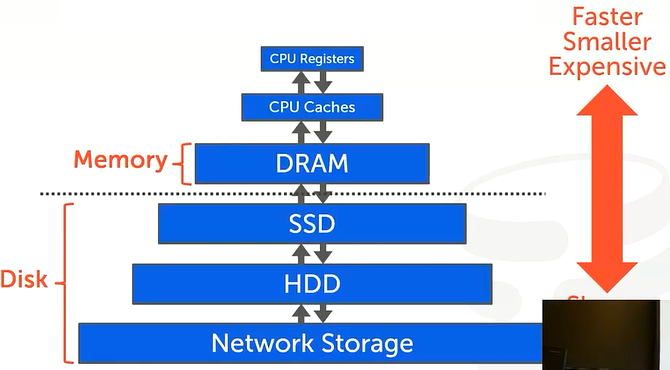
我们已做前提假设,本课程所研究的数据库是面向磁盘式的。关于计算机存储知识例如易失性/非易失性、存储等级等假设已经了解,关于这一部分内容是存储技术和计算机组成原理中的。
为什么不使用操作系统自带的磁盘管理模块?
操作系统并不知道我们的数据库系统在做什么,操作系统只看到了要将这些page进行换入和换出,操作系统只能看到对这些页面进行的写入和读取操作,他无法理解高级的语义,要查询什么,要去读取哪些数据。
操作系统的磁盘管理模块并没有、也不可能会有 DBMS 中的领域知识,因此 DBMS 比 操作系统拥有更多、更充分的知识来决定数据移动的时机和数量,具体包括:
- 将 dirty pages 按正确地顺序写到磁盘
- 根据具体情况预获取数据(预存数据)
- 定制化缓存置换(buffer replacement)策略
- 线程/进程调度
如果我们想要通过mmap来将文件内容保存到某个进程的地址空间,我们无须无需自己绞尽脑汁的在数据库系统中来搞,只需要交给操作系统就行了,无须关心读取写入文件背后的任何事情。
使用操作系统的mmap,如果是读取文件还好说。但如果是写入文件就会出现问题,操作系统并不知道某些pages必须要在其他pages执行之前先从内存刷到磁盘上——日志和并发控制会涉及到。但是可以给操作系统一些“提示”来解决这个问题。
- madvise: 告诉操作系统您希望如何读取某些pages。
- mlock: 告诉操作系统内存中哪些范围的pages不能被调出(阻止pages被回收)。
- msync: 告诉操作系统将哪些内存范围中的pages刷新到磁盘。
实际上并没有多少使用操作系统mmap的数据库系统,下列数据库使用了操作系统的mmap:

上述的数据库使用mmap,但仍然需要做一些额外的事情来防止操作系统做出错误的事情。
下列是部分使用mmap的数据库系统,有些会提供特定的设定才会启用mmap,在默认情况下不会使用mmap。

实际上很多系统都是不使用mmap的,他们会使用一些buffer池之类的技术:
主流数据库MySQL、DB2、Oracle、SQL server等都没有使用mmap。
总之,老师认为数据库系统使用mmap是很糟糕的,因为数据库总是很确定的知道查询要做什么,知道工作负载是怎么样的,数据库系统可以作出最佳选择,但是操作系统什么都不知道,他只知道读取、写入文件。
再后面我们会讨论如果不使用mmap,我们也会使用预存、更好的替换策略、更好的调度之类的东西。
总之,操作系统并不是你的朋友,你不能依赖他,我们应该尽可能尝试避开他。他可能会做出对我们数据库系统有害的决策。操作系统既是朋友也是敌人。

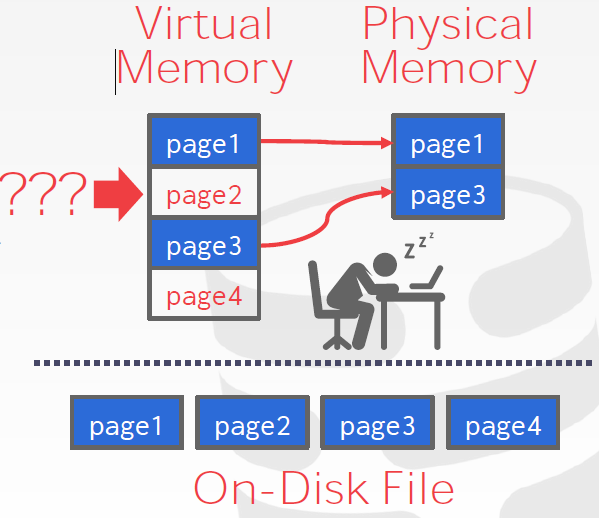
这里的pages跟磁盘中的块概念差不多。本节会讨论磁盘上的数据文件。这里很想操作系统相关课程虚拟内存的内容。
问题一:如何表示磁盘上文件中的数据?
数据库就是磁盘上的一堆文件。sqlite的数据库就是一个db文件,但其他大部分数据库会将这些东西分为多个文件保存。
操作系统并不知道这个db文件是什么,操作系统只知道这是一堆二进制数据。这些文件的格式通常不是通用的,每个DBMS的数据库文件格式都是专属于某个DBMS的。
这些数据库文件通常会存放在操作系统提供给我们的文件系统中,我们基于操作系统文件管理的API来对文件进行读写。
在1980年代,人们尝试在裸存储设备(没有操作系统)上构建自定义文件系统的数据库系统,在某些高端企业级数据库系统还会自己有一套文件管理系统,并不需要操作系统的文件系统提供接口来读写数据库文件,是裸体运行在一块磁盘上的。但近些年新的DBMS往往不用裸体运行这种方式,因为这种方式开发DBMS会把大量时间用在文件系统上,也大大降低了可移植性,文件系统这显然不是数据库的研究重点。
本节所要构建的是存储管理器,或者叫存储引擎。他是我们数据库系统中的一个组件,负责维护在磁盘上的数据库文件。在某些高端数据库系统,他们在文件系统之上还有个shim层,会允许数据库去做一些磁盘调度,例如可以通过一堆线程来对彼此邻近的区块进行写入,可以将这些块合并,作为一次写入请求。但是大部分的数据库系统都没有shim层,我们课程实验也不涉及到shim内容,这是高级课程中的。
问:放入磁盘上的单个文件有大小限制,请问放在内存中的文件是否有大小限制?
答:如果是虚拟内存则没有限制,但操作系统会限制物理内存大小,
问:操作系统是否会对进程创建文件有数量限制?
答: 并不会限制创建文件的数量,但是通常在打开所创建的文件的时候会有句柄数的限制。
如何在page上组织数据库?
数据库page:
- Page是一个固定大小的数据块,一个page能够保存任何东西,可以保存数据库里面的tuple,也可以保存元数据、索引、日志。
- 现在有些数据库要求page是self-contained的,也就是说该表的内容的元数据存储在一个page中,该表内容的tuple存储在另一个page中,如果数据库schema布局的那个page灭失就不能解释这个表内容的元数据了(表的列意义、列属性、列类型等)。所以现在某些数据库系统例如Oracle就需要元数据的page和内容数据的page一同保存在同一个page中。
- 另外大多数系统不会在page中混合使用不同类型的数据。
- 每个page都会被赋予一个唯一的内容标识符,数据库系统会生成page ID。考虑到有时候会将数据库系统的page移动至另一个磁盘、压缩磁盘等操作,所以系统还有一个indirection层,记录了page ID和位置信息,这样indirection就会告诉我们page ID对应在什么位置,以保证我们移动磁盘时候page ID不会发生改变。
硬件page、操作系统page和数据库page 需要分清楚:
- 硬件Page:通常大小为 4KB
- 操作系统Page: 通常大小为 4KB
- 数据库Page:(1-16KB)


- 每种数据库的page都不一定相同,最低是512bytes(512字节)。有些高级的数据库系统允许数据库管理员设定page的大小。
- 我们主要关心的是hardware page,他是我们执行原子写入存储设备的最底层的东西。如果我们写入8Kb的数据,一个hardware page是4Kb,分成两页也能写入,但是这样虽然都写入了,但是这两段数据并不连续,导致写入的16kb数据并不具备原子性,失败后不会回滚。
如何将这些page存储在文件中?
不同 DBMS 管理 pages 的方式不同,主要分为以下几种:
- 堆文件组织
- 连续/分类文件组织
- hash文件组织
堆文件组织
堆文件组织:
- 它是最简单,最基础的组织类型。它适用于数据块。在堆文件组织中,记录将插入文件的末尾。插入记录时,不需要对记录进行排序和排序。
- 当数据块已满时,新记录将存储在其他某个块中。这个新数据块不必是下一个数据块,但是它可以选择内存中的任何数据块来存储新记录。堆文件也称为无序文件。
- 在文件中,每个记录都有唯一的ID,并且文件中的每个页面都具有相同的大小。DBMS负责存储和管理新记录。
- heap file 指的是一个无序的 pages 集合,pages 管理模块需要记录哪些 pages 已经被使用,而哪些 pages 尚未被使用。那么具体如何来记录和管理呢?主要有以下两种方法 Linked List 和 Page Directory。
方法过程
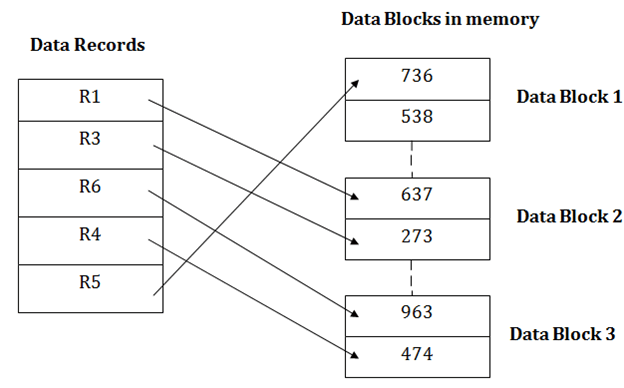
插入新记录
假设我们在堆中有五个记录R1,R3,R6,R4和R5,并且我们想在堆中插入新记录R2。如果数据块3已满,那么它将被插入DBMS选择的任何数据库中,比方说数据块1。
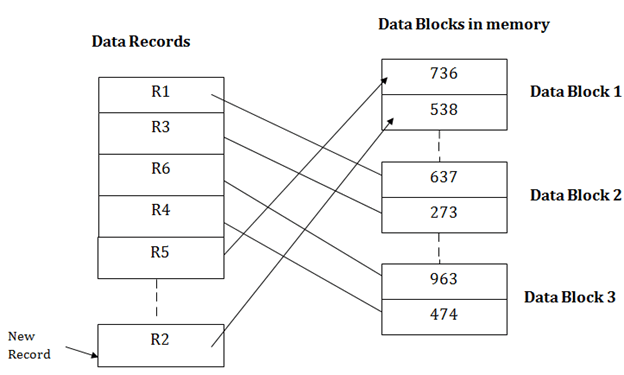
搜索
如果要搜索,更新或删除堆文件组织中的数据,则需要遍历文件的开头直到获得请求的记录为止。如果数据库非常大,则由于没有记录的排序或排序,因此搜索,更新或删除记录将非常耗时。在堆文件组织中,我们需要检查所有数据,直到获得请求的记录。
优点和缺点
堆文件组织的优点
- 这是用于批量插入的非常好的文件组织方法。如果一次需要将大量数据加载到数据库中,则此方法最适合。
- 对于小型数据库,记录的获取和检索比顺序记录要快。
堆文件组织的缺点
- 对于大型数据库,此方法效率不高,因为它需要花费时间来搜索或修改记录。
- 对于大型数据库,此方法效率低下。

使用链表?这也可以,但确实是个愚蠢的方式。
我们考虑下 page Directory。
不得不说,这里有点像操作系统中的页表了。
需要提供这些接口
实现数据结构
在这些page中我们可以用不同的数据结构来实现/表示他们。
首先我们来说链表这种方式,这是一种愚蠢的方式,实际上也没有人使用这种方式,随后我们会将page目录这种形式。
Linked List方法(基本不用)
Header会有两个指针分别是 Free Page List和Data Page List。

改进:使用双向链表
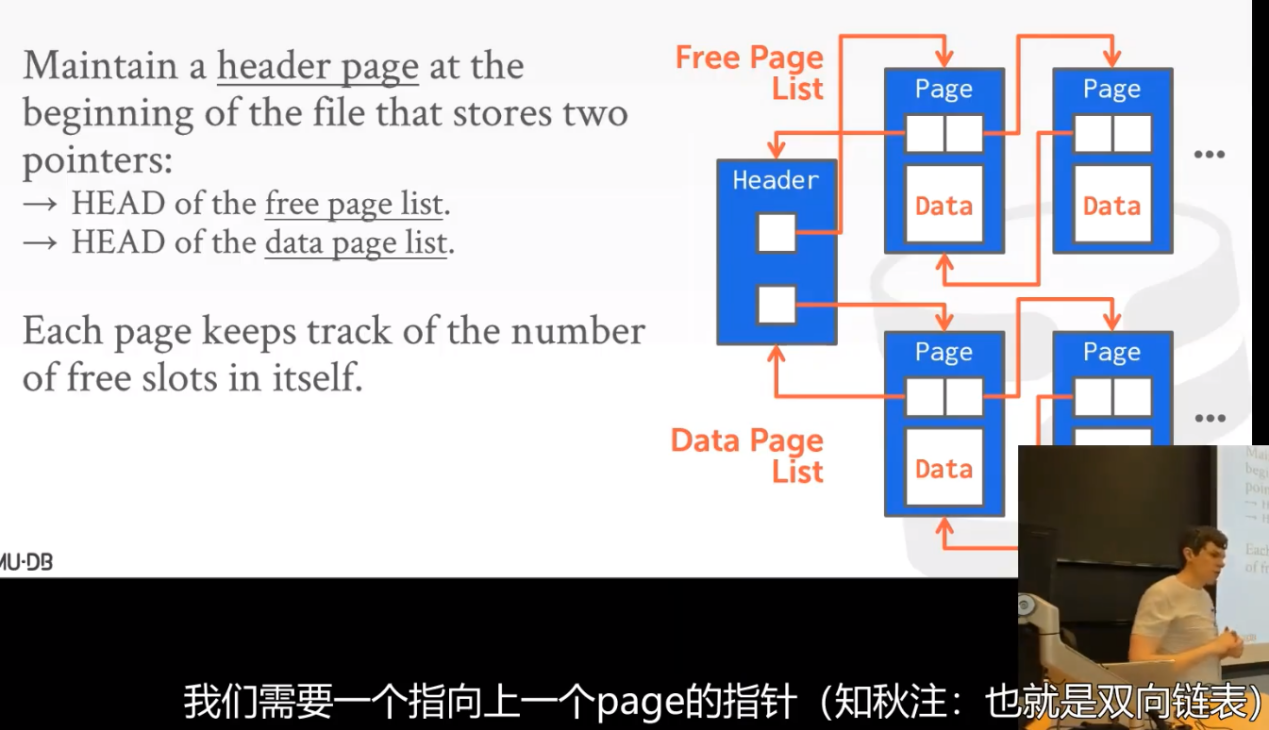
卧槽,这跟操作系统中经常用到的双向链表不是一样的吗。什么proc,调度队列什么的。
接下来,我们想改进下这个双向链表:使用directory
Page Directory方法

维护

课堂提问:为什么有的DBMS选择更大的page呢?
答:一个page设定大的话,就可以通过更少的page id来保存更多的数据。如果page设定过小的话,就会有很多的page id, ![]()
Page header
每一个page都有 header。


在header 中通常包含以下信息:
- Page 大小
- Checksum
- checksum在故障恢复中有用,
 ,在第一个page的header里面会放一个checksum,
,在第一个page的header里面会放一个checksum, 
- checksum在故障恢复中有用,
当从故障中恢复后,会查看最后一个page中所计算出的checksum,发现和预定的值不匹配是因为数据没有写进去,于是就报错。——这一部分在后面的日志中讨论。
- DBMS 版本
- Transaction Visibility
- Compression Information
在data 中记录着真正存储的数据,在一个page中我们通过两种不同方式来表示数据:
- Tuple-oriented:记录数据本身
- Log-structured:记录数据的操作日志
tuple storage——Strawman Idea(基本不用)
Strawman Idea: 在 header 中记录 tuple 的个数,然后不断的往下 append 即可,如下图所示:

这种方法有明显的两个缺点:
- 一旦出现删除操作,因为是零散的腾出空位,导致每次插入就需要遍历一遍,寻找空位,否则就会出现空间浪费。
- 无法处理变长的数据记录(tuple)。
为了解决这两个问题,就产生了 slotted pages。
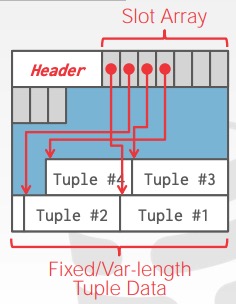
slotted pages——有点像操作系统里的页表(采用)
slotted pages含有Header和Tuple。如下图所示,header 中的 slot array 记录每个 slot 的信息,如大小、位移等。下面tuple的长度不必限制都是等长的,完全可以变长。

所以 ![]() 根据偏移量找到这个tuple。
根据偏移量找到这个tuple。
新增记录时:在 slot array 中新增一条记录,记录着改记录的入口地址,slot array 与 data 从 page 的两端向中间生长,二者相遇时,就认为这个 page 已经满了。
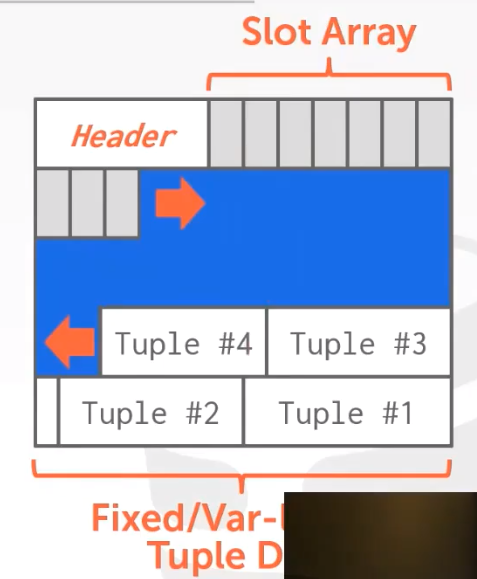
从前往后对slot数组填充,从后往前对数据填充。优点:处理定长和变长 tuple 数据都游刃有余。
删除记录时:假设删除 tuple #3,可以将 slot array 中的第三条记录删除,并将 tuple #4 及其以后的数据都都向下移动,填补 tuple #3 的空位。而这些细节对于 page 的使用者来说是透明的
更改时:
![]()
![]()
目前大部分 DBMS 都采用这种结构的 pages。

上图解释:这不就相当于基地址和偏移地址吗。page id加offset或者slot来表示。


下面我们来看下page id 和slot:
顺序文件组织
tuple layout:记录数据本身
上节讨论了 page 的 结构可以分成 header 与 data 两部分,而 data 部分又分为 tuple-oriented 和 log structured 两种。
tuple-oriented
那么在 tuple-oriented 的 布局 中,DMBS 如何存储 tuple 本身呢?
tuple 中还可以分为 header 和 attribute data 两部分,如下图所示:


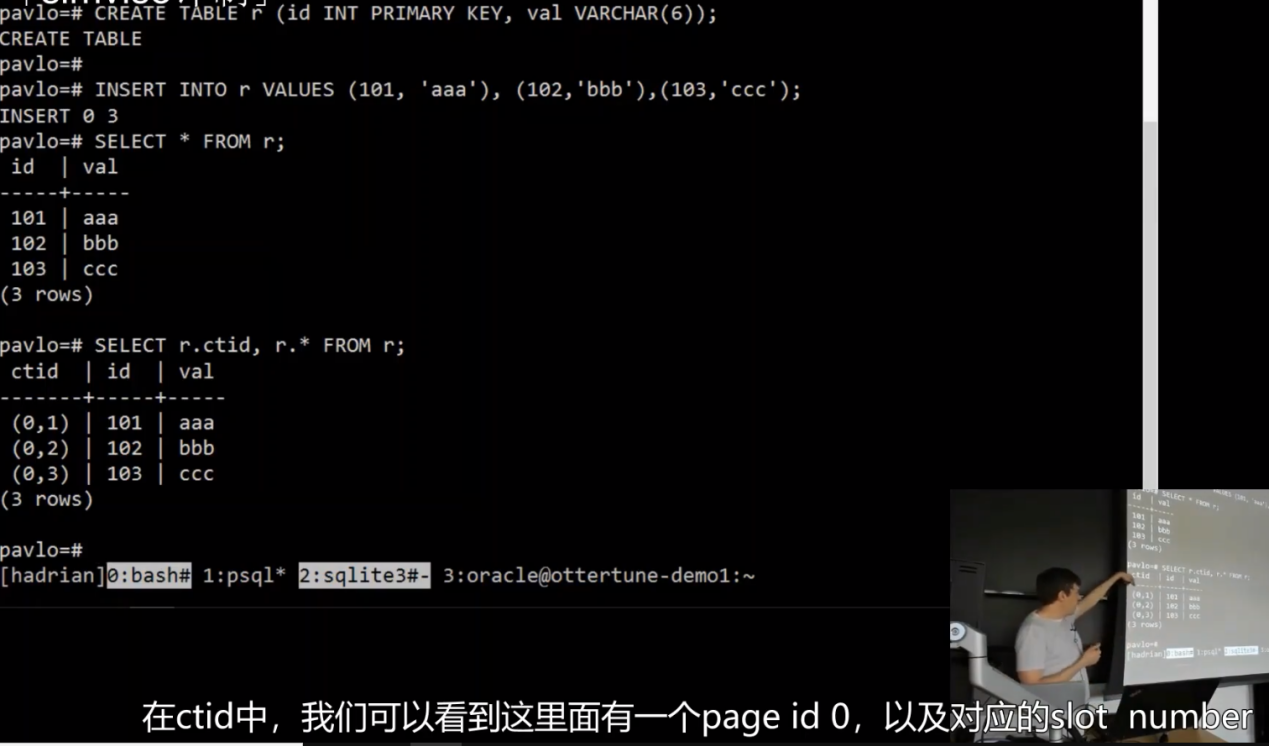
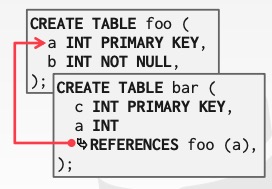
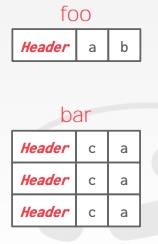
有时候,为了提高操作性能,DBMS 会在存储层面上将有关联的表的数据预先 join 起来,称作 denormalize,如下图所示:
![]()
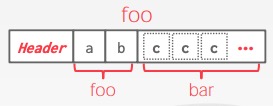
为每个bar表中的tuple复制了a属性。这被称为反范式化。在内部page会把他们合并在一起存储,但是在外部对外展示这两张表是分开的。
如果表 bar 与表 foo 经常需要被 join 起来,那么二者可以在存储阶段就预先 join 到一起,这么做当然有利有弊:
- 利:减少 I/O
- 弊:更新操作复杂化
Log Structured:记录数据的操作日志
log-structured 这种方式page中不存储数据,而是存储记录,如下图所示:

![]()
其中, ![]()
这种叫做日志文件系统。
问:为什么要这么做?去记录每次的日志信息。
答:这样做回滚起来很方便。这样操作会更快,因为顺序读取和访问的速度要比随机访问快得多。

缺点:在查询场景下,就需要遍历 page 信息来生成数据才能返回查询结果。为了加快查询效率,通常会对操作日志在记录 id 上建立索引,如下图所示:
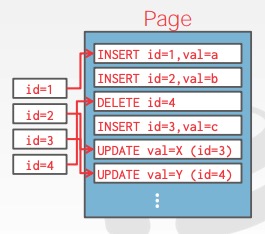
log-structured: build indexes
另外,定期压缩日志也是不可或缺的
作业1

tuple storage:如何使用tuple来表示数据:

本质上,一个tuple就是一串字节序列,DBMS有解码方案去解释这些字节序列。

![]()

数据类型:


针对浮点数,遵循IEEE754标准;
针对变长类型,是有一个header保存长度。这与C语言不同,C语言会有一个\n终结符,而数据库不一样,此处,我们则是使用一个前缀来告诉我们这些东西有多大。
针对时间:大多数系统是从1970年1月1日起的秒数或者微秒数来处理的。



以上是数据库系统中所有东西并且也是我们要在数据库系统中实现的东西。
针对固定精度数:

如果希望允许数据精确到任意精度(arbitrary precision),则可以使用 numeric/decimal(数值/小数) 类型类存储,他们处理的基本思路就是按照字符 VARCHAR处理(类似于VARCHAR,但不存储为字符串),长度不定,以 Postgres数据库 的 NUMERIC 类型为例,它的实际数据结构如下所示:
typedef unsigned char NumericDigit;
typedef struct {
int ndigits; // # of Digits
int weight; // Weight of 1st Digit
int scale; // Scale Factor
int sign; // Positive/Negative/NaN
NumericDigit * digits; // Digit Storage
} numeric;


但是这种固定精度的数据类型运算会非常慢, ![]() :
:
![]()

![]()

来源:https://doxygen.postgresql.org/interfaces_2ecpg_2pgtypeslib_2numeric_8c_source.html#l00722
overflow page

使用overflow page解决问题:
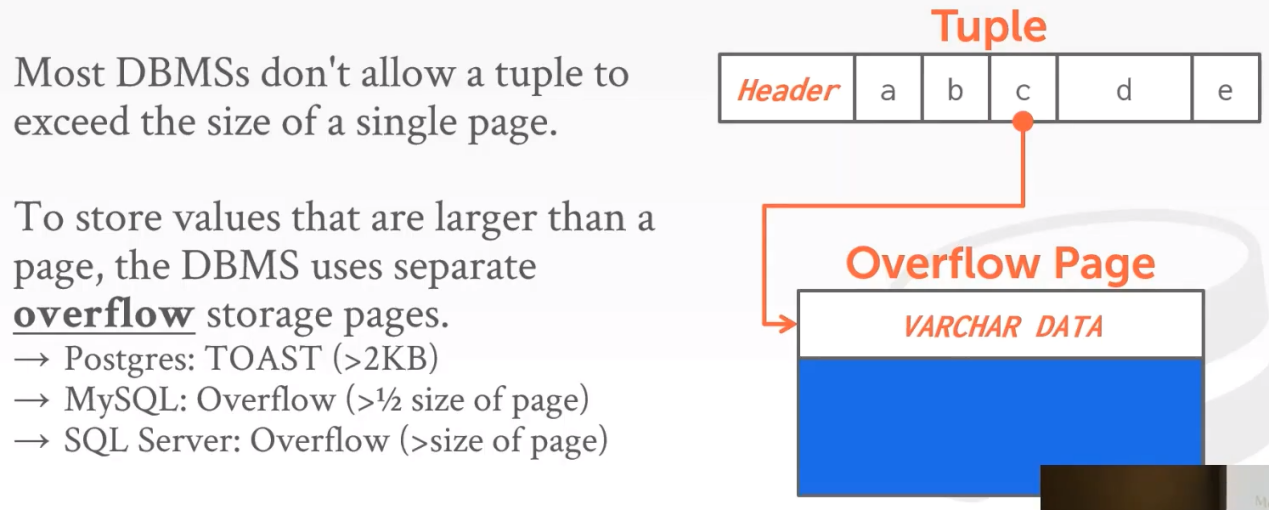
一般不往overflow page上写东西,只用来读:

外部存储
![]()


就跟一个网站,我们会把回帖发帖的文字信息保存在数据库中,而不会把上传的图片、视频文件保存在数据库中,而是会存在外部存储中,例如硬盘。
Ps:追溯到2000年的一篇论文,任何小于256Kb的东西我们会保存在overflow page,大于256Kb会保存在外部文件上。
一个SQLite专家说
![]()
如何保存表的元数据

很多DBMSs 都将这些元数据也存储在一个特定的数据库中,它们本身也会被存储为 table、tuple。
根据 SQL-92 标准,大部分数据库系统通过 INFORMATION_SCHEMA 把元数据暴露出来,数据库来查询这些数据库的元信息,但一般 DBMSs 都会提供更便捷的命令来查询这些信息,示例如下:
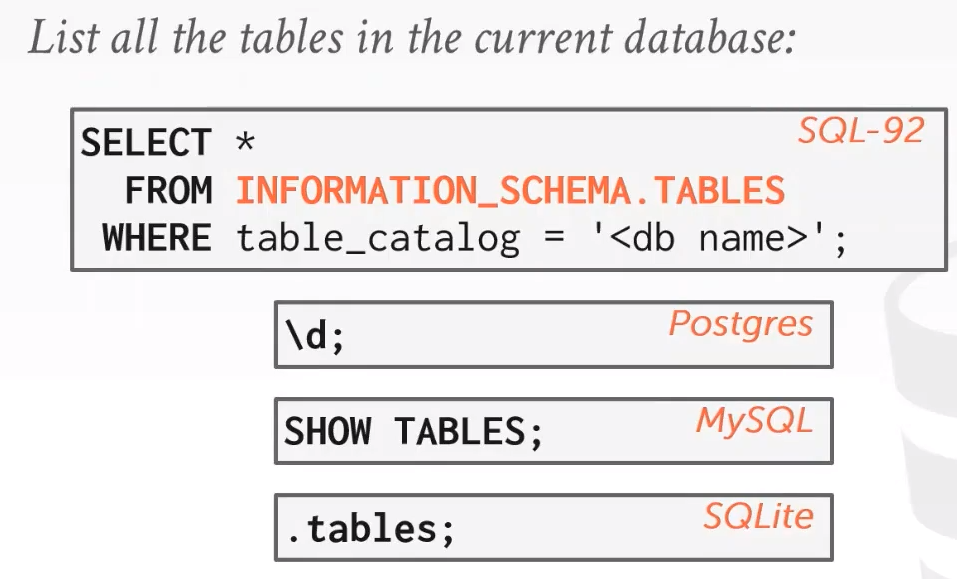
![]()
得到某张表的schema模式:
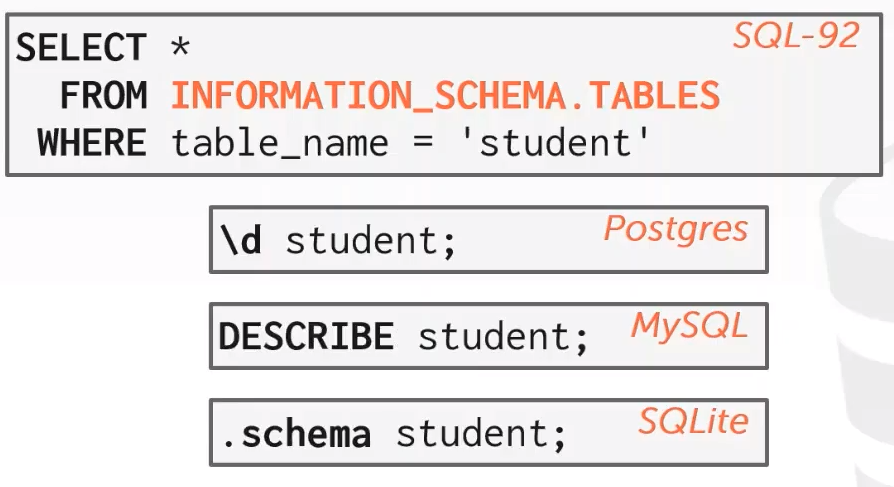
所有的数据库系统也有自己的快捷方式来获取这些信息:
![]()




![]()
总结:在实验代码中,是通过swich语句来解析的,但实际的数据库中往往会有编译的步骤,会提前把指令编译目标代码。但这门课不研究编译部分。——我自己希望可以纯手写一个SQL编译器,因为之前的编译实验用的是第三方库,后面我想自己纯代码实现。
存储模型
就是关系模型。
WorkLoad
数据库的应用场景大体可以用两个维度来描述:操作复杂度和读写分布,如下图所示:
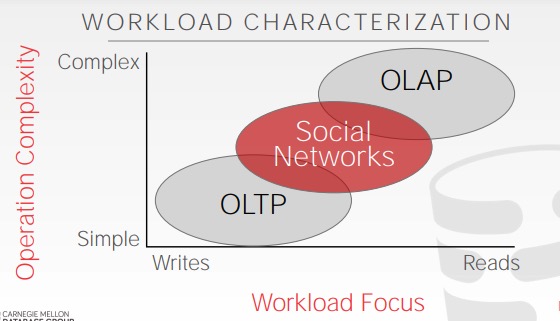
坐标轴左下角是 OLTP(联机事务处理),OLTP 场景包含简单的读写语句,且每个语句都只操作数据库中的一小部分数据(常规操作,例如注册用户、添加商品到购物车),对于用户来说不会更新太多数据,一般就是更新自己的账户信息,自己的购物车信息。举例如下:
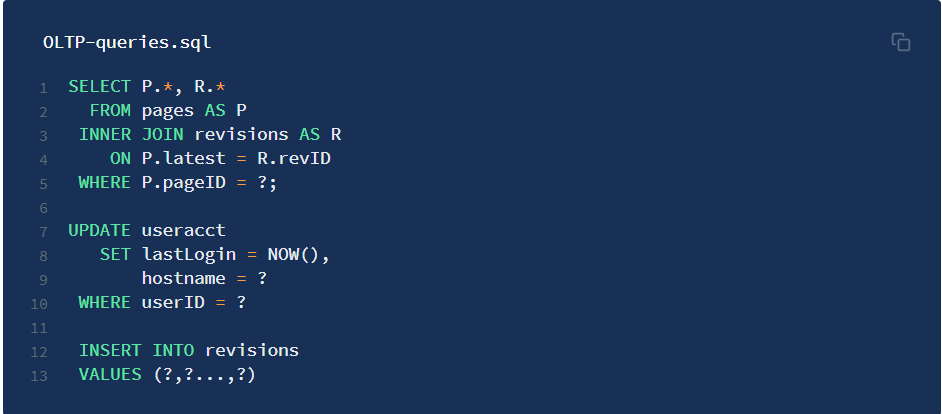
另一种WordLoad被称为OLAP(联机分析处理),OLAP 主要处理复杂的,需要检索大量数据并聚合的操作(有点像数据科学、大数据处理、商务智能),这种场景下不会更新数据。举例如下:
 上图
上图  。这种操作一般是只读、会读取大量的数据、会扫描整张表。
。这种操作一般是只读、会读取大量的数据、会扫描整张表。
位于中间的,还有一个是,HTAP:混合事物分析处理。——想要提取数据并拿到数据时,对他分析。另一种情形,有时候我们希望立即作出决策。例如在网络广告商公司中,需要对查询马上做出分析推荐。
下面讨论什么样的数据存储模型才能更有效的支持上述的WorkLoad。
Data Storage Models(数据存储模型)
目前常见的数据存储模型包括:
- 行存储:N-ary Storage Model (NSM)
- 列存储:Decomposition Storage Model (DSM)
行存储
NSM(行存储) 将一个 tuple 的所有属性在 page 中连续地存储,这种存储方式非常适合 OLTP 场景,如下图所示:

DBMS 针对一些常用 属性 建立 Index,如例子中的 userID,一个查询语句通过 Index 找到相应的 tuples,返回查询结果,流程如下:
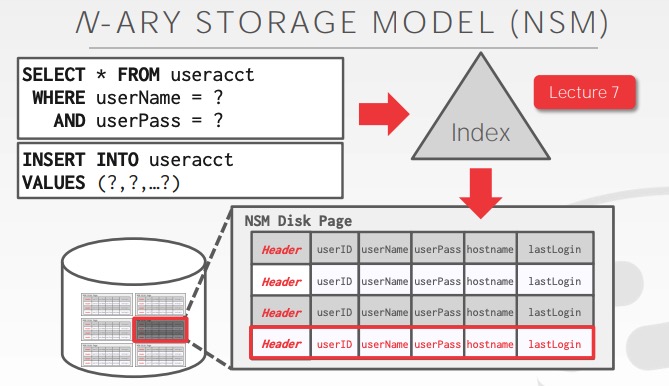
但对于一个典型的 OLAP 查询,如下图所示:

尽管整个查询只涉及到 tuple 的 hostname 与 lastLogin 两个 属性,但查询过程中仍然需要读取 tuple 的所有 属性。
总结一下,行存储的优缺点如下:
- 优点
- 可以高效的 插入、更新、删除,涉及表中小部分 tuples
- 有利于需要整个 tuple (所有属性)的查询
- 缺点
- 不利于需要检索表内大部分 tuples,或者只需要一小部分属性的查询

下面引出列存储。
列存储
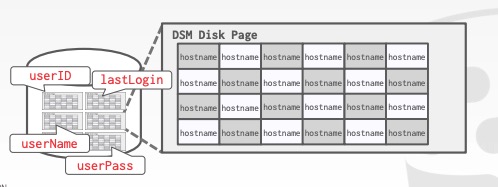
对于联机分析处理来说简直是太棒了。在这里例子中用了一个page专门存放lastLogin数据,另一个page专门存放hostname数据。相当于将原来行存储的一列(属性)放入一个page中。和之前必须扫描所有的page来相比,现在只需要扫描两个page即可。
问题:怎么知道这个page中的任意一个单元格对应的是之前存储的哪行?
回答:问得好,可以通过一些手段实现,但本课程不做介绍。
改进:压缩
这种列存储很Nice!我们还可以将他们压缩。例如某个page保存的是一个月中每天的气温信息,那我们可以直接记录当天气温与昨天的差值即可,无需保存完整的温度。也可以去使用一些压缩算法,例如Gzip、Snappy算法。但是像mp3文件是无法压缩的,因为他实际上已经是压缩过了。但如果是一个文本文件通常就可以压缩,因为里面有大量的重复字符存在。原来每个page上只能存放1000个tuple,现在因为压缩可以存放更多tuple。当然现在在没有解压的情况下某些系统可以直接对压缩数据进行操作了。但是这门课中我们不会去介绍关于压缩的部分内容。这是高级课程的内容。
问题:

如何跟踪每个 tuple 的不同 属性?有两种解决方案:
- Fixed-length Offsets:对于一列中的每一个值来说,他们的长度都是固定的,直接靠 offset 来跟踪。(常用)
然后,对于不同长度的字符,我们怎么使用偏移量这种方法?

不同DBMS做不同的事,当然这也是常见的办法。


这就是下面的方法。
- Embedded Tuple Ids:在每个 attribute 前面都加上 tupleID





新兴的 Hbase、HP Vertica、EMC Greenplum 等分布式数据库均采用列式存储。
在本课程中,你也可以去做列存储数据库,当然这不强制要求。
总结:
OLTP适合行存储。
OLAP适合列存储。
问: 
答:



这种称为混合存储系统,或者叫混合数据库系统。一般是用两个引擎对他们进行处理,用一个引擎很难实现。现在还没有一种完美的数据库系统可以同时支持行存储和列存储。MySQL也做的差强人意。
问:

答案:



举个实际的例子:淘宝保存你最近90天的购物数据,




问题二:如何管理内存以及在硬盘上移动数据
请看下一章Buffer池与内存管理。