本文已收录到:CMU数据库系统学习笔记 专题
作业项目进度提示

并发控制
视频:https://www.bilibili.com/video/BV1eR4y1W7rW
本节讨论让数据结构具备并发安全的特点,尽管本节仅仅是介绍 B+ Tree 上的相关技术。在前两节中讨论的数据结构中,我们都只考虑单线程访问的情况,即只能有一个线程在同时刻访问我们的数据结构。现实中我们是希望多线程在同一时刻访问我们的数据结构。本节课讨论允许多个线程安全地访问我们的数据结构,现在的CPU都是多核,需要考虑到允许多个线程查询和更新。
-
逻辑正确性:(后续讨论)我希望看到的值是我期待看到的值!例如我插入了5这个值,等我插入完后回过头看,5这个值应该存在,而不会是false的。
-
物理正确性:(本节讨论)数据的内部表示是否完好?如何保证线程读取数据时该数据结构的可靠性?
锁
在数据库系统中有两种锁分别是Locks和Latches 。
- 数据库中特有的 Locks 一般是指行锁、范围锁、表锁这些。用来做事务之间的并发控制。是更为上层的抽象锁。
- Latches 就是在多线程编程、操作系统学习中遇到的多线程中接触到的锁,如
mutex、rwlock、semaphore、spinlockde等,来做线程之间的并发控制。是更为底层的锁。 - 我们这里主要研究Latches。
Latches的读写者模式
Latches 有读模式与写模式这两种模式,在读模式下又被称为“读锁”,在写模式下又被称为“写锁”,读锁就是我要读取这个数据,写锁的意思就是我要写入数据。
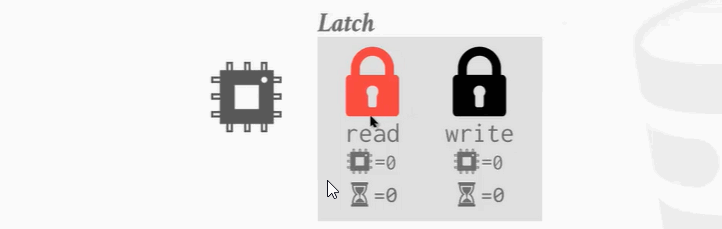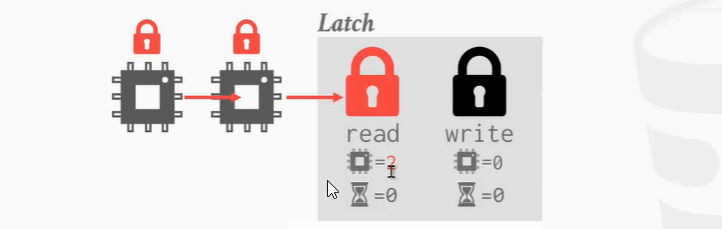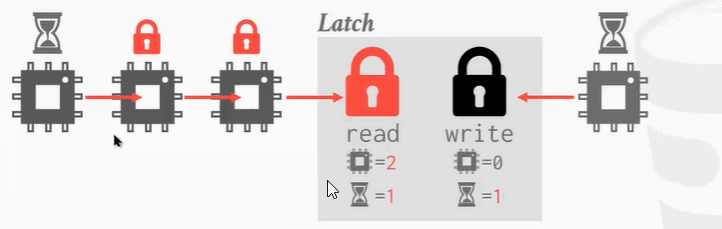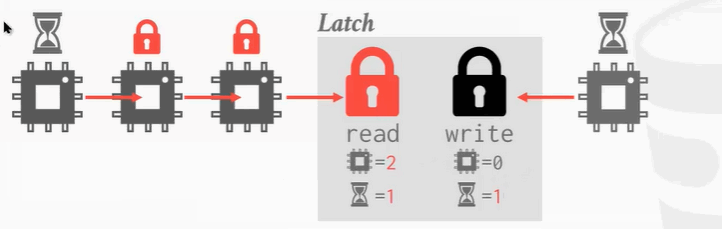
锁之间还有兼容的问题,很多类型的锁都有读锁和写锁两种模式,它们之间的兼容性问题如下图右侧2×2矩阵所示:

也就是说只有读锁的时候允许再读取数据。其他任何情况都不兼容。
实现方式
阻塞式操作系统互斥:
只要学过任何一门操作系统的课程,就会了解这种实现方式,可以参考下之前学过的清华大学操作系统课程。在编程语言层面就有现成的东西,C++中是 std::mutex。底层实现是由操作系统的mutex实现的。使用时只需要这样:

由操作系统提供给我们的操作系统级别的锁,使用它来完成项目是没有问题的,但如果使用的是高竞争系统的数据库系统就会有问题。下面来介绍下我们自己实现的方法。另一种实现方式是自旋锁,关于自旋锁部分可以参考清华大学操作系统同步互斥小节的笔记(这部分不展开讲了)。
Linux的创始人曾经说过:“不要在用用户态使用自旋锁,除非你知道在做什么。”,因为自旋锁在等待的过程中并不知道占用的之前的那个进程什么时候解锁,这有可能会陷入无限等待。
题外知识:Java中的同步互斥是先采用自旋锁,在等待规定时间后这个锁仍然没有被解开就使第二个线程陷入内核态休眠。
另一种方式是使用读写锁,关于读写锁方式可参考清华大学操作系统课程笔记同步互斥小节。下图表述过程:
- 第1个进程进来,加了一把读锁。
- 第2个进程过来,又加了一把读锁,因为读锁是兼容的所以可以加两把。
- 右边第3个进程过来想要加写锁,但因为不兼容,只能等待。
- 第4个进程过来了,想读,但是不可以,因为会对第3个写锁不公平,会使得第3个锁会被陷入饥饿状态。
Hash Table Latching
哈希表加锁很方便,因为加锁的方向都是一致的,所有人都是往同一方向走。如果哈希表需要扩容就给全局加一个锁。
哈希表加锁按照粒度分为 page latches 和 slot latches 。
page latches
特点:首先将哈希表分段的切开,分段加锁,一个线程操作的时候就给这一段加锁,具体这个段你叫作桶、叫做页什么都行,这里我称呼为一段。

步骤;
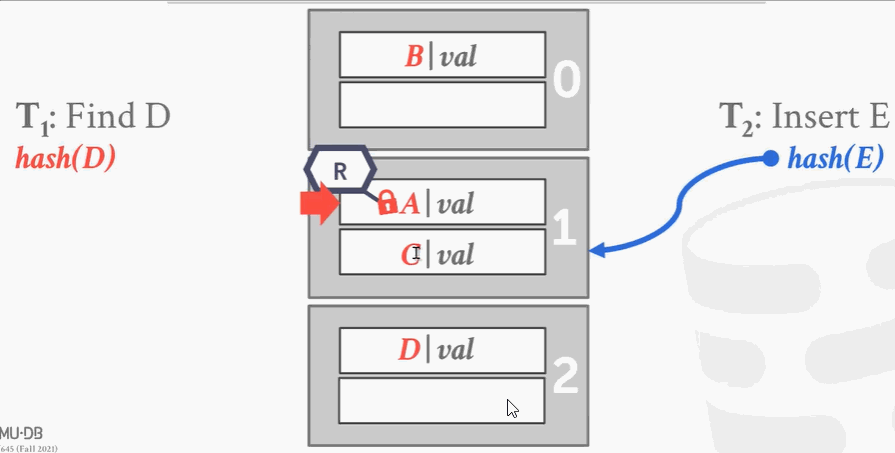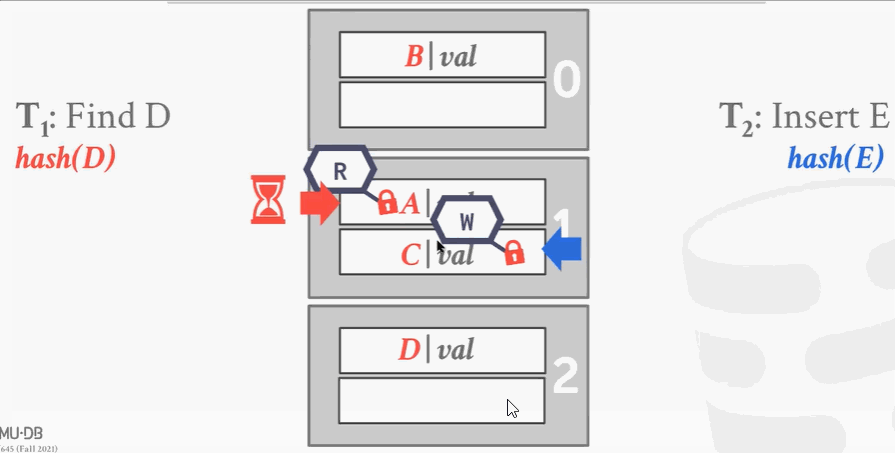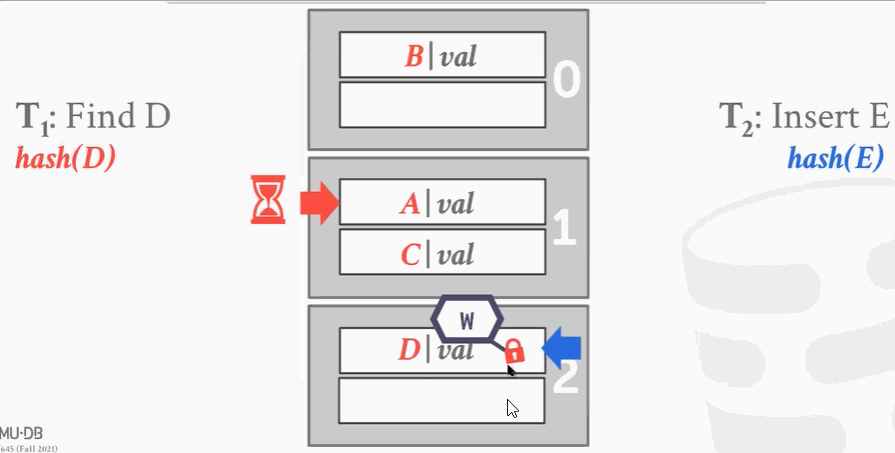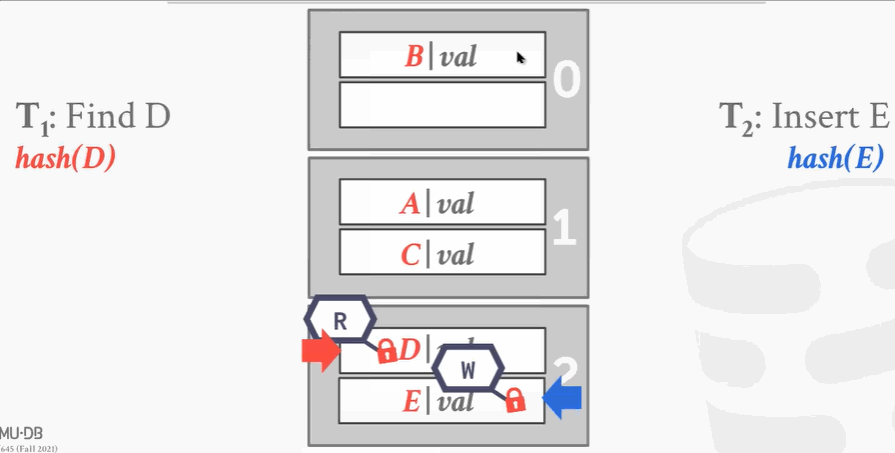
- 第1个进程想要查找D,经过hash发现D应该在A这个槽里,于是把这个段加读锁。
- 往下遍历的时候,这时候第2个线程来了想插入E,因为锁冲突加不上。
- 第1个线程往下走,解开读锁,给下面的段加上读锁。这时候第2个线程可以进来加写锁。
- 线程1完事了就解锁,线程2把最下面段加写锁,插入数据。
优点:粒度不是很细,维护不是很多的锁。
slot latches
特点:按照槽加锁。
过程:与之前的一样,只不过粒度更细,更能避免并发冲突,缺点是锁非常多。
其他的还有范围锁。
Go语言中的map处理方式是存在两个hash表,读写分离,其中一个主的哈希表是只读表,还有一个是写表,然后定期挪数据。好处是读的时候是无锁的。
原子操作 – 比较和交换
举个例子:现在有两个线程要同时给用户的银行账户加钱,如果不加以比较的话会导致重复加款,如果先前用户的余额是20元,存钱10元。第一个线程需要先比较确定余额是不20元,如果是的话就加10元,第二个线程同样也需要先比较再扣钱。这样就不会两个线程都操作,导致用户加了两次钱。
具体的原子操作是将整个业务操作告诉CPU,CPU去执行这样的操作:

B+ Tree Latching
B+Tree的并发操作与前面的一样,需要允许多线程的读和写。
- 结点内部的数据需要保护。
- 合并分裂的操作也需要保护起来。
B+Tree并发操作存在的问题:
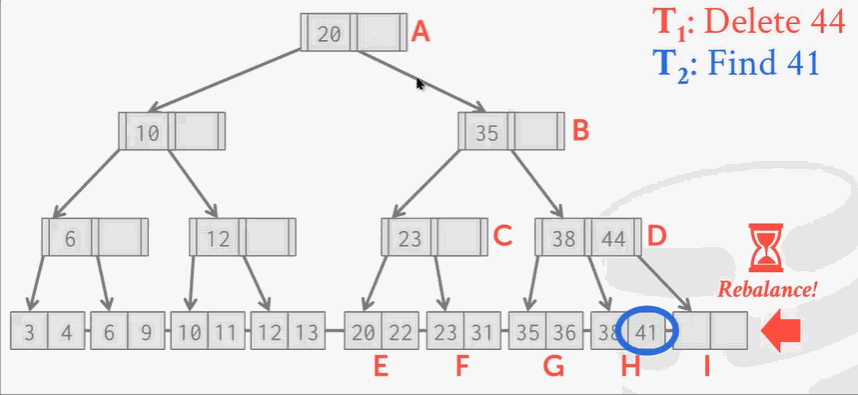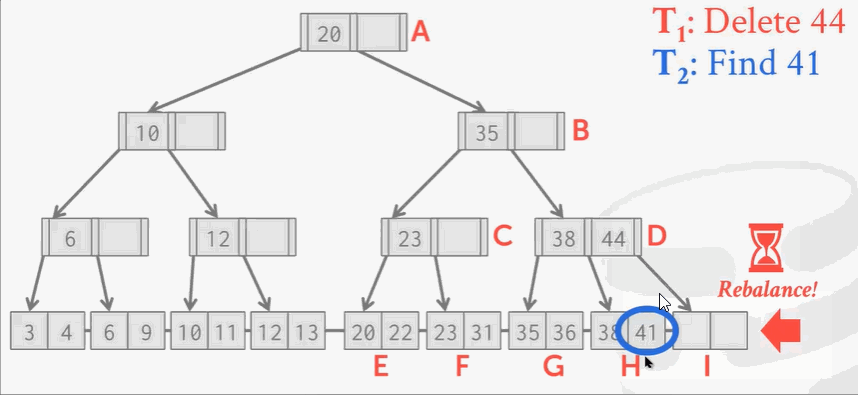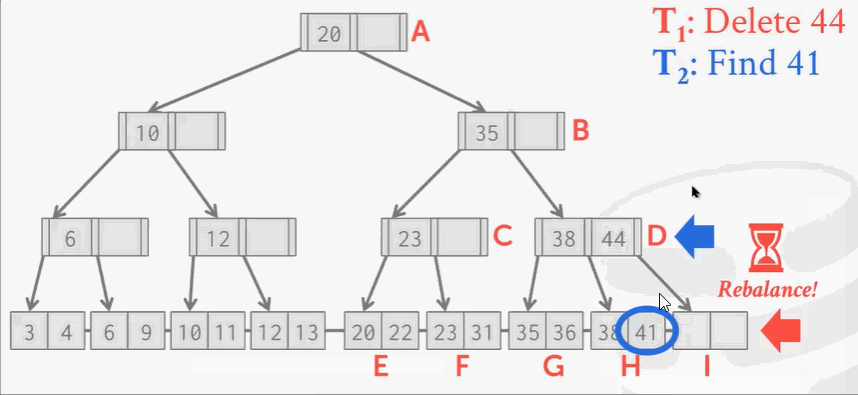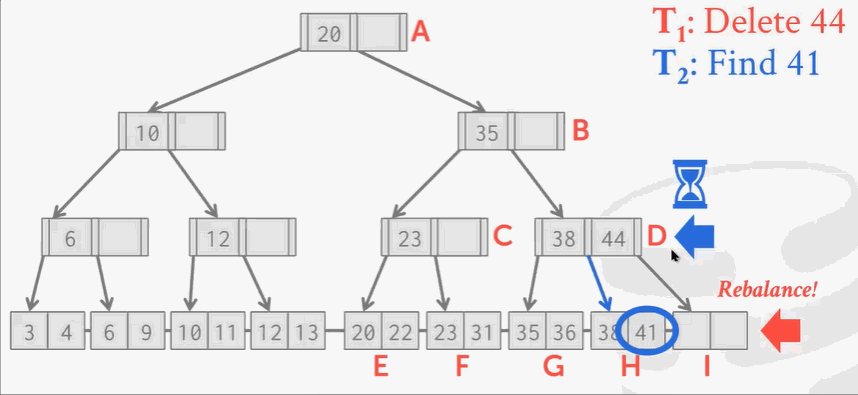
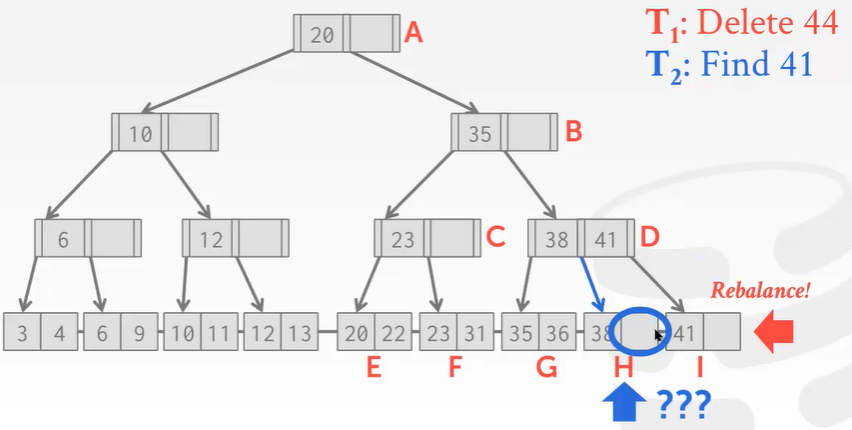
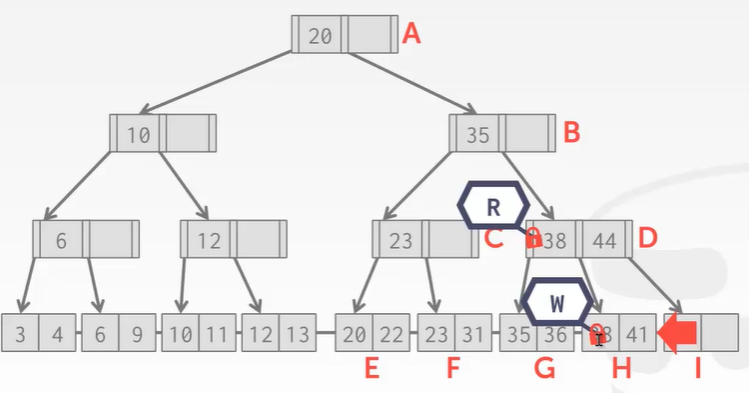
删除key 44:
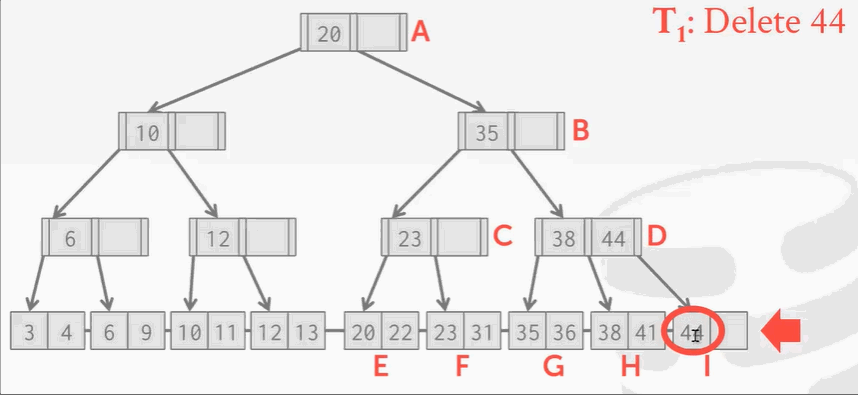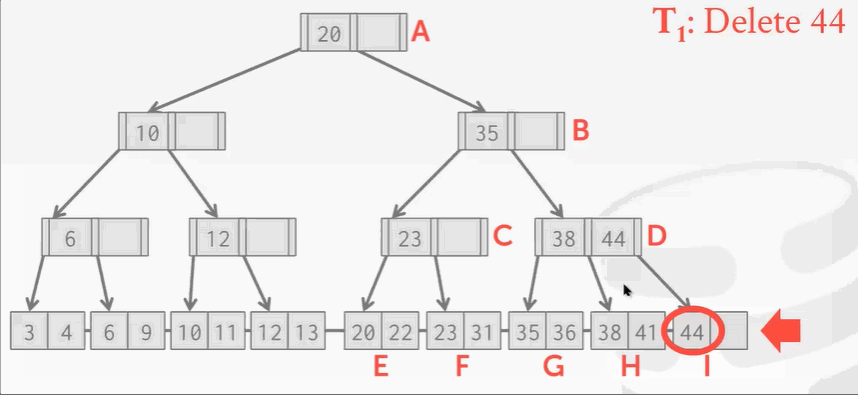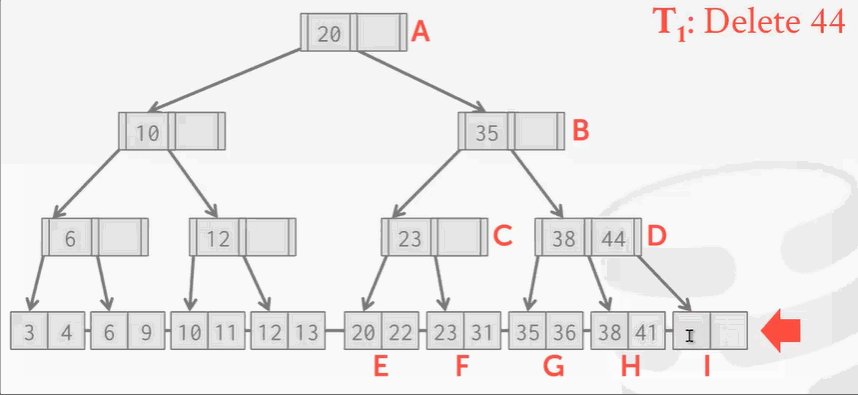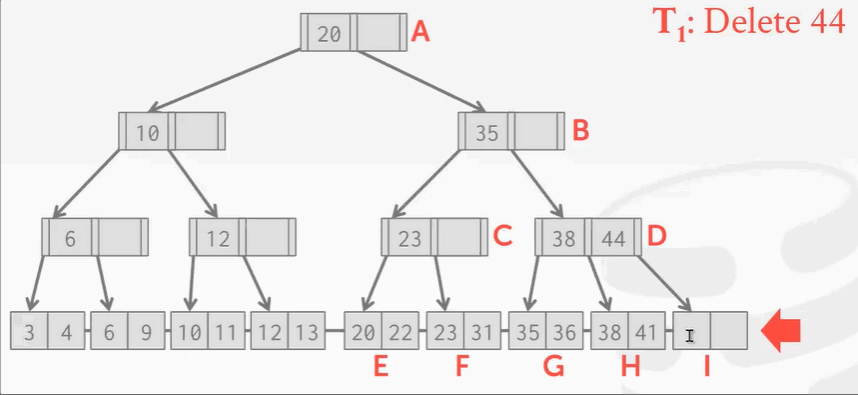
删除操作没什么问题,但是B+Tree在删除结点后需要再平衡。可回顾之前学的树索引删除结点知识。
现在I位置的结点被删除掉了,按照B+Tree的规矩,需要将H结点的key 41移动到右边。
现在来了另一个线程,刚找到41,准备读的时候… …
这时候… …T1线程把41移动过去了。
B+Tree并发 – CARBBING/COUPLING策略
B+树的并发控制策略是”crabbing/coupling”。
策略:
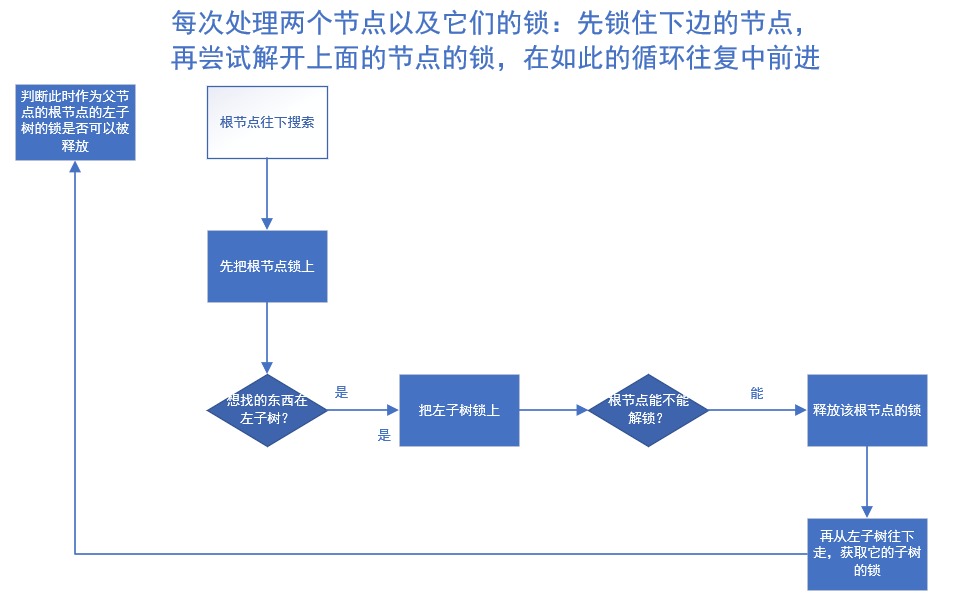
如何判断是否可以释放父节点的锁呢?就是去判断在这次的B+树更新中,是否会修改父节点的数据结构,也就是要去判断下面的子节点是否会发生分裂或合并。eg:查询就不会涉及到分裂合并问题。
如果是的话就会影响上面的父节点的指针以及某些Key/Value,因此不能释放上面父节点的锁。
如果能够确认下面的子节点不会进行分裂或合并,那么上面的父节点在本次对B+树的操作中不会再变化了,就可以释放它的锁,让别的线程去访问它。
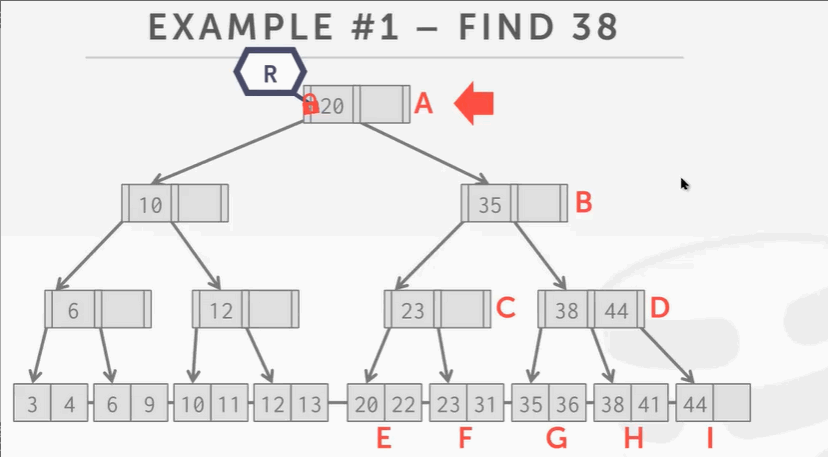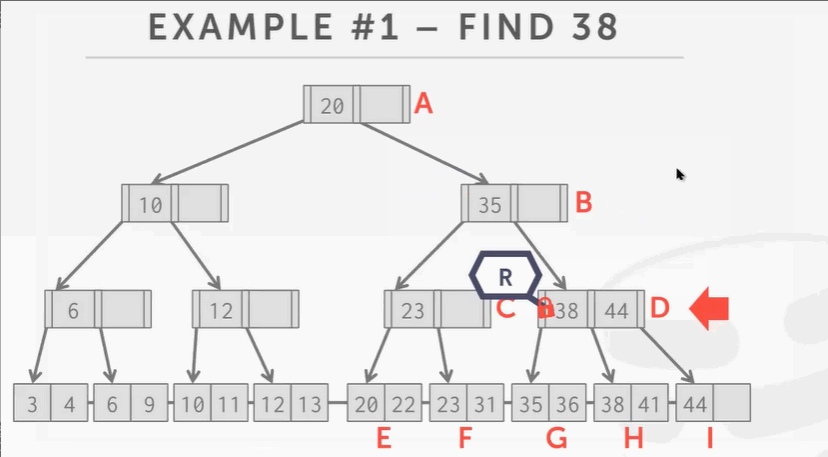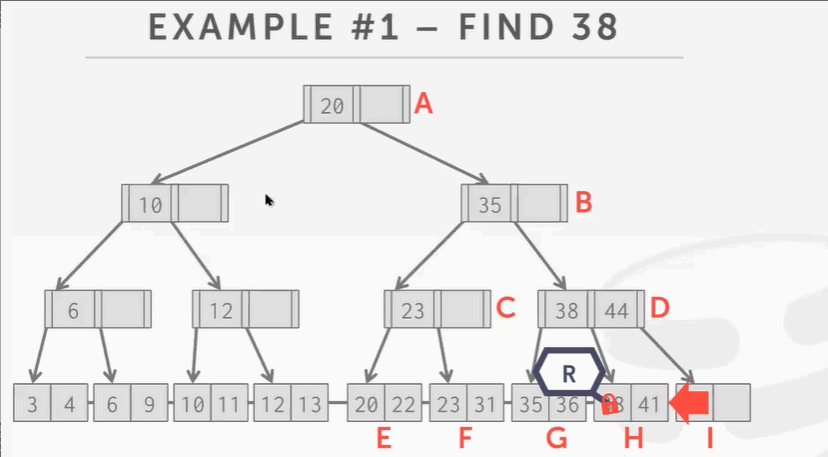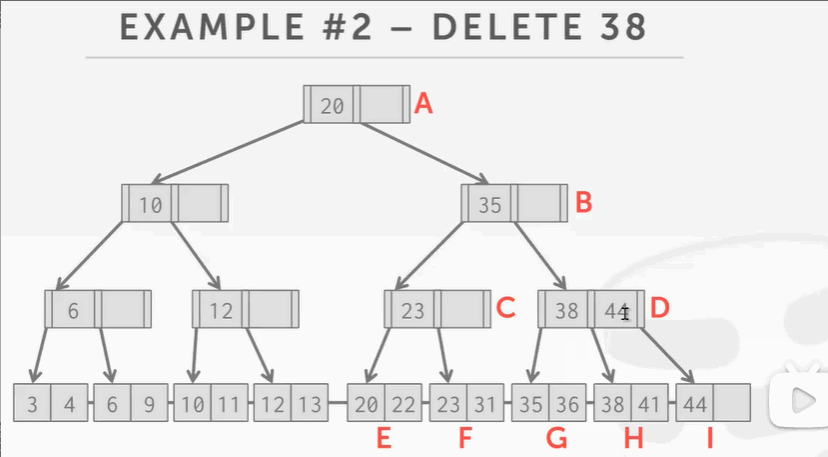
查找
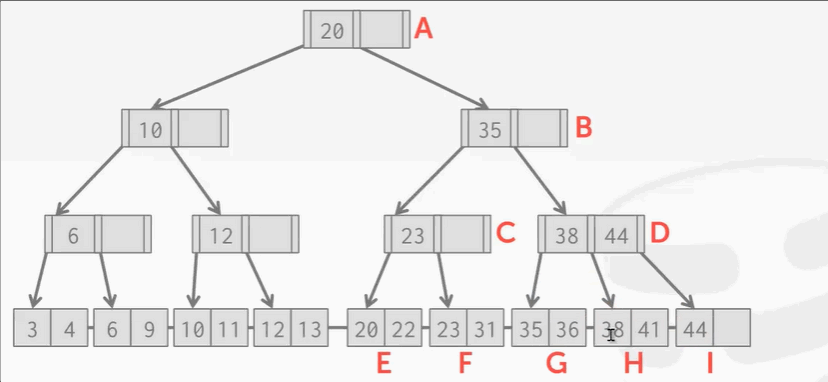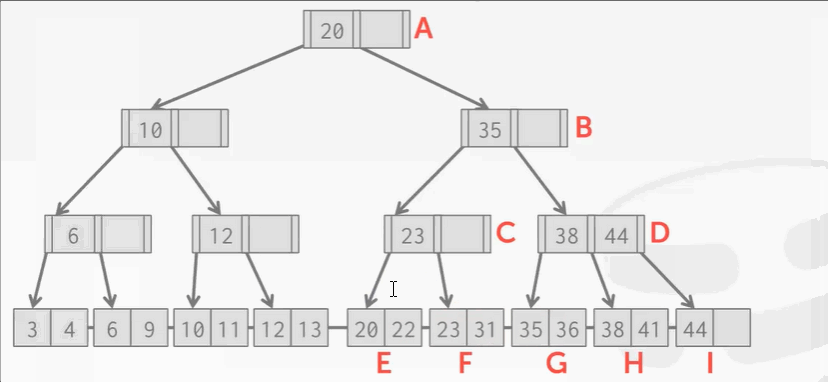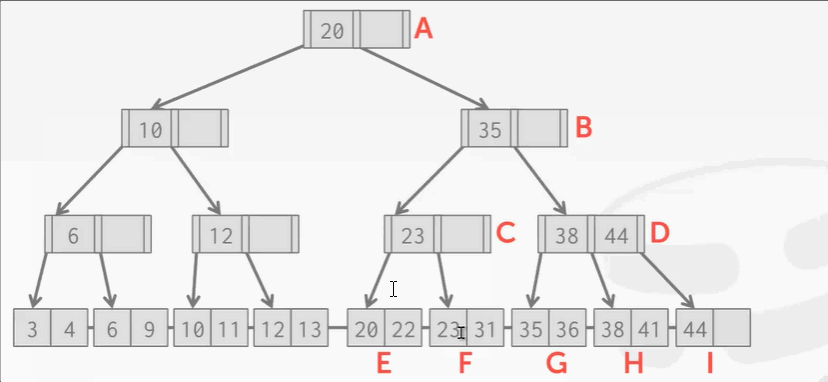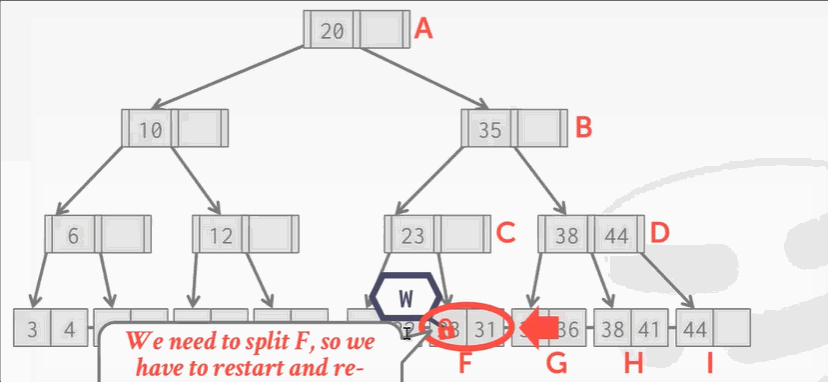
查找 key 38:
- 先锁根节点,然后顺着树往下找,锁B结点。因为B结点只是读不会产生分裂合并问题,所以可以解锁A根节点。
- 往下爬,锁D释放B。
- 锁H释放D
删除不会导致合并操作的key
删除38步骤:
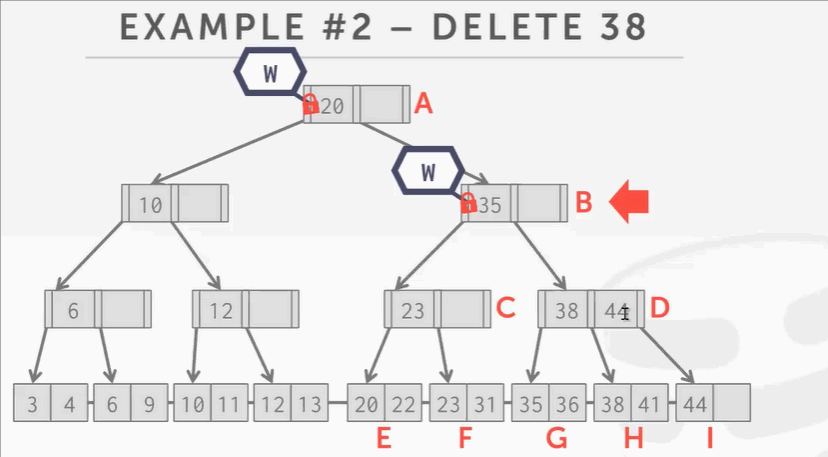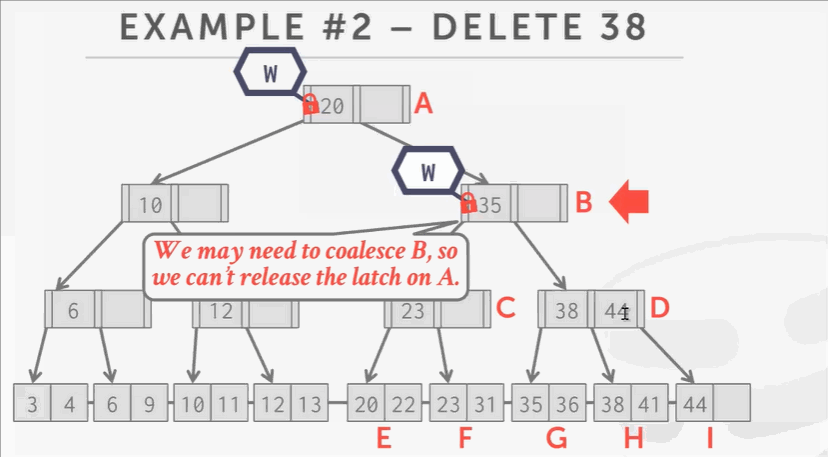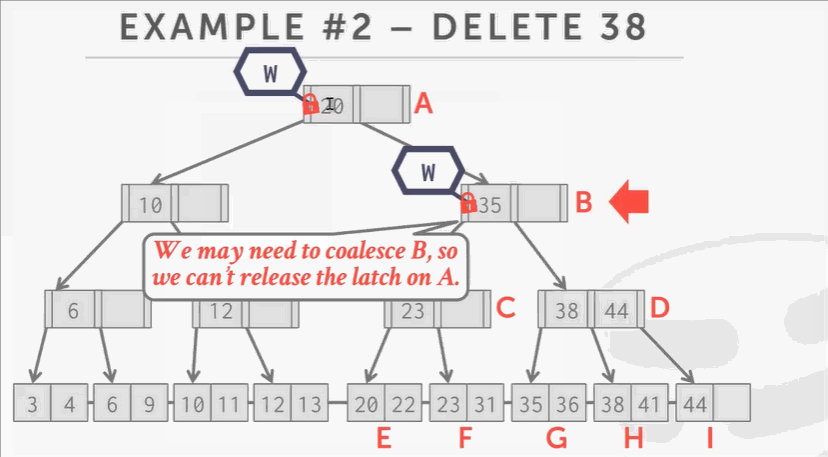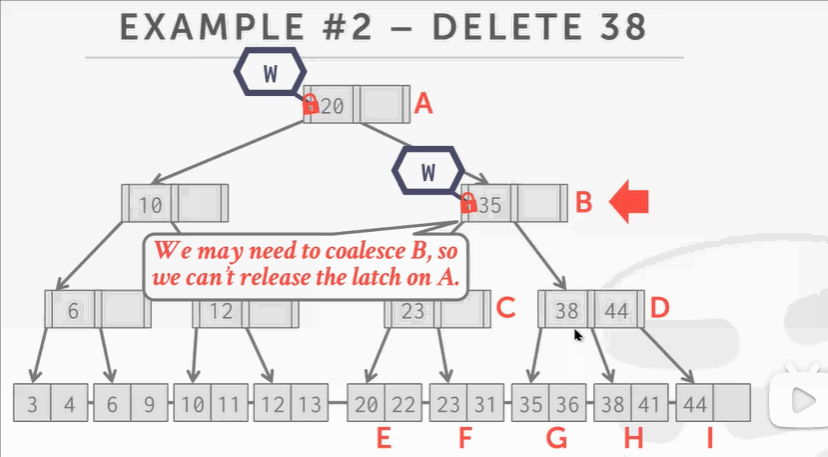
- 根节点上写锁,然后往下爬,给B结点上写锁。这时候并不敢释放A结点的写锁,因为我不知道删掉38后会不会导致C D结点合并,会不会影响到B结点,以至于影响到根节点A。
- 观察C结点,key 38无论删除还是不删除,都不会对B产生影响。因为C D结点至少是半满的,根据B+Tree的删除规则,是不会触发合并操作的。参考:B+Tree删除操作。所以可以释放B A的锁。
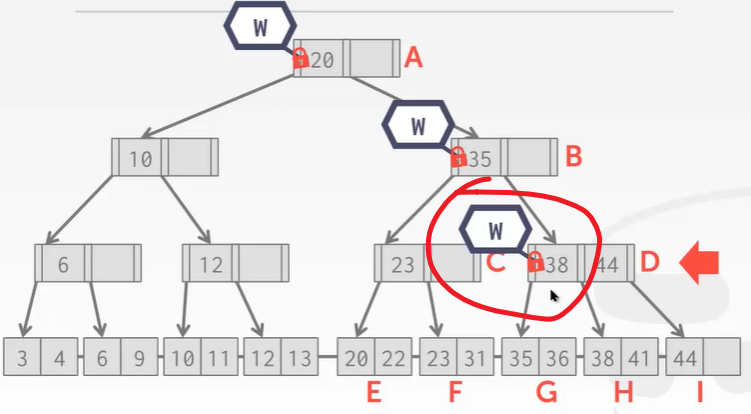

- 接下来为叶子节结点上写锁,父节点的锁可以解开:
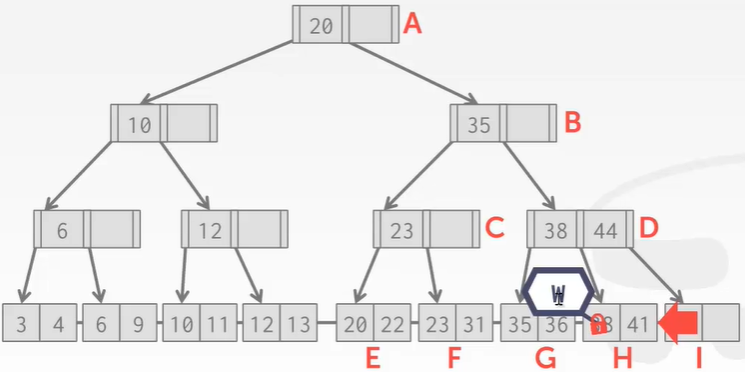
插入不会导致结点分裂的key
插入45:
- 根节点上写锁,往下爬,B结点上锁。到了B结点,想解开A结点的锁可以吗?——可以,因为B结点下面的叶子结点就算分裂了,B结点也有位置存放指针。所以大胆的给A结点解锁。
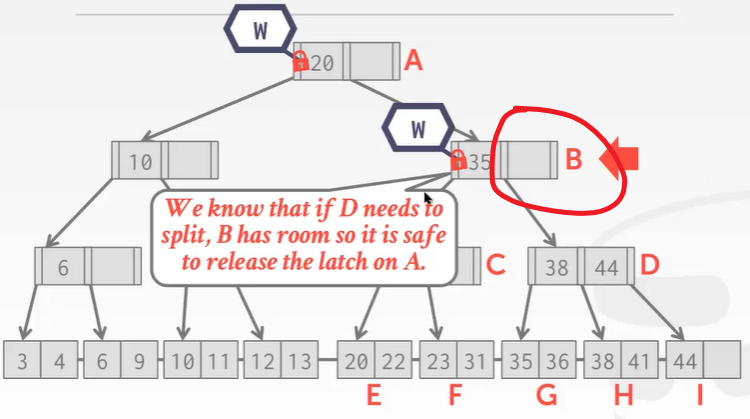
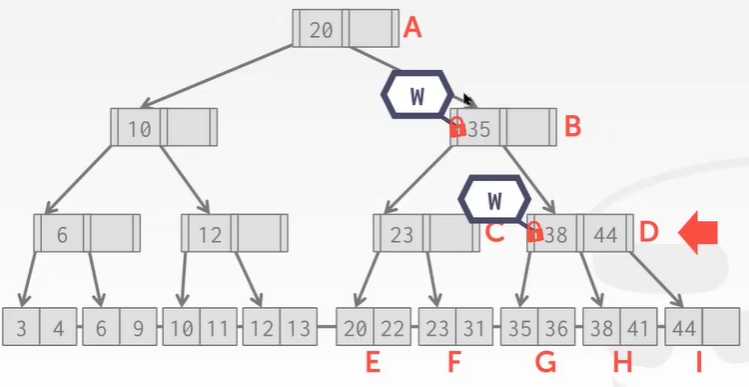
- 往下爬,到了叶子结点发现I结点有空位,不会导致上面的D结点分裂。所以可以解开B 和 D的锁:
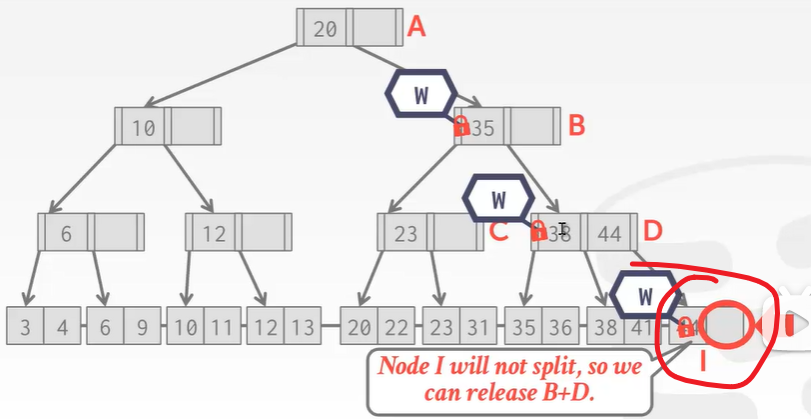

插入会导致结点分裂的key
插入25:F结点不够放了,不能解开C的锁。
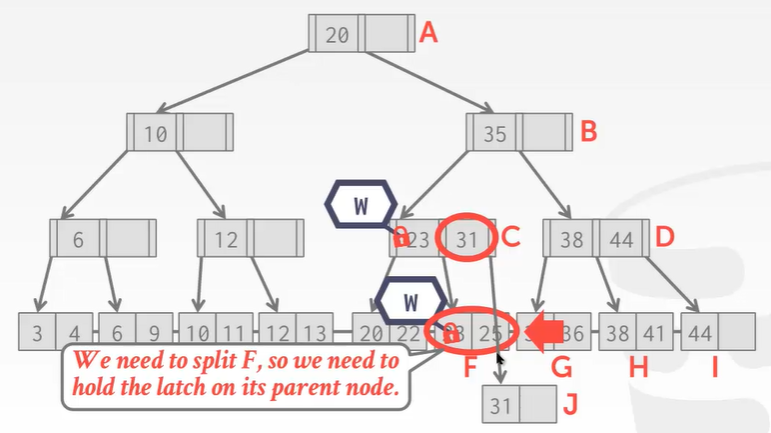
观察发现,上述操作都无一例外需要动根节点,这在大规模并发操作的时候根节点就是系统的瓶颈。我们可否做改进?
乐观锁
之前我们要锁根节点都是基于我们怕将来要动根节点。但是,我们对数据库的绝大部分操作是动不到根节点的、我们对一个叶子结点的操作是很少引起根节点的变化的。
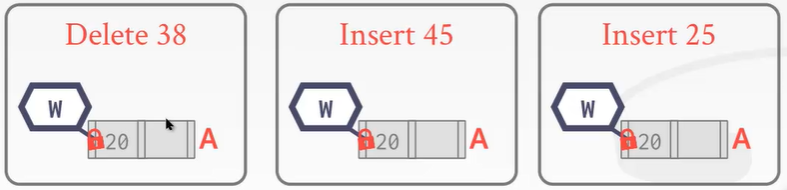
我们之前上锁显得太悲观了。故上述的方法上锁又叫做——悲观锁。下面来说乐观锁。
我们假设大多数的操作是不会引起根结点的变化的。改进:不加写锁,加读锁。虽然我要删除数据,但我也加读锁大,到了我真正要操作的叶子结点再加写锁:这里删除38对树没任何影响。
有时候乐观过头了,例如插入25,遇到了分裂的操作。怎么办?
答:回滚,重新从根节点爬,这次像之前悲观锁那样上写锁。
叶子结点的扫描可能会出现死锁问题
B+Tree支持叶子结点的扫描,现在有两个线程并发,就可能会出现死锁问题。具体体现在线程1想要读B但是被线程2上锁,线程2想要读C但是被线程1上锁了。。。但幸亏这里是两把读锁,读锁是兼容的,但如果是写数据就会出现死锁问题。

解决办法:B+Tree 的锁天然不支持死锁检测,所以在编程的时候要改进一些规则,例如像哈希表那样规定顺序。
MySQL就是倒序遍历不支持这样走,是通过倒倒序引实现的倒序遍历。