本文已收录到:CMU数据库系统学习笔记 专题
作业进度提醒

视频课程(中字幕)、课件
视频:https://www.bilibili.com/video/BV1tL4y1J7kJ/?spm_id_from=333.788
课件:
Join Algorithms
问:为什么会有JOIN?
答:这是数据库范式化的产物,我们将数据拆分,以此来减少重复和冗余信息。
本节我们讨论一次只将两张数据表进行JOIN连接的操作,这在当今的数据库系统中都已经实现了。虽然有很多的商业数据库也实现了同时将三张表、甚至N张表进行JOIN连接的操作,但这并不是常见的,我们将会在高级课程15-721中讲述。所以本课还是主要讨论 一次只join 两个 tables 的过程。
JOIN的输出(JOIN算子输出什么?)
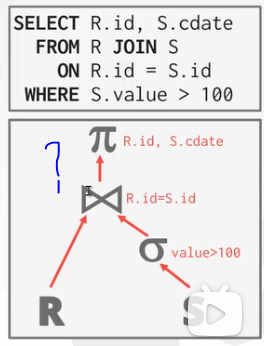
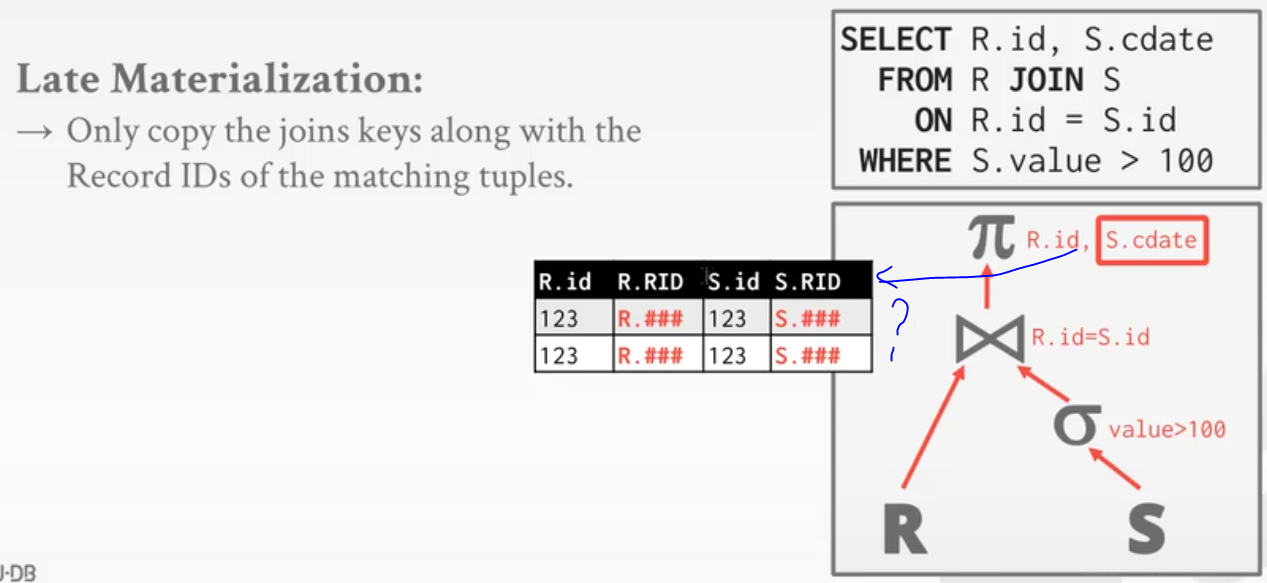
下面这张图的处理方式是提前物化,其优点是上层需要筛选哪列就不用回表再查询了,非常方便,要哪列就用哪列。
输出数据本身:


延迟物化:延迟物化的缺点是上级想找到S.cdate就需要重新去表中搜索。
JOIN和笛卡尔积
JOIN是数据库中最常用的算子,与JOIN相似的还有一个算子是笛卡尔积。但是笛卡尔积十分耗时,因为它会生成很大的中间表。比如表A的记录数是10条,表B时10条,做笛卡尔积会出来10×10 = 100条数据。笛卡尔积就像是没有匹配条件的JOIN操作。
I/O Cost Analysis
数据库之所以设计 JOIN Algorithm 的目的就是因为数据库中的数据量通常较大,无法一次性载入内存,使用 JOIN Algorithm 可以减少磁盘 I/O,因此我们衡量 JOIN Algorithm 好坏的标准,就是 I/O 的效率。
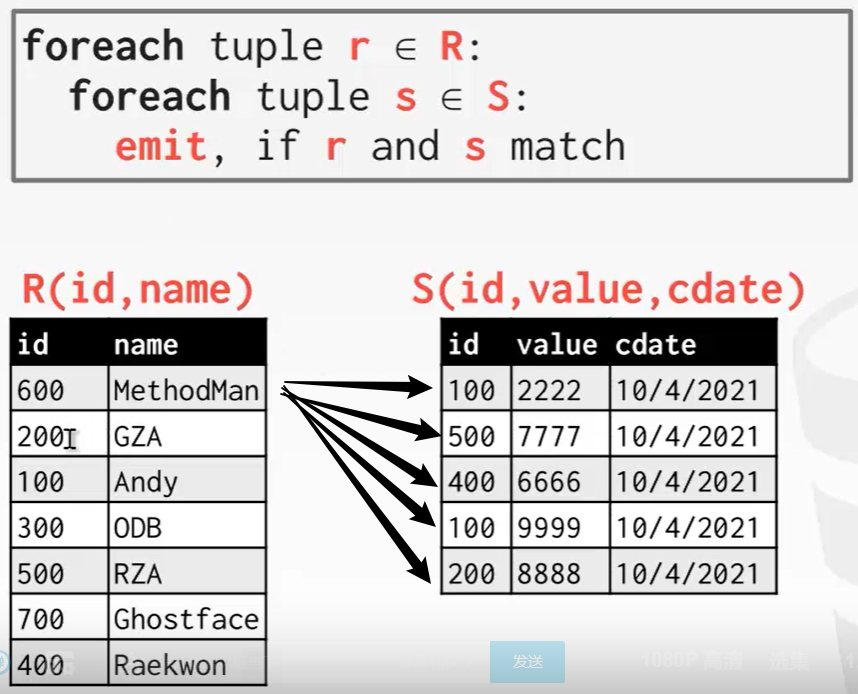
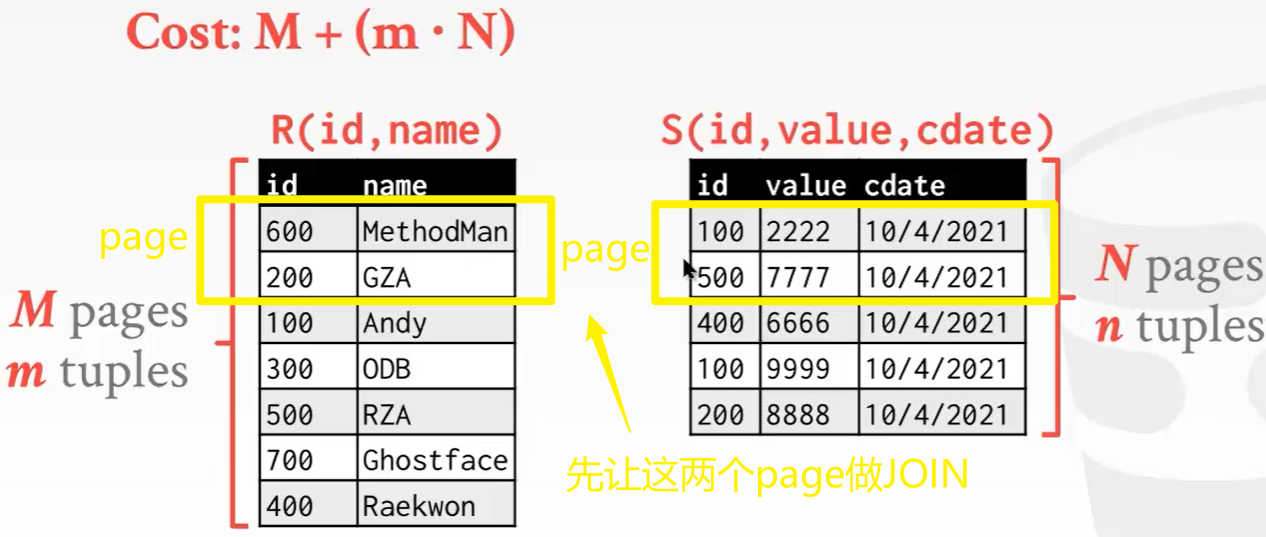
嵌套循环连接(所有数据库系统都支持)
Simple——STUPID 方案
循环嵌套连接就是需要one by one的连接后比较,即 r and s match。
![]() ,
,![]()

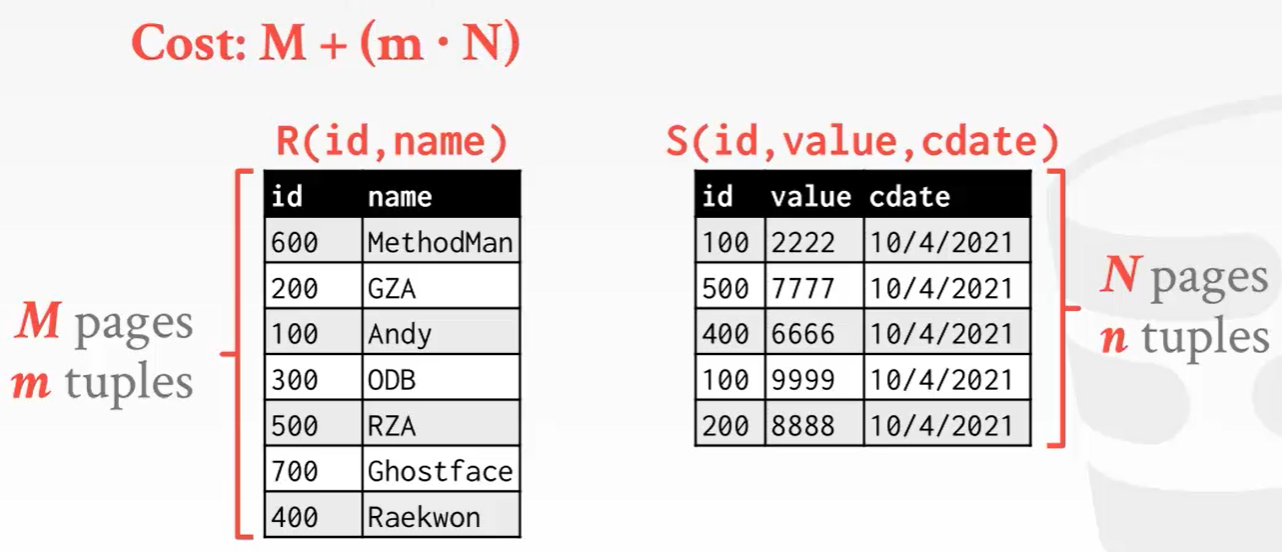
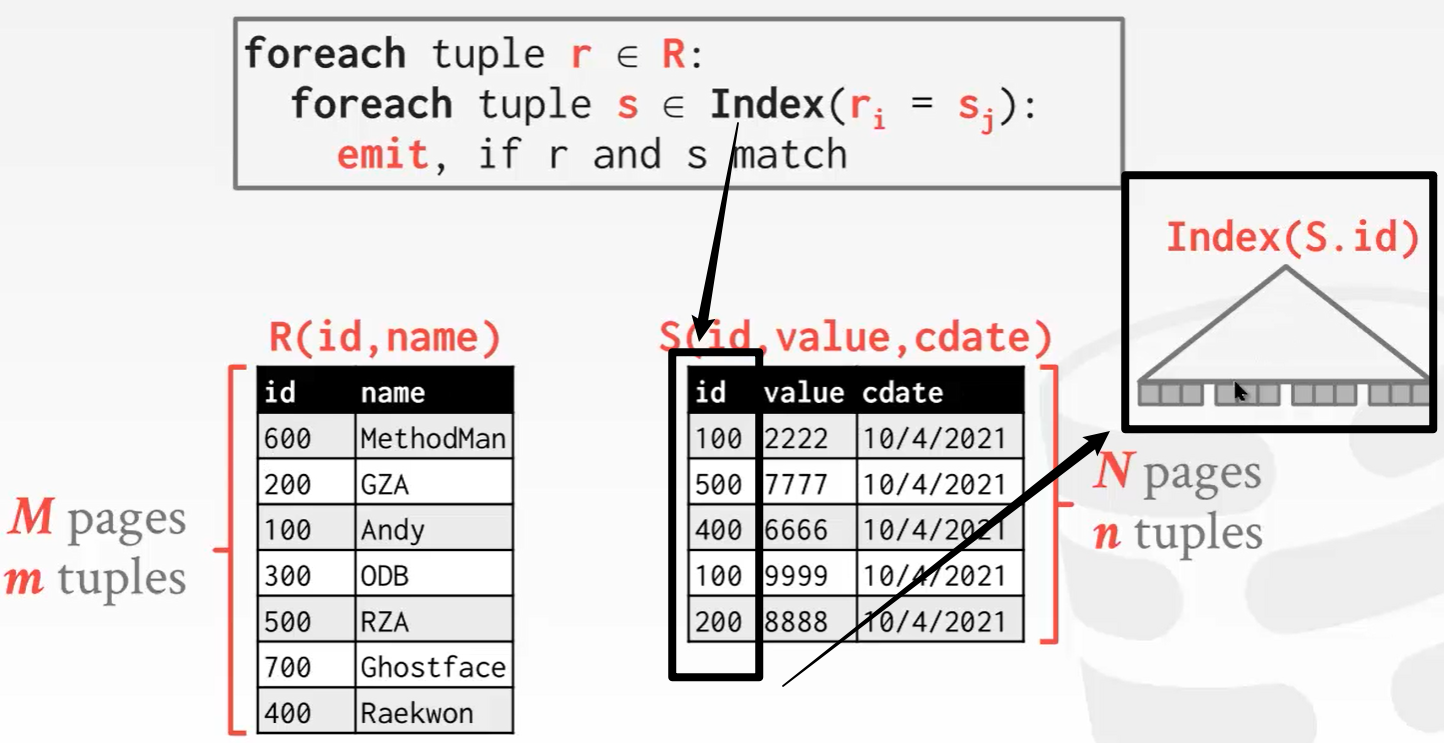
下面这张图,M代表左表的页数,m代表行数。右边也同样。
R作为外部表,S作为内部表。这样的话一个消费级SSD每次IO仅需要0.1ms的情况下还需要1.3小时才能完成JOIN操作。

S作为外部表,R作为内部表。这样计算下来就只需要1.1小时了。
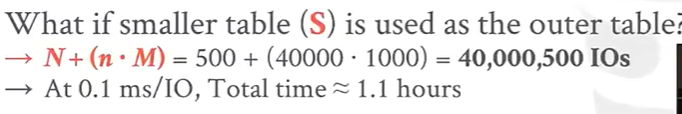
所以JOIN操作一般将小表放在坐标作为外部表,大表放在右边作为内部表来布局。
答:这里所说的小表指的是表的宽度而不是长度。
这种方法其实也很蠢。每次计算都需要把右边换入的内存中。上面我们计算的就是从硬盘换入内存的时间,这通常是不可忍受的。但如果是在内存中直接做运算就会快很多很多。
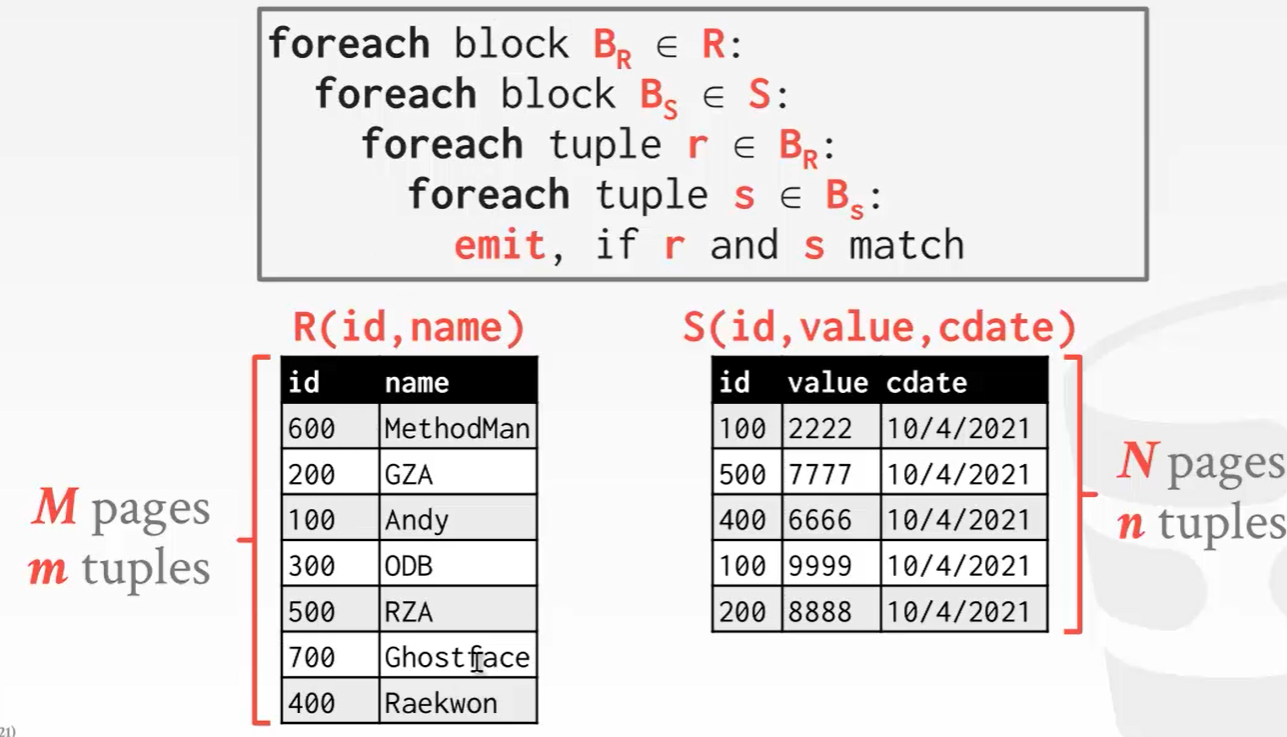
Block——对循环嵌套连接做改进,将多个tuple打包进page。

比如左表中选取两个tuple作为page,右表中也是两个tuple作为page。先这这两个page中的4个tuple两两比较,如果没有找到就直接抛弃右边的page,往下顺移。请注意:page和block其实是一个意思,这个叫做什么是无所谓的。
问:那page内部不还是一样要两两比较吗?
答:但是page可以在内存中遍历啊,这与从硬盘中不断地换入tuple到内存是不一样的。
同时缓存一个R中的一个page和S中一个page。这样做可以减少遍历页数,从左表需要遍历m次变成了M个page。
算法:
改进后的消耗:

改进:如果我们的内存池很大,如何利用它?
如果我们开B个page大小的内存,如果一个page是16kb(以MySQL为例)那就是 16kb*B个大小的内存池。如果你忘了page是什么,请回顾我们在存储引擎章节所学的内容 –> 数据库page
给1个page作为输出缓存,再给一个page作为内表(右表)缓存是,剩下的B-2个page全给外表(左表)缓存。
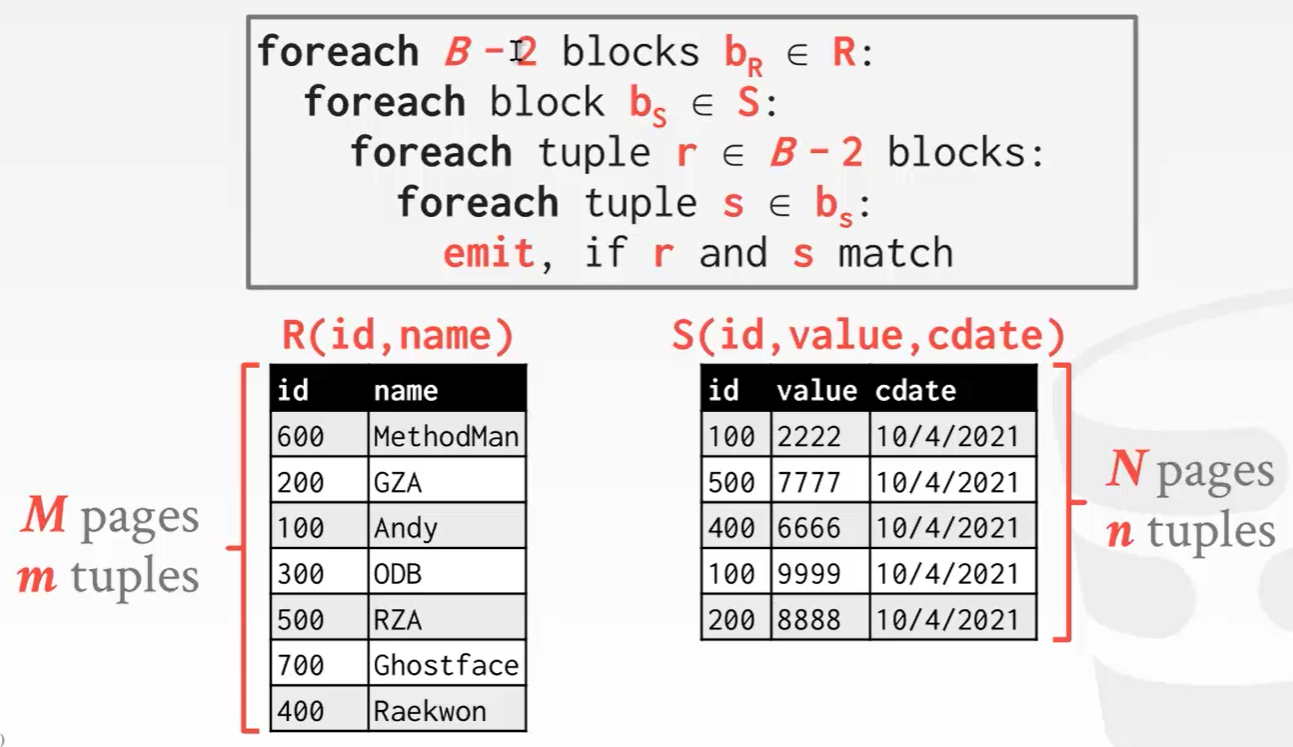
IO开销:
![]()
如果左表整个都能塞进内存池中
![]()
总结:其实就是利用内存,尽量的放在内存中,这样IO开销就会小。但是需要注意:内存中的运算开销也会增大,但是内存跟硬盘换入相比的开销可以忽略不计。
使用索引的循环嵌套连接
对右表做索引,通过索引的方式在B+Tree中做查找。使用所以可以大大的减少开销,提高查询速度。如果忘了B+Tree的知识,移步复习 –> B+Tree——数据库中广泛应用的数据结构
IO开销:

排序归并连接(建立在上节课所讨论的排序知识上面)
先给两个表按 JOIN key 排序,再归并。

IO开销:
关于排序算法回顾上节讲的内容 –> CMU15-445数据库系统:排序与聚集
带入我们之前的例子:

劣势:不过我们发现了这个算法最差的情况——索引全部都是一样的值。这样就退化成 stupid 模式了。
优势:如果已经排好序的话,只需要1500次IO就可以了。
随着B+Tree的增长,扫描B+Tree的时间会越来越长。对这种一对一的查询,其实不需要B+Tree那样的扫描特性。什么样的索引更适合点查询?——Hash
Hash Join(最重要、最快的算法)
如何利用hash表?
步骤:
- 先扫描R表,构造哈希表。
- S的每一行都去hash中查询。(也就是用R表创建hash表,用S表去使用hash表查询)
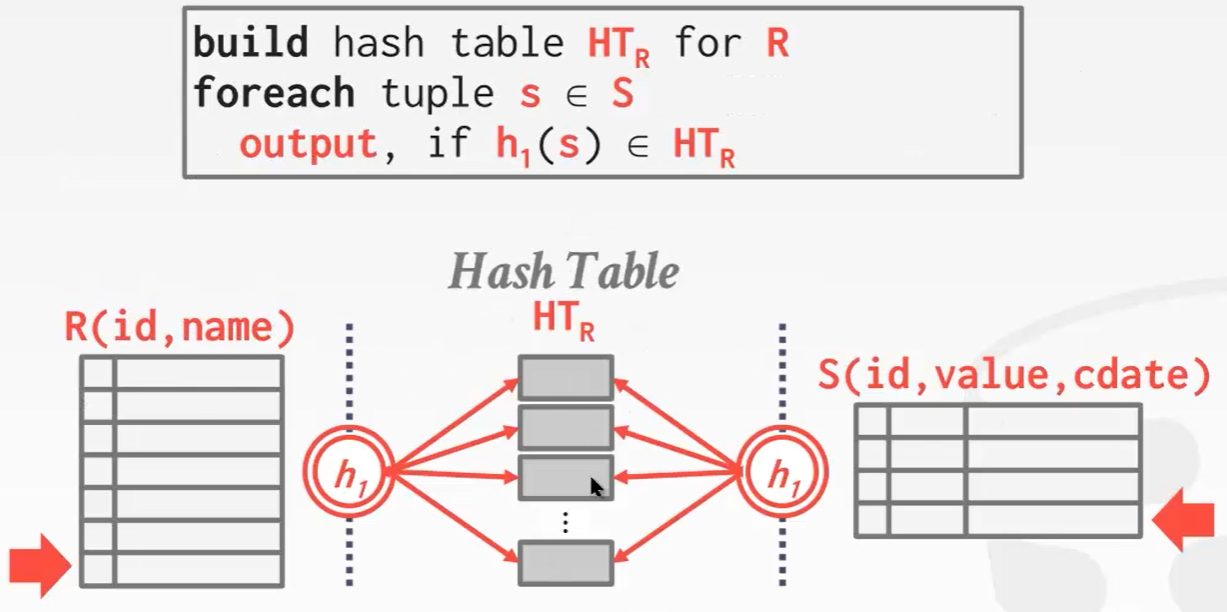
哈希表的key和value放什么?
key放置连接点。value还是有提前物化和延迟物化两种思路。可以存放R表中的所有字段;也可以存放R表中的部分字段,然后后续需要的话再去page中查询。关于提前物化延迟物化问题,点这里复习。
Bloom过滤器
B去hash表中查询的时候,要先经过Bloom过滤器。如果bloom过滤器没有发现hash表中的匹配,就直接干掉,不让继续查询了。
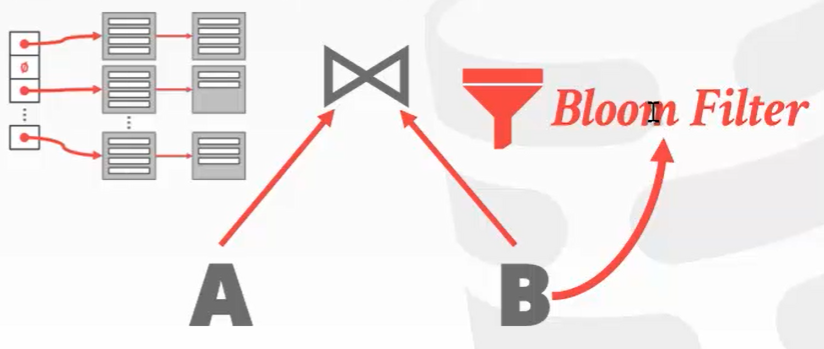
Bloom过滤器是什么?
布隆过滤器可以告诉我们 “某样东西一定不存在或者可能存在”,也就是说布隆过滤器说这个数不存在则一定不存,布隆过滤器说这个数存在可能不存在(误判)。
https://www.cnblogs.com/zhaodongge/p/15017574.html
https://blog.csdn.net/qq_41125219/article/details/119982158
配置最合适的Bloom过滤器参数:https://krisives.github.io/bloom-calculator/
Grace Hash Join——当两个 table 都无法放入内存时
前提假设R表和S表没有办法放入内存中。
解决方案:对R表和S表用同一个hash函数做哈希。分成的区域叫 桶 或者 分区。——这个叫什么名字无所谓。
这样做,只要R表和S表能连接的表一定是在同一个桶里。

如果这个桶也无法放入内存中呢?
说明这个桶还是大,那就不断的递归分桶,知道能够将桶放入内存中。
加入下面这第二个表无法放入内存,就将其再次哈希,直到可以将桶放入内存中。

S表中的1’表原本是与R表中的第二个桶比较的,但因为S表第二个桶被拆分为 1′ 1” 1”’了,所以S表第二个桶也要用h2函数哈希。

IO开销:
- Partitioning Phase:
- Read + Write both tables
- 2(M+N) I/Os
- Probing Phase
- Read both tables
- M+N I/Os
如果 DBMS 已经知道 tables 大小,则可以使用 static hash table,否则需要使用 dynamic hash table。回顾哈希表 –> CMU15-445数据库系统:哈希表
总结
| Algorithm | IO Cost | Example |
|---|---|---|
| Simple Nested Loop Join | M+(m×N) | 1.3 hours |
| Block Nested Loop Join | M+(M×N) | 50 secs |
| Index Nested Loop Join | M+(m×C) | 20 secs |
| Sort-Merge Join | M+N+(sort cost) | 0.59 secs |
| Hash Join | 3(M + N)3(M+N) | 0.45 secs |