本文已收录到:CMU数据库系统学习笔记 专题
视频课程(中字幕)、课件
Hash Tables
课件:
引言
access method:buffer池之上的东西

今天来讲buffer池管理器之上的东西——Access methods。

在数据库管理系统中数据结构无处不在,接下来的几节课,会重点讨论数据库系统内部所维护的数据结构。我们在讨论page table或者page directory时
,其实他们就是一个hashtable,我们通过传入一个page id就能找到对应的frame,或者传入一个page id就能找到磁盘中对应的位置。
它们可能被用在 DBMS 的多个地方,包括:
- 内部元数据
- 核心数据存储,例如MySQL innodb的B+Tree
- 维护/存储临时数据,例如查询语句
- 表索引
哈希表主要用于储存数据库自身核心数据。为了支持 DBMS 更高效地从 pages 中读取数据,DBMS 的设计者需要灵活运用一些数据结构及算法,这些page我们
 ,例如
,例如 ![]()
![]()
![]() ,例如可以用数据结构存放查询语句。
,例如可以用数据结构存放查询语句。

在做相关的设计决定时,通常需要考虑两个因素:
- 数据组织:如何将这些数据结构合理地放入 memory/pages 中,以及为了支持更高效的访问,应当存储哪些信息。
- 并发性:如何支持数据的并发访问。
哈希表 Hash Tables
其中对于 DBMS 最重要的两个是:
- 哈希表
- Trees

哈希表可以快速的查询我们想要的元素。哈希表是 associative array/dictionary ADT 的实现,它将键映射成对应的值。简介这里不再赘述,可参考 MIT 6.006 Dictionary Problem & Implementation。
哈希函数
由于DBMS内使用的哈希函数并不会暴露在外,因此没必要使用加密的散列函数,我们希望它速度越快越好,碰撞率越低越好。目前各 DBMS 主要在用的 散列函数 包括:
下面这个是最简单的哈希表,指数取模,取模运算是求两个数相除的余数。通过对key进行hash,即对该key与所有元素数量进行取模操作然后会得到它对应的offset值。
举例:
abcdefghi长度是9,9对3取余模,3是元素数量,得到结果是0,所以放置在0下标位置。
xyz123,长度为6,6%3 = 0。
defghijk长度8,8%3 = 2。

我们需要提前知道元素的数量。这样才能确定在数组分配多少个slot。
完美的哈希函数:

本节课我们讨论 ![]()
hast table是由两部分组成的数据结构。
哈希函数:
- 该函数将任意的key映射到一个较小范围的interger上面。
- 速度与碰撞率之间的权衡。举个例子,比如有个哈希函数不管你给的key是多少,都会给你返回1,这样做速度超级快但是碰撞率100%。与他相反的是完美哈希函数,它的碰撞率是0%,但是速度很慢。这就需要作权衡。
散列方案:从本质上来讲,散列方案就是当我们在hashtable中遇到hash碰撞时,我们用来处理问题的一致机制。
- 遇到hash碰撞时候如何处理冲突。
- 内存量和计算之间的取舍。如果我将所有的内存都分配给hast table,那么计算就很快,但是我没有空间去做数据库本身的事情了;如果我给hash table一块很小的空间,我的物理空间(内存)会剩下很多但是计算会很慢。
哈希函数其实就是一个速度很快的函数,我们将任意的key传入该函数他就会返回一个32位或者64的长度的整数。在数据库系统中,由于 DBMS 内使用的 哈希函数并不会暴露在外,所以我们自己实现哈希表时并不用在意加密性,我们只希望它速度越快,碰撞率越低越好。但如果我们需要将数据保存在公有云等设备时可以考虑对数据进行加密。也就是说我们在数据库中的hash 函数不考虑加密性。我知道有的hash函数是加密的,但我们不需要。
目前各 DBMS 主要在用的 Hash Functions 包括:
下面讲下非常常见常用的hash函数。
完美的哈希函数:哈希地址永远充足且不重复
完美的hash函数在现实中是不存在的,是理论上的东西。下面这个就是完美的哈希函数:

不同的kay一定会有不同的对应哈希地址,永远不会重复,这是完美的。

MD5

并且MD5也是不安全的,可以通过彩虹表进行破解。

其中XXhash是上面这些hash函数中速度最快且碰撞率最低的函数,构建数据库系统可以选择XXhash。我们不用去关心hash functions内部是怎么实现的,因为这是算法课研究的东西,我们只要会使用hash functions即可。
哈希函数评分
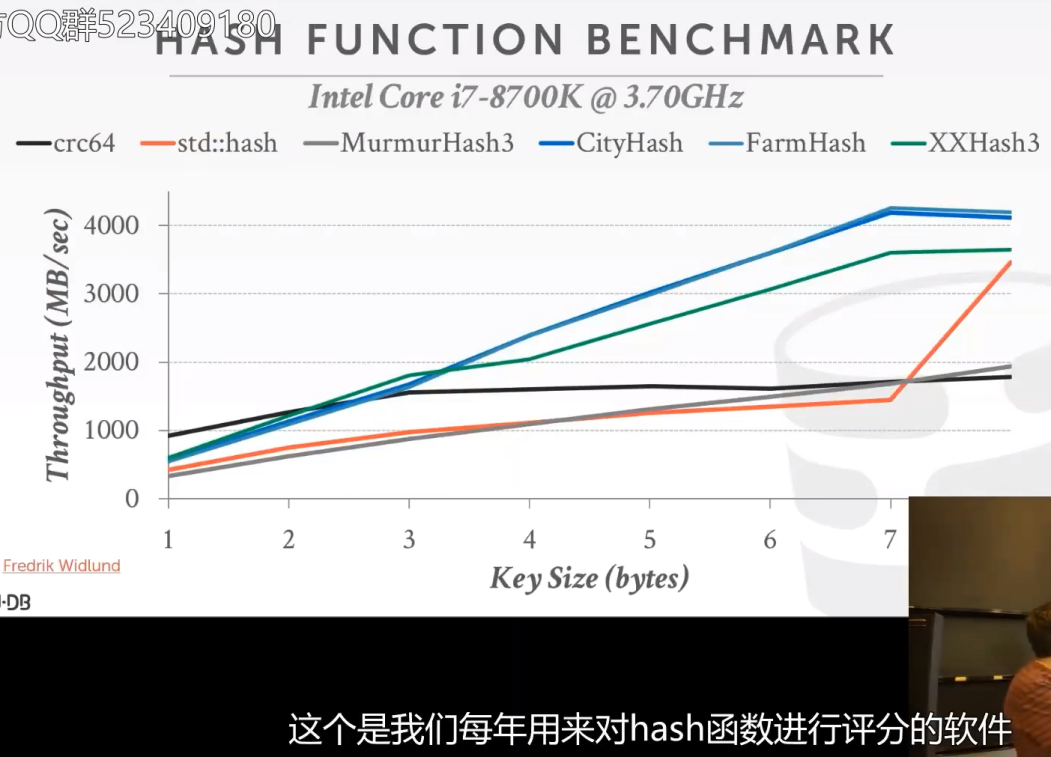
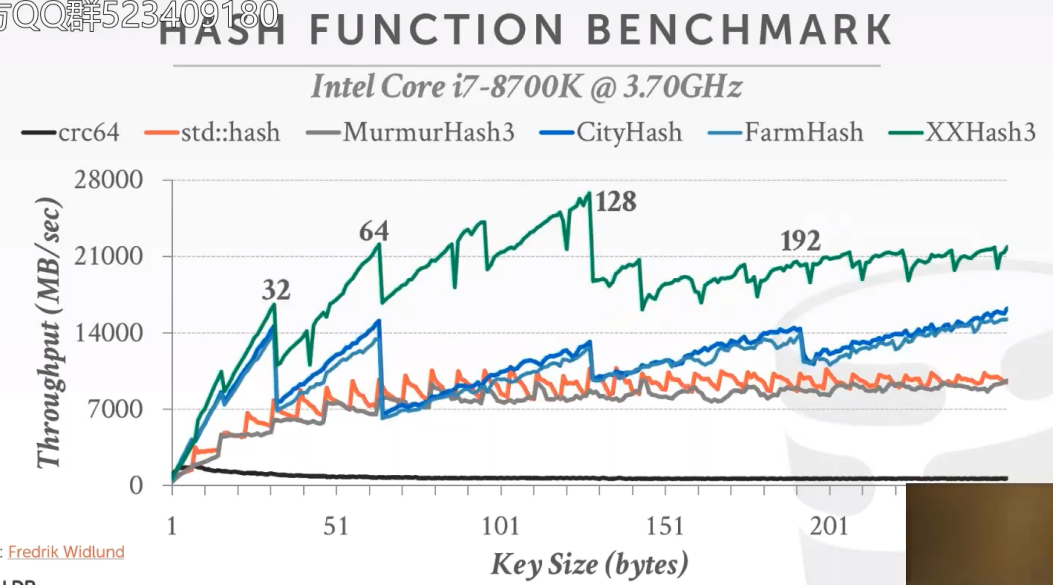
我们会从这个三个中跳出一个来用,一般来讲会用XXHASH,这对我们课程来说是足够好用的了。在我们自己的数据库系统中,会使用Xxhash。再说一遍,我们不会去手写实现hash函数,这不是本节课(数据库系统设计)所研究的,这是算法课程研究的。
散列方案(处理冲突的方法)——都是一些算法思想

静态哈希方案
需要大致估算出kay需要的空间大小。
Linear Probe Hashing
linear probe Hashing是最基本的散列方案。后面的robin hood hashing和cuckoo hashing都是在此基础上改进的。这些都是静态哈希方案,这意味着我们在一开始分配内存时就需要知道希望保存的key的数量。
Ps:Linear Probe Hashing 的主要原理在 MIT 6.006(算法课) 中已经介绍,可以参考。
放入kay时:
如下图,A、B都经过hash函数计算后放入到了空的位置,但是C经过计算后发现被A占领了,没办法,C选择占用A下面的位置。
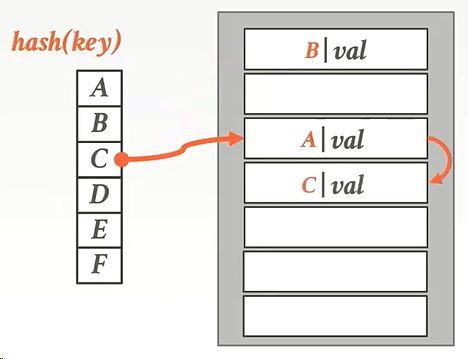
提问:如果再来一个kay发现他的位置被F占领了,怎么办?
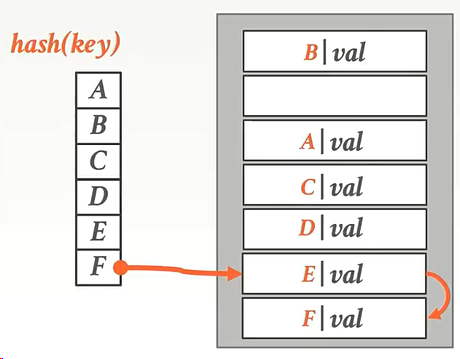
答:这个图是环形的,他会回过头看到B下面还有一个空位,于是放在那里。
删除时:
删除C的时候,经过hash计算出的位置是A所在的位置,怎么办?
答:会往下寻找,发现C在A的下面,找到删除。
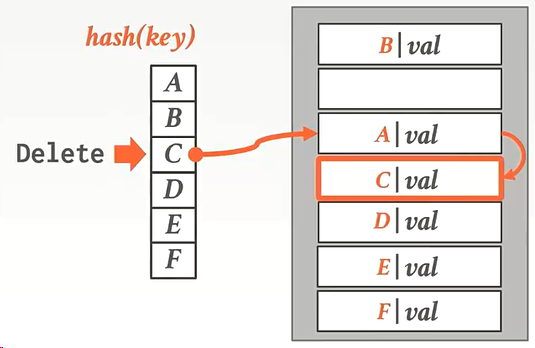
现在是这个样子:
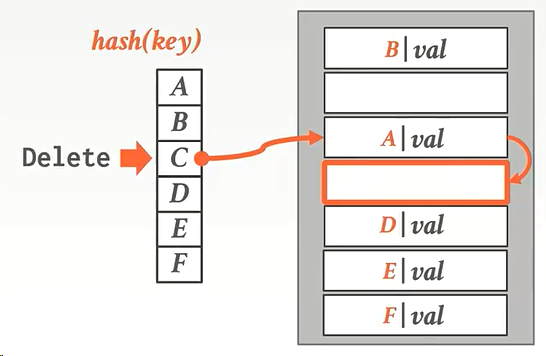
问题来了,现在我想删除D。但经过hash计算发现是红框所在的位置,发现是空的:
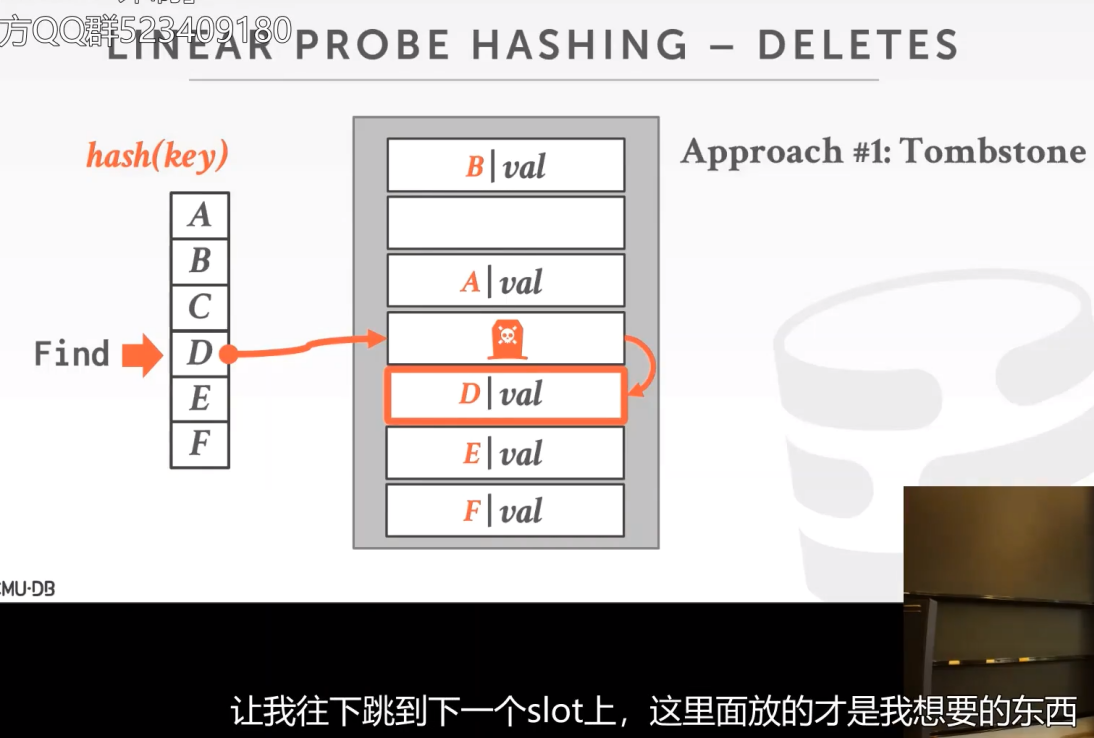
下面有两种方法解决找不到D的问题。一种是墓碑法,一种是移动法。
墓碑法解决:C被删除后,会在原位置上添加一个墓碑标记,防止查找D的时候,找到一个空的位置,误以为D不存在。
数据移动法解决:移动后我们就能通过hash函数顺利的找到元素了。

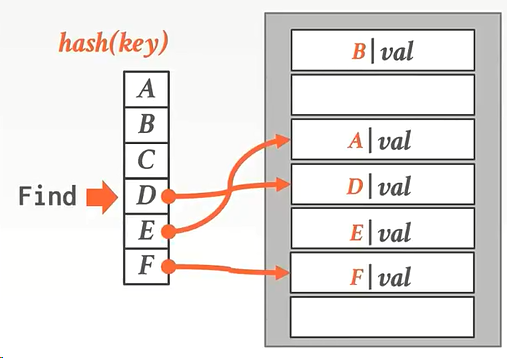
但请注意我们说过这是环形的,B的原始hash计算出的位置是最上面。但是B的上面也有一个空位(因为是环形的,B上面的空位说的就是最下面的那个位置),如果B也往上面移动就会跑到最下面的这个位置。


![]()
![]()
![]() ,也就是说不会找到第一行上面的位置(因为是环形的,也就是找不到最下面的B)。——这一部分有点绕,所以说实际中,我们通常会使用墓碑法,因为移动数据很麻烦!
,也就是说不会找到第一行上面的位置(因为是环形的,也就是找不到最下面的B)。——这一部分有点绕,所以说实际中,我们通常会使用墓碑法,因为移动数据很麻烦!
友情的提示下,在真正的数据库系统中,如果我需要构建临时数据结构用于存放查询语句的,我只是扫描下数据放入哈希表中,并不涉及单个元素的删除。另一种情况是hash索引需要删除,那用墓碑法就行。
一个key对应多个value问题
当 keys 可能出现重复,但 value 不同时,有两种做法:
![]() :
:
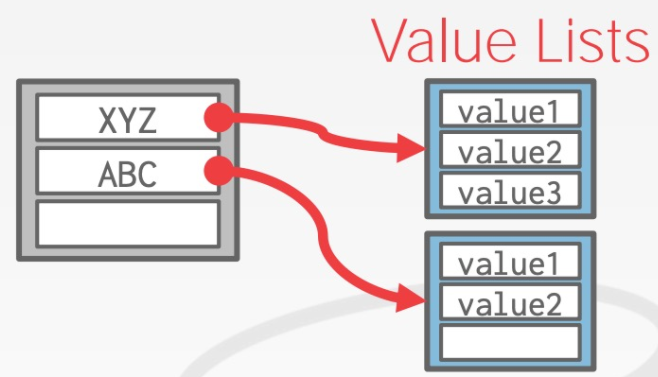
另一种方法是保存冗余的key:

通常为了减少 冲突 和 比较,Hash Table 的大小应当是 table 中元素量的两倍以上。
Ps:在实践中,所有人用的都是第二种方式。
Robin Hood Hashing
robin hood中文叫做罗宾汉,讲述的是一个劫富济贫的故事。

Robin Hood Hashing 是 Linear Probe Hashing 的变种,为了防止 Linear Probe Hashing 出现连续区域导致频繁的探查操作。
这个算法所期望的是 ![]()
基本思路是 “劫富济贫”,即每次比较的时候,同时需要比较每个 key 距离其原本位置的距离(越近越富余,越远越贫穷),如果遇到一个已经被占用的位置(slot),如果它比自己富余,则可以直接替代它的位置,然后把它顺延到新的位置。
eg:
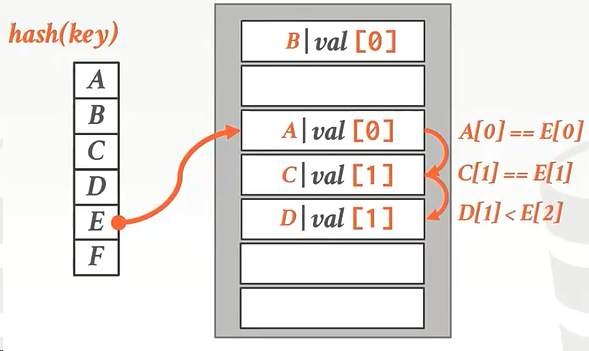
上图E比D要穷,于是让E替换D,D去E的下面。
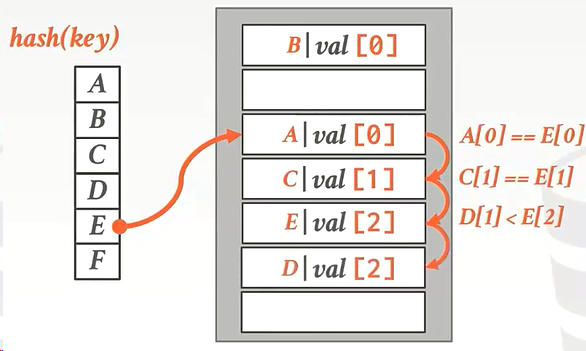
算法期望的是:
- 两个元素每个都与他原来的距离相差1个单位。(√)
- 一个元素与他原来的距离相差2个单位,另一个元素就在原来的位置上。(×)
追求的是整体大家都不穷,贫富差距小。
总结:
![]()
 ,这就需要更多的写入操作,会导致更多的缓存无效。现实中,Linear Probe Hashing仍然是碾压一切的算法。
,这就需要更多的写入操作,会导致更多的缓存无效。现实中,Linear Probe Hashing仍然是碾压一切的算法。
Cuckoo Hashing
这个方法还是期望的“继续往下扫”,有多个hash table,让我们去决定往哪个hash table中放入key。在实践中大多是使用两个Hash Table。

对第一个数据来说,随机选取:


对于第二个数据来说,Hash Table #1已经被占用,所以会选择空的#2:

因为不需要任何移动。
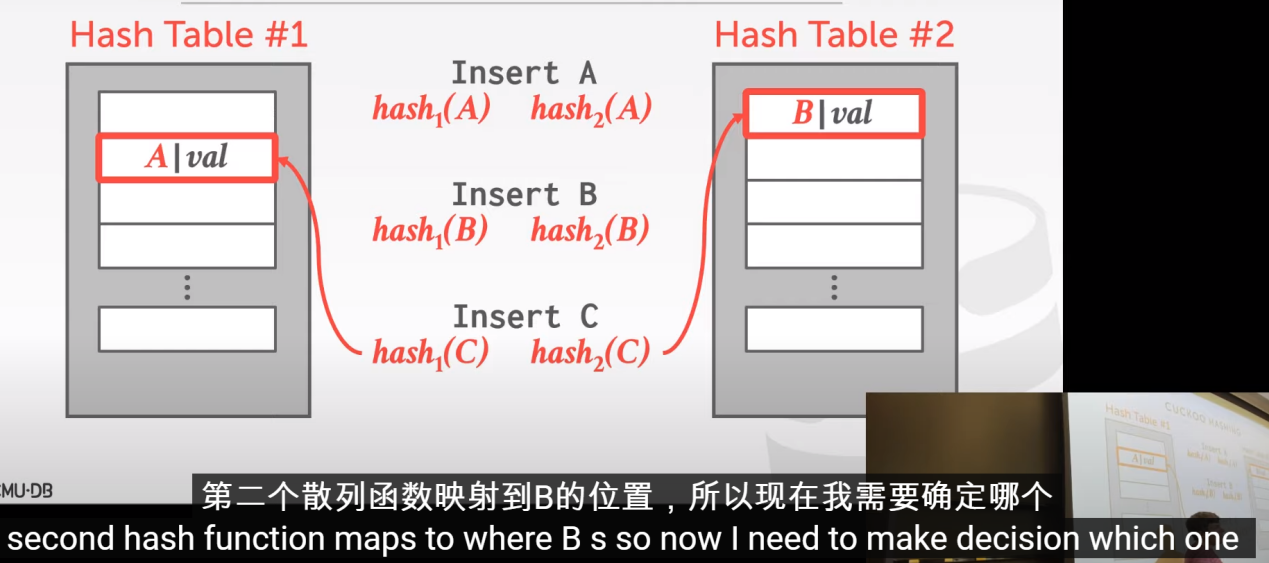
… … 算法的具体过程可以看视频第44 分40秒开始。
小结
以上介绍的 Hash Tables 要求使用者能够预判所存数据的总量,否则每次数量超过范围时都需要重建 Hash Table。
静态哈希方案可能被应用在 Hash Join 的场景下,如下图所示:

![]()

由于 A, B 表的大小都知道,我们就可以预判到 Hash Table 的大小。
![]()
![]()
![]()
但是在cuckoo hashing中,这有所不同。
![]()
动态哈希方案
改进:与静态哈希方案需要预判最终数据量大小的情况不同,动态哈希表可以按需扩容缩容。
本节主要介绍 三种方法:Chained Hashing,Extendible Hashing 和 Linear Hashing。
Chained Hashing(链式哈希表)
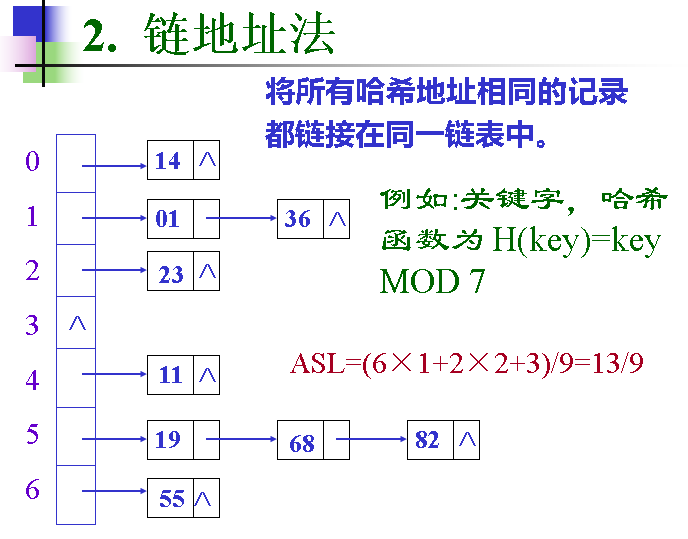
Chained Hashing 是 动态哈希表 的小案例级别的实现,每个 key 对应一个链表,每个节点是一个 bucket,装满了就再往后挂一个 bucket。需要写操作时,需要请求 latch。

这么做的好处就是简单,坏处就是最坏的情况下 Hash Table 可能降级成链表,使得操作的时间复杂度降格为 O(n) 。
Extendible Hashing(扩展哈希表)
本算法还是依托上面的链式哈希表,但存在扩展问题,我们会逐渐拆分 
,基本思路是一边扩容,一边重置哈希表。
具体算法讲述请看视频第51分30秒开始。
Ps:感觉这样的算法很像计算机网络中的IP地址子网掩码,有点像划分子网的感觉。全局计数器就像子网划分掩码,决定了多少位是网络位,多少位是主机位。

注意:我们这里的bucket存放的都是page id而不是page本身。本节hash 函数所做的事情是给一个key如何更好的返回value的问题。再hash table的上一个层面,使用者并不关心你hash 函数内部是如何管理kay和value的,使用者只是想找到page id罢了。我们本节说的都是内部算法的东西。——哈希函数解决的是查找问题。
Linear Hashing(线性散列)

基本思想:维护一个指针,指向下一个将被拆分的 bucket,每当任意一个 bucket 溢出(标准自定,如利用率到达阈值等)时,将指针指向的 bucket 拆分。
eg:17放不下bucket了就将其拆分。
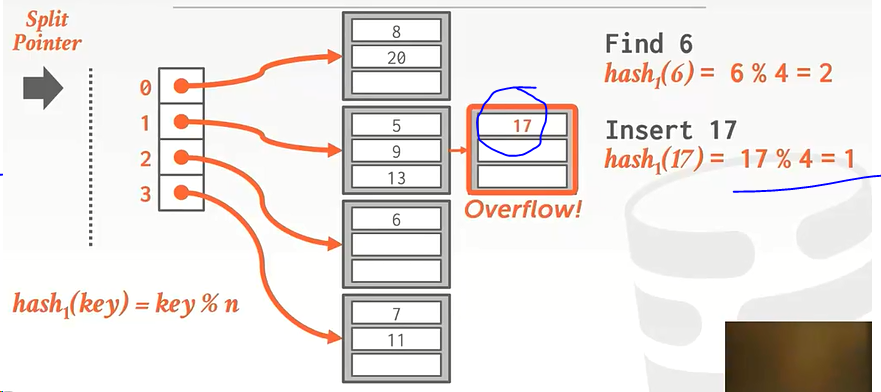
… …讲解看视频吧,第1小时01分开始。感觉很巧妙。
总结:数据库系统中的很多地方都能用到哈希函数。再许多场景中,哈希函数已经足够用了。 
在创建索引时我们最常使用B+Tree。几乎每个数据库都有B+Tree的实现。除了memcache这类系统,它就是一个hash table。