本文已收录到:清华大学操作系统课程笔记 专题
进程和线程
进程和程序之间的关系?
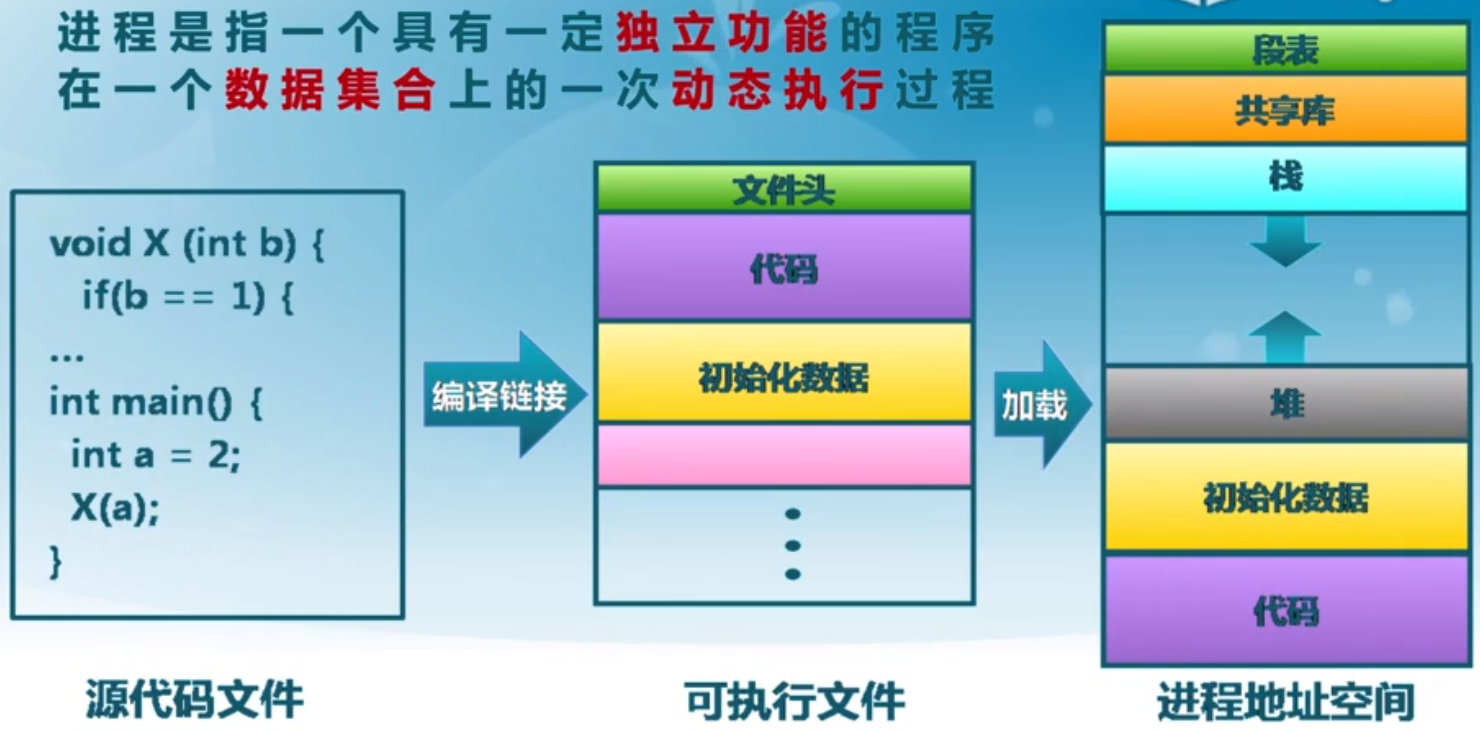

操作系统对进程的管理,有一个很关键的数据结构叫。 ,实际上就是一个结构体。每个变量就是一个进程。
,实际上就是一个结构体。每个变量就是一个进程。
保存的东西包括:
- 进程的ID
- PC
- 状态信息
- 寄存器信息
- 内存管理信息
- 核算信息
- IO状态信息
等等…..

进程的特点:


可以交替执行多个程序,在宏观上体现在并发性。


Ps:这一块可参考孙志岗的笔记。
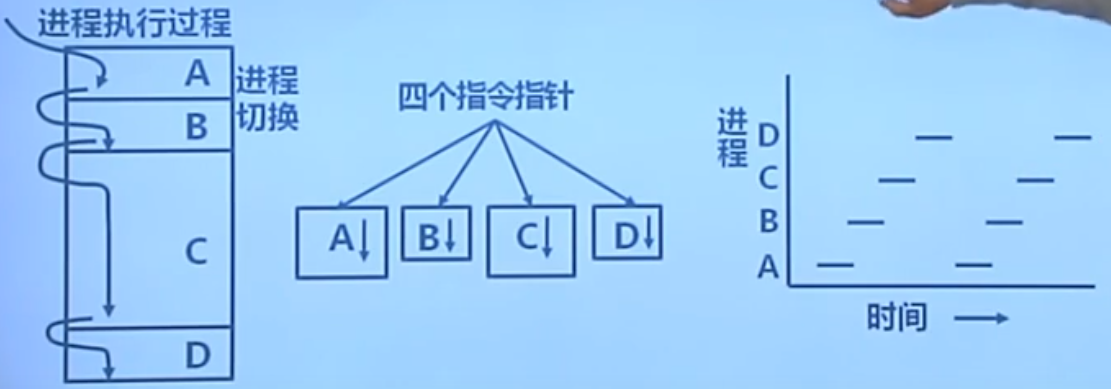


进程
进程控制块(PCB)

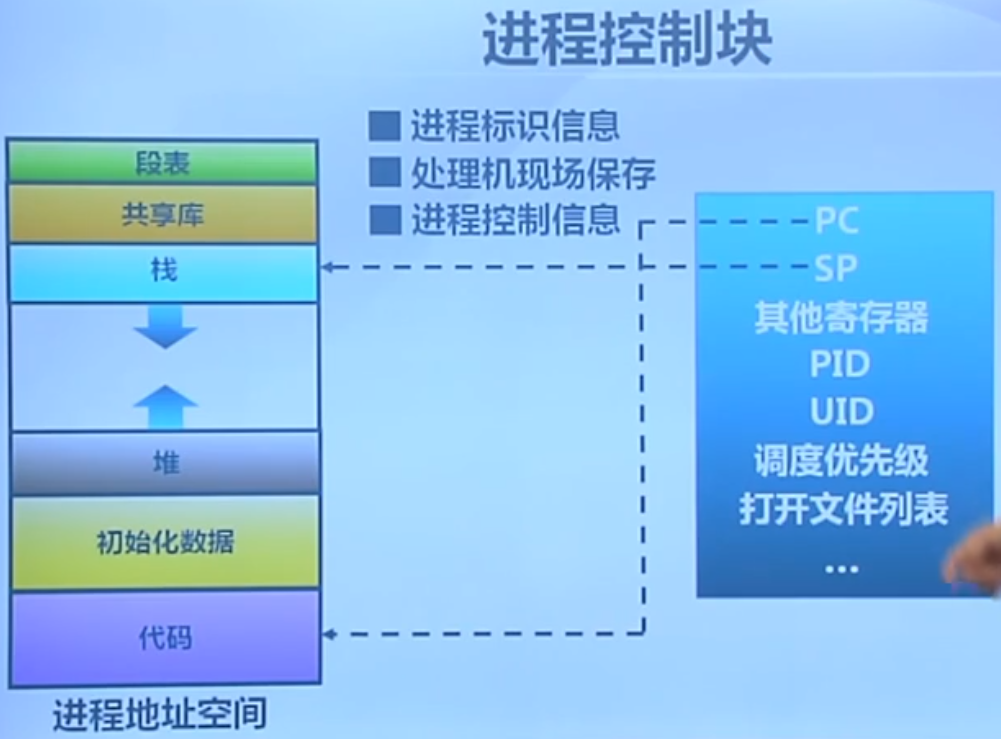

如何管理这些进程?
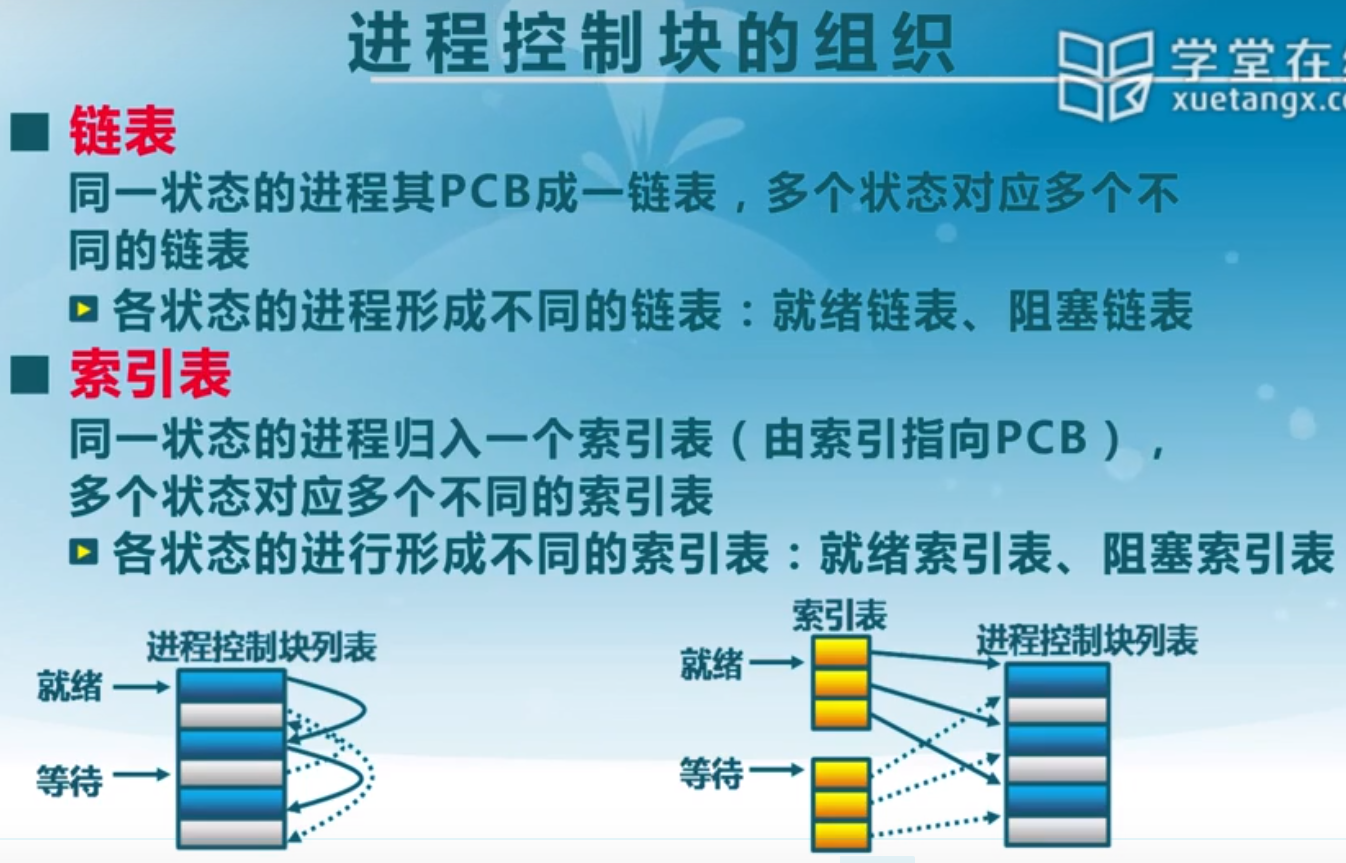
在后续的实验中我们会看到具体的进程控制块里都有什么。
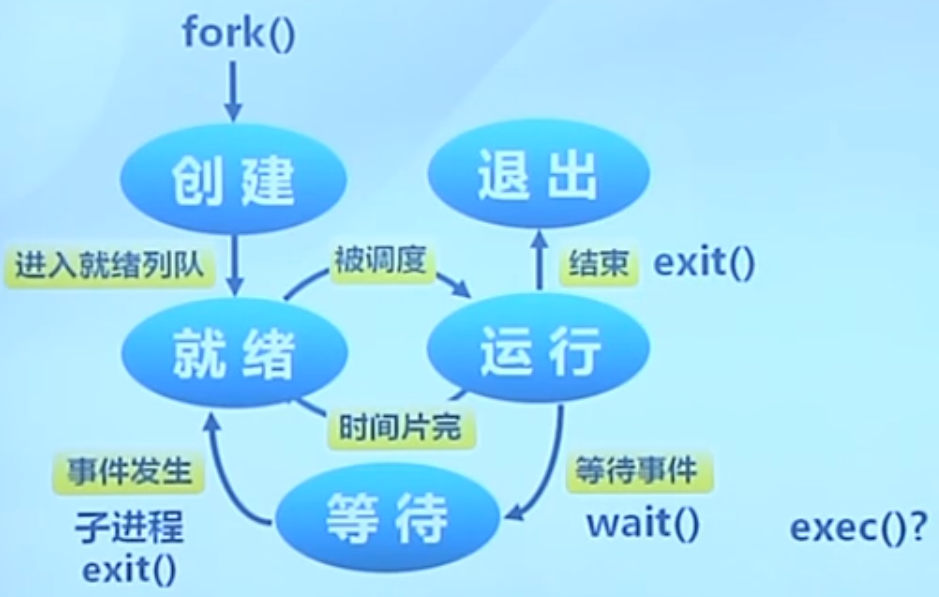
进程状态

Ps:需要注意的是,在不同操作系统中,进程的生命周期的划分可能是不同的。
进程创建

进程执行
创建好进程之后,会放在内核里的就绪队列中,这时候进程控制块PCB就放在队列中,等待CPU调度。调度就会导致进程处于运行状态。
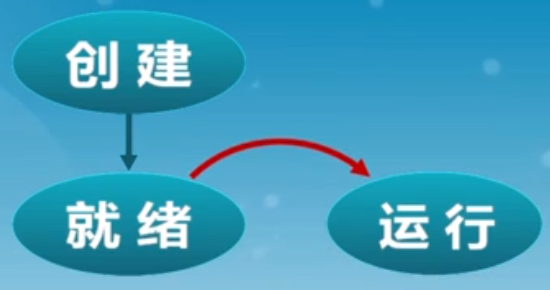

如何选择就是调度算法所研究的东西了。
进程等待(阻塞)
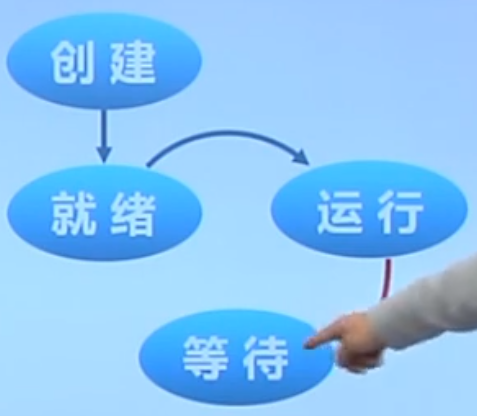

![]()
等待(阻塞)是进程自己的原因所导致的,不是外部原因。
进程抢占
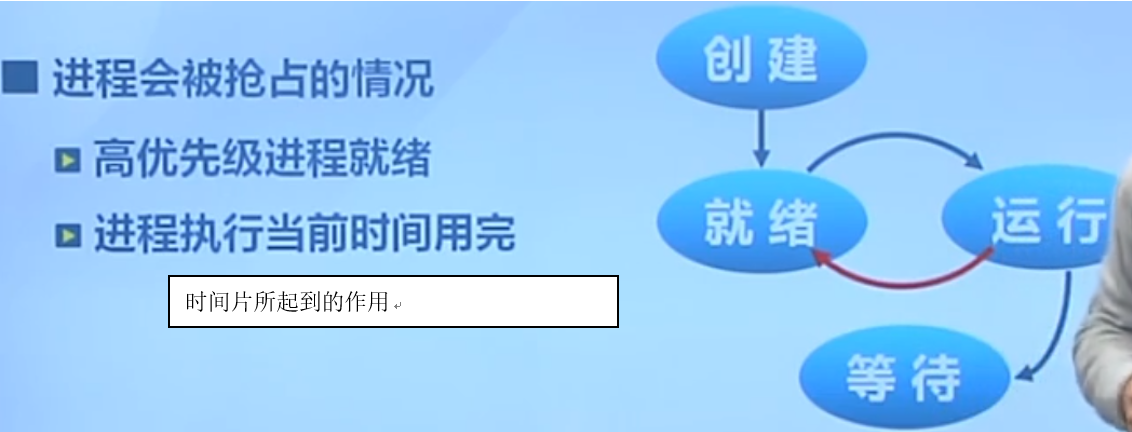
进程唤醒
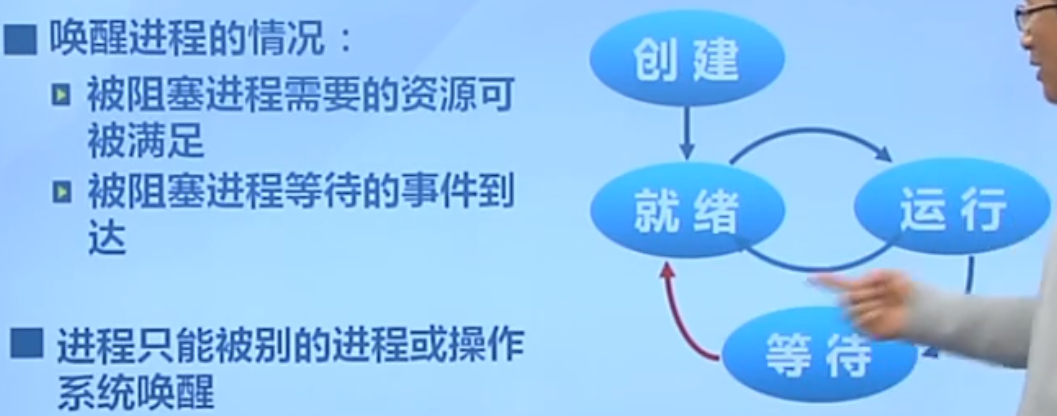
进程结束

三状态进程(进程生命周期中最重要的三个核心状态)
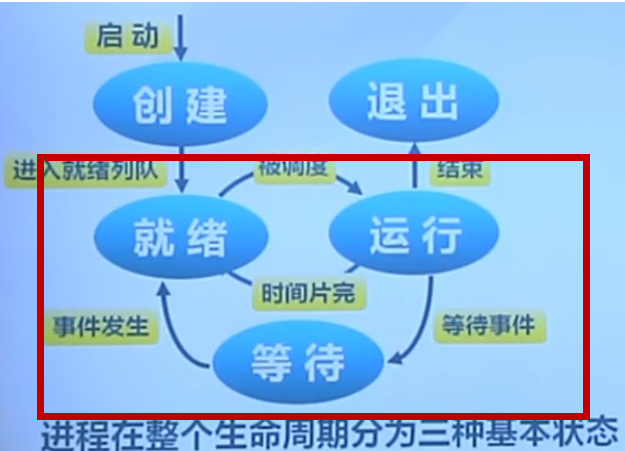
红色框是三状态,是整个进程生命周期中最核心的三个状态。
挂起进程模型
有一部分进程的存储是放在外存中的。 ![]()
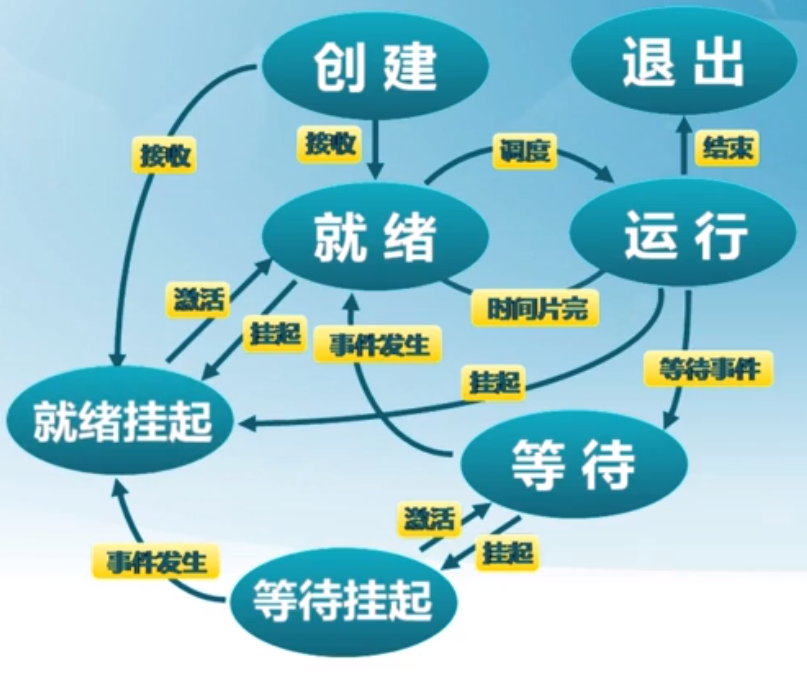
新增加的两种状态——就绪挂起和等待挂起,就是为了描述在外存当中的状态。


进不到内存中的原因是内存空间不够或者优先级不够高。





状态队列

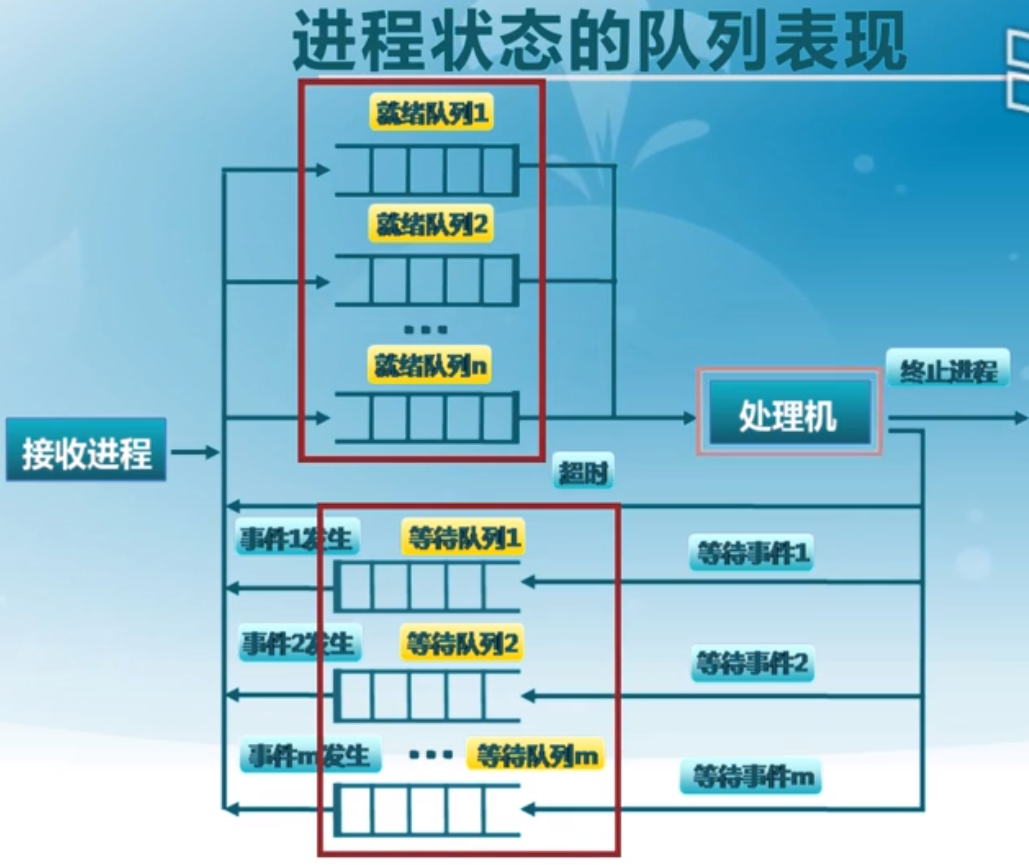
线程
为什么引入线程?

用单进程的方式实现:

我们期待这三个步骤可以并行执行。于是将其拆分为三个程序:


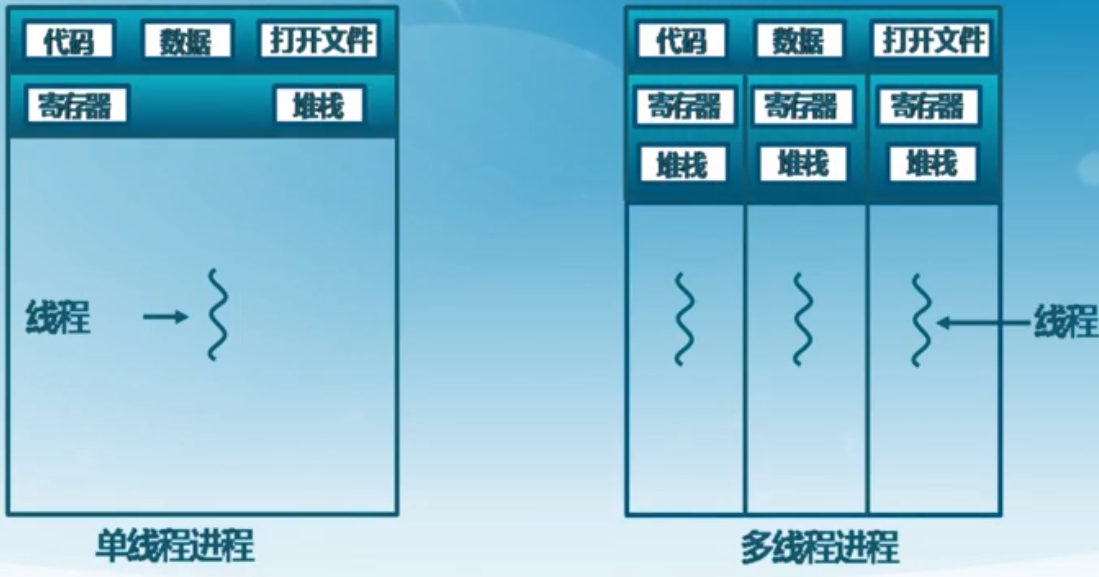
之前我们讨论的进程,主要目的是让不同的进程块儿之间隔离。
但是现在:我们需要更好的共享数据。怎么办?
答:如果他们都是在一个进程的内部,就会好很多。


进程与线程的关系:


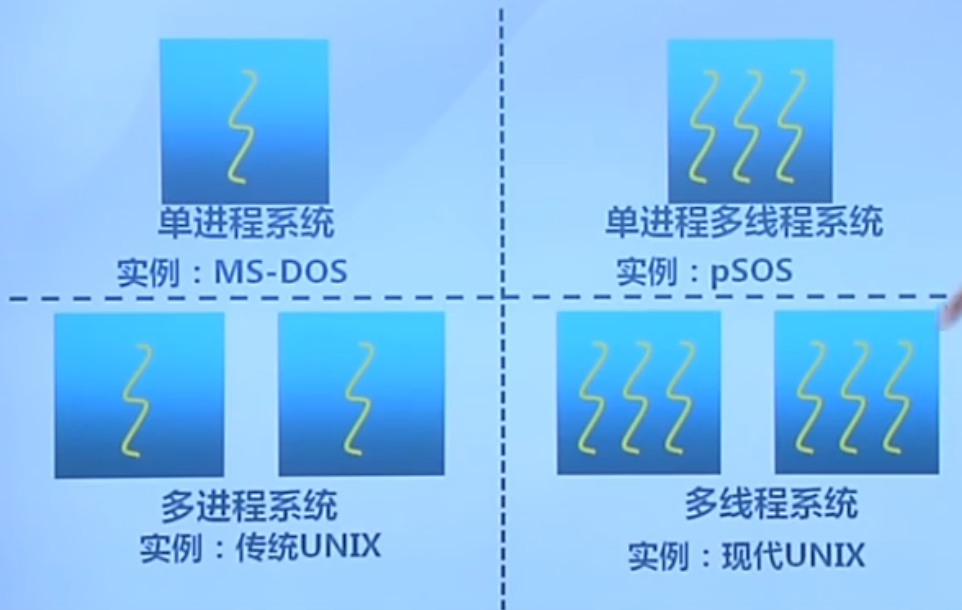
不同操作系统对线程的支持

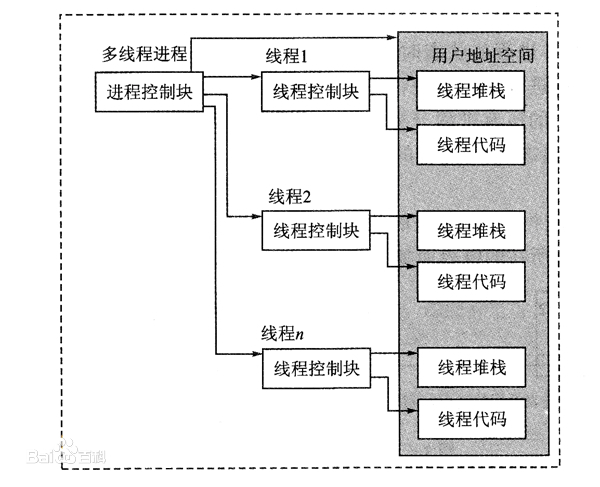
线程的实现

用户线程



内核线程

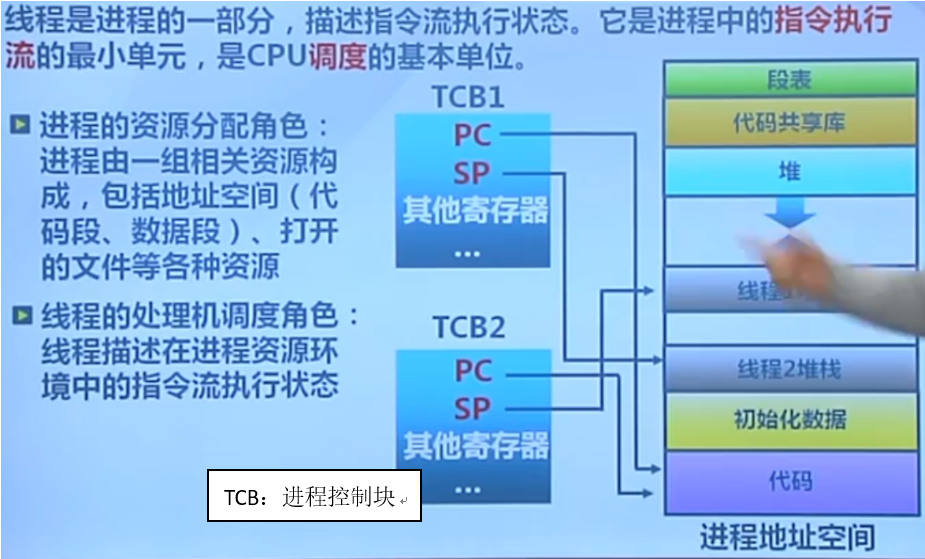
PCB:进程控制块
TCB:线程控制块
内核线程由内核控制进程控制块和线程控制块。使得严格意义上来讲进程是资源分配的单位,线程是处理机调度的单位。
进程是资源分配的单位,线程是处理机调度的单位。

轻权进程
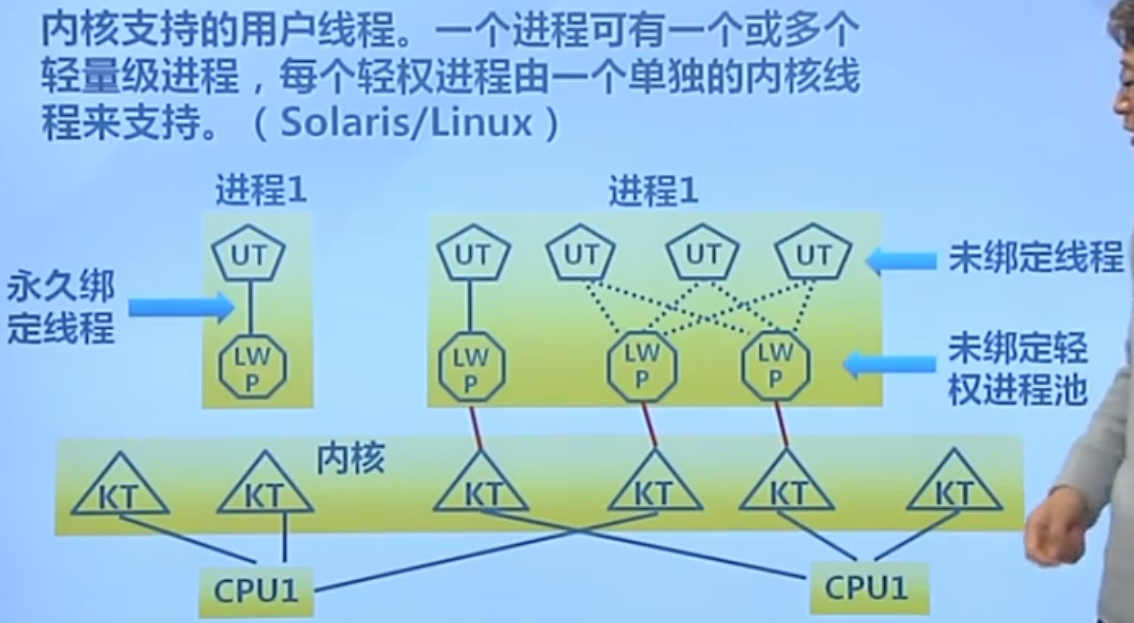
最后经过尝试发现效果不是很理想,没有充分发挥优势,最后solaris改为单一的内核进程。

目前来看,第一种一对一的做法是比较好的。
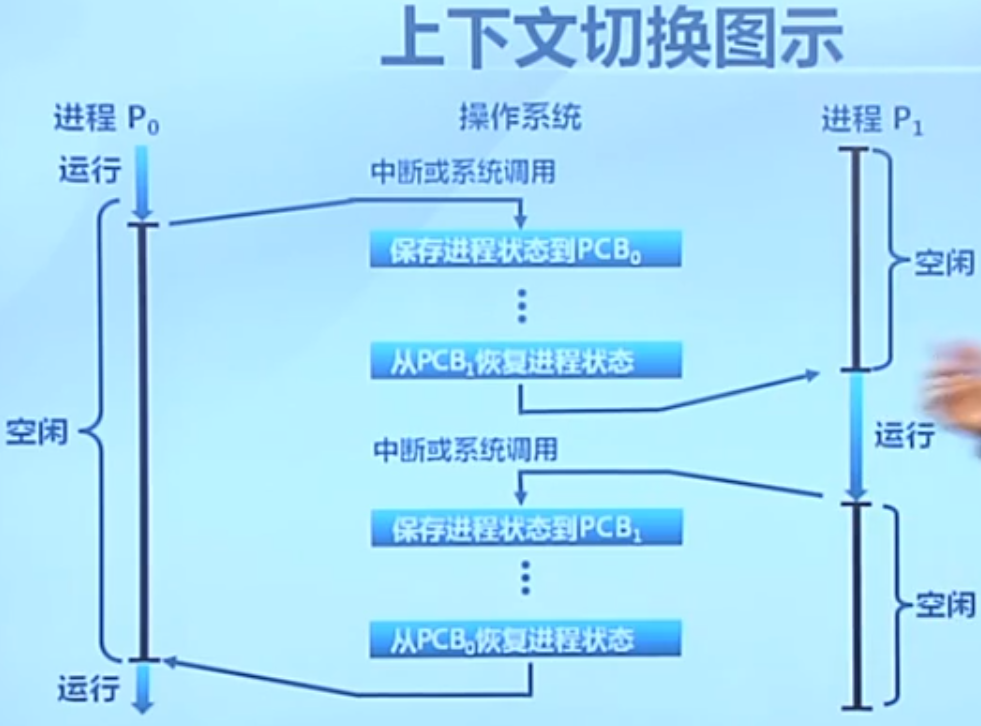
进程切换(context)

现代计算机中进程切换是十分频繁的,大概10ms就会切换一次。为了保证效率,切换速度必须非常快(必须使用汇编实现)。
要保存下面的信息:

内存地址空间的大部分内容不要保存。本来就是独立使用的。
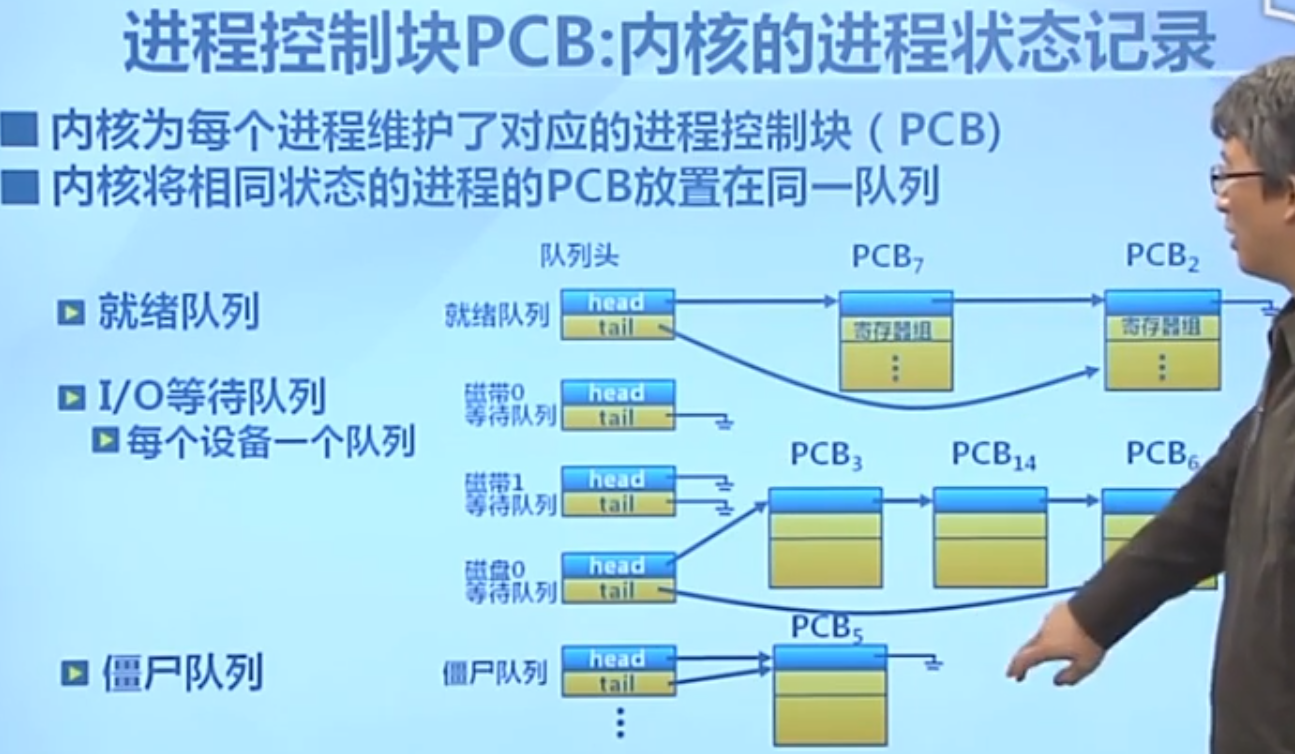
ucore的进程控制块结构:
P57讲 7:00

struct proc_struct {
enum proc_state state; // 进程的状态
int pid; // 进程id
int runs; // the running times of Proces
uintptr_t kstack; // Process kernel stack
volatile bool need_resched; // 是否需要调度
struct proc_struct *parent; // 父进程
struct mm_struct *mm; // 进程的内存管理数据结构
struct context context; // 上下文
struct trapframe *tf; // 中断保护现场
uintptr_t cr3; // CR3 register: 页表的起始地址
uint32_t flags; // 标志位
char name[PROC_NAME_LEN + 1]; // Process name
list_entry_t list_link; // Process link list
list_entry_t hash_link; // Process hash list
};
内存地址空间的数据结构:
// the control struct for a set of vma using the same PDT
struct mm_struct {
list_entry_t mmap_list; // linear list link which sorted by start addr of vma
struct vma_struct *mmap_cache; // current accessed vma, used for speed purpose
pde_t *pgdir; // 一级页表的起始地址
int map_count; // 如果有共享的话,共享了几次
void *sm_priv; // 置换 的数据结构
};
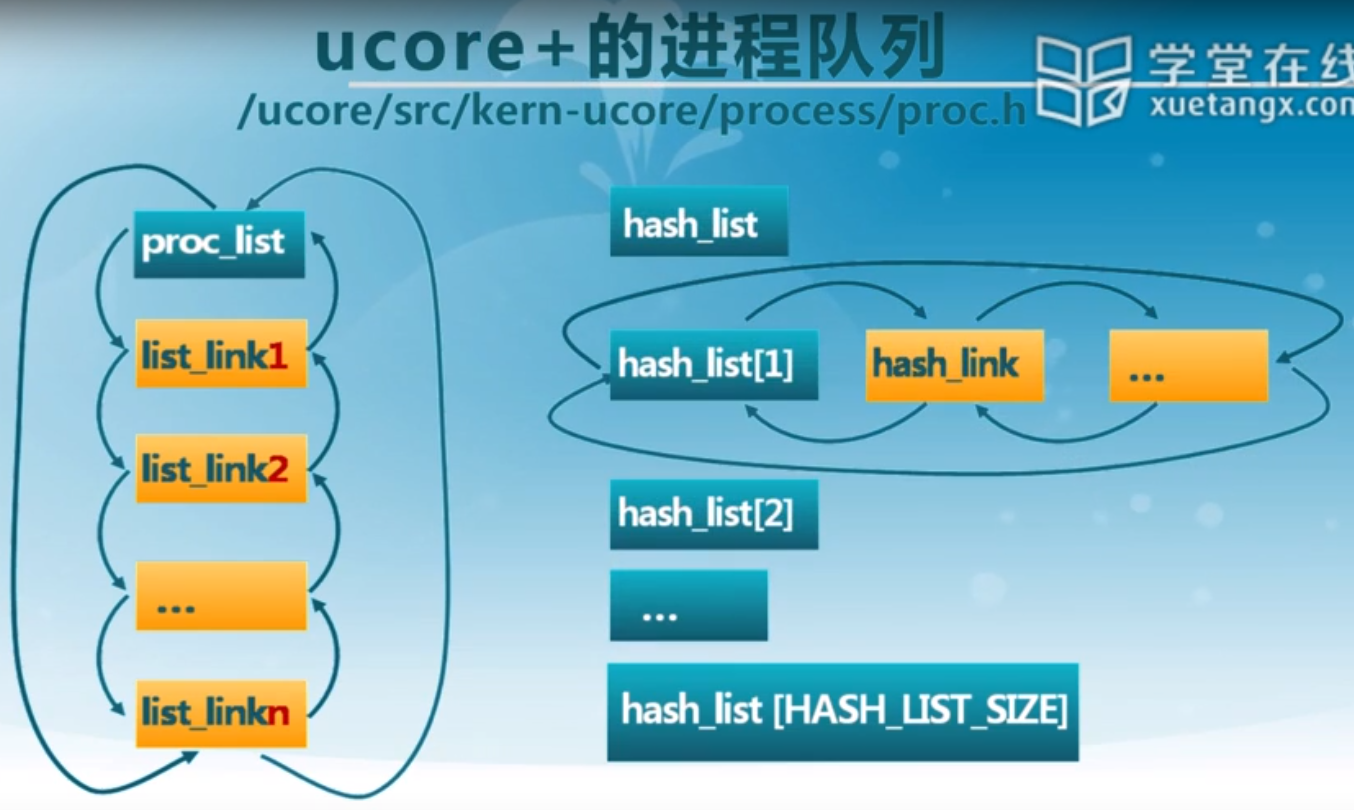
proc.h文件中采用双向链表,但如果非常长的话开销就会很大。所以我们又采用了哈希表。

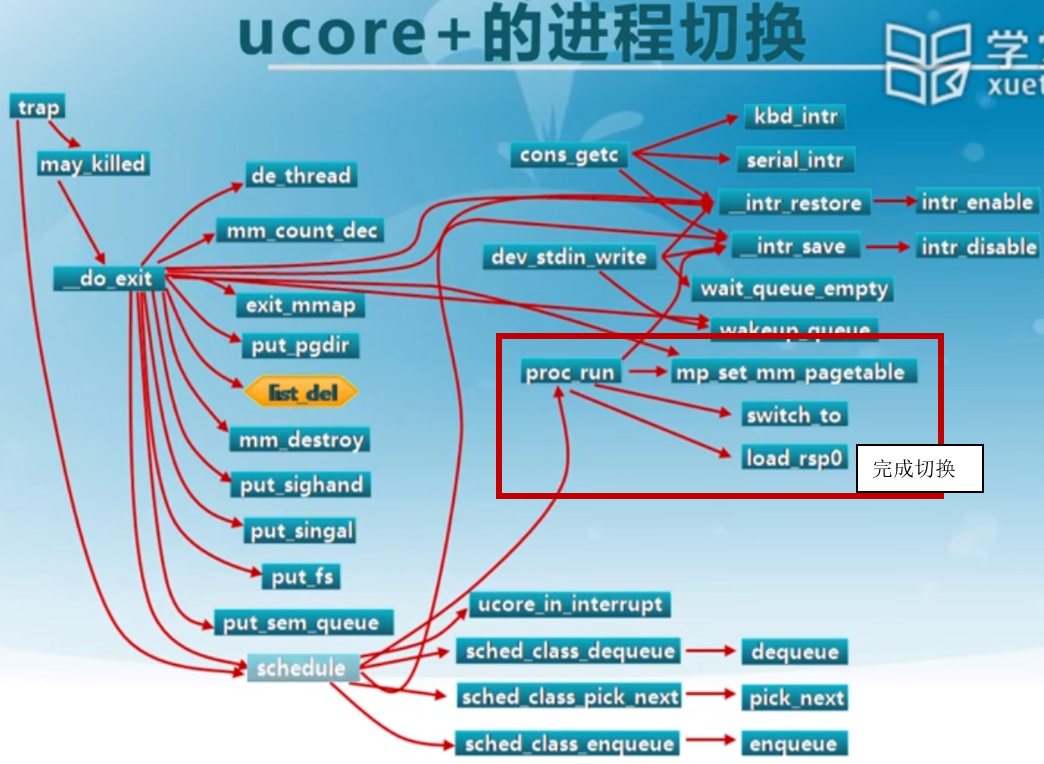
切换代码的实现:
使用的是汇编,与具体的CPU平台相关。因为每个CPU平台上所需要保存的寄存器信息是不一样的。

大概格局就是保存、切换和恢复。
实际切换函数的实现:
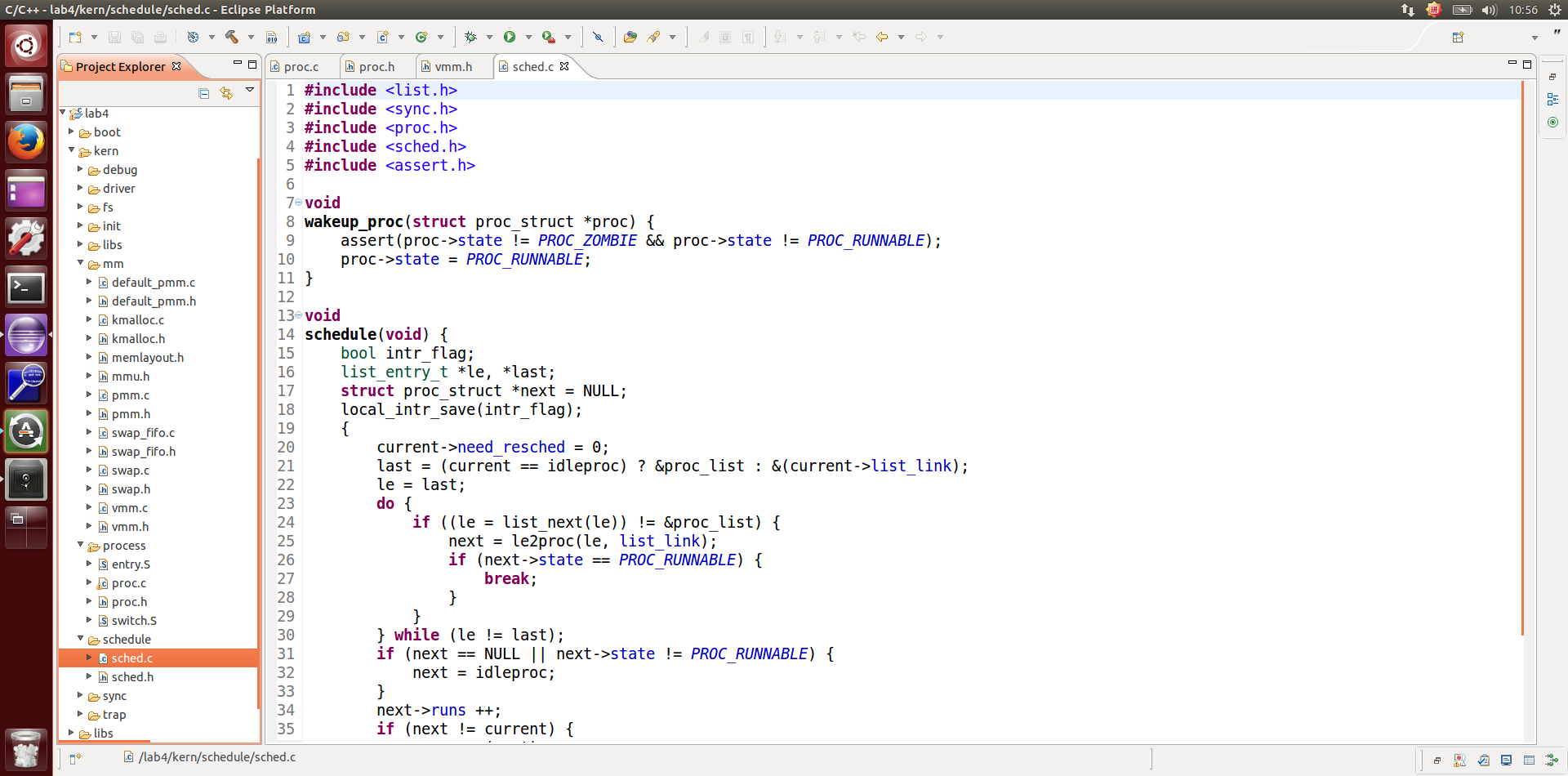
切换的时候会改进程的状态:
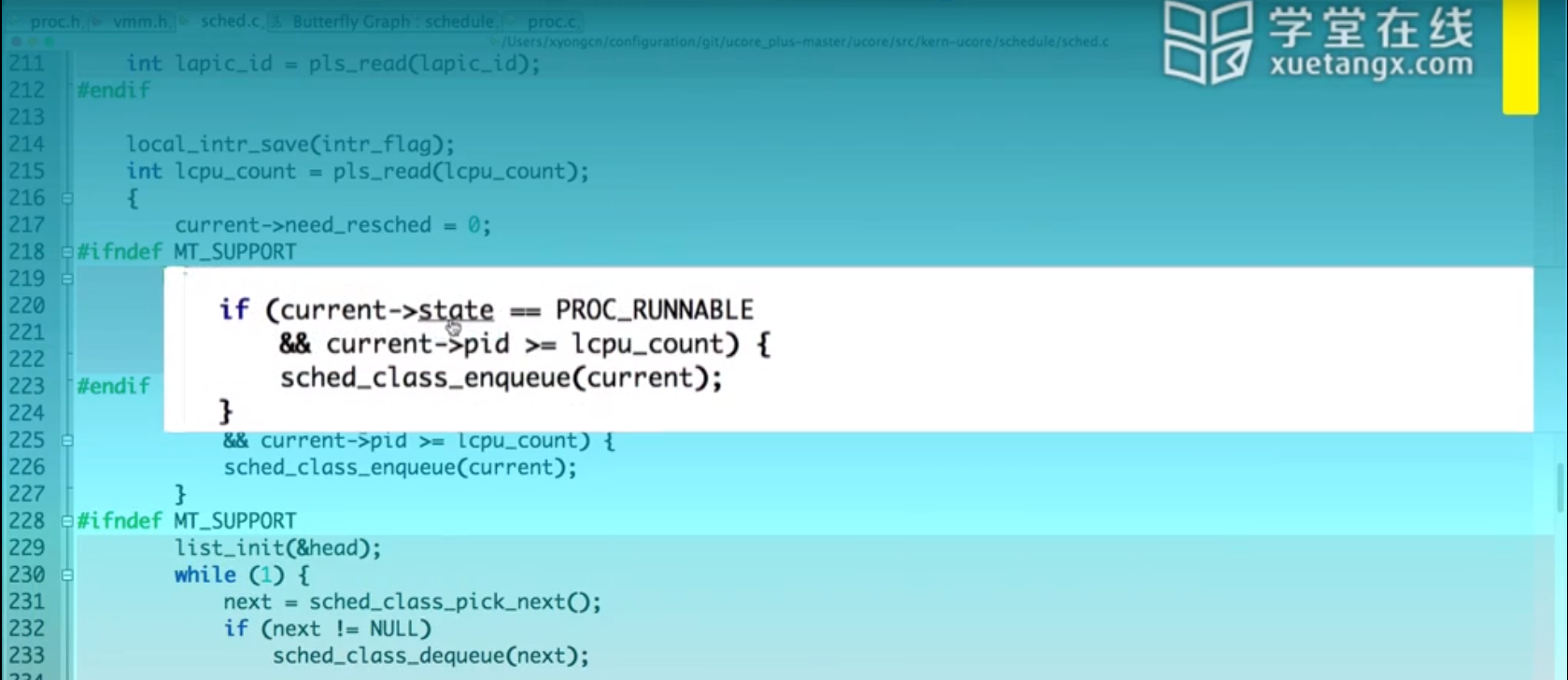
选择下一个被调度的进程:
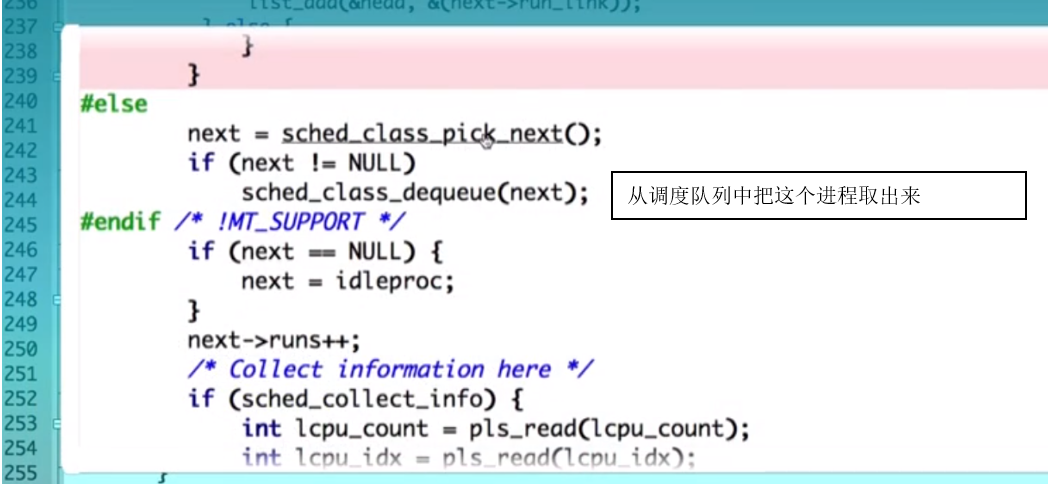
进程创建
进程创建是操作系统提供给用户的一个系统调用。
在windows操作系统中:

在Unix中:

创建新进程


可用getpid()方法获取pid。
fork()地址空间的复制(父进程生成子进程)


父进程生成子进程是完全的复制,只有PID不同。
程序加载和执行


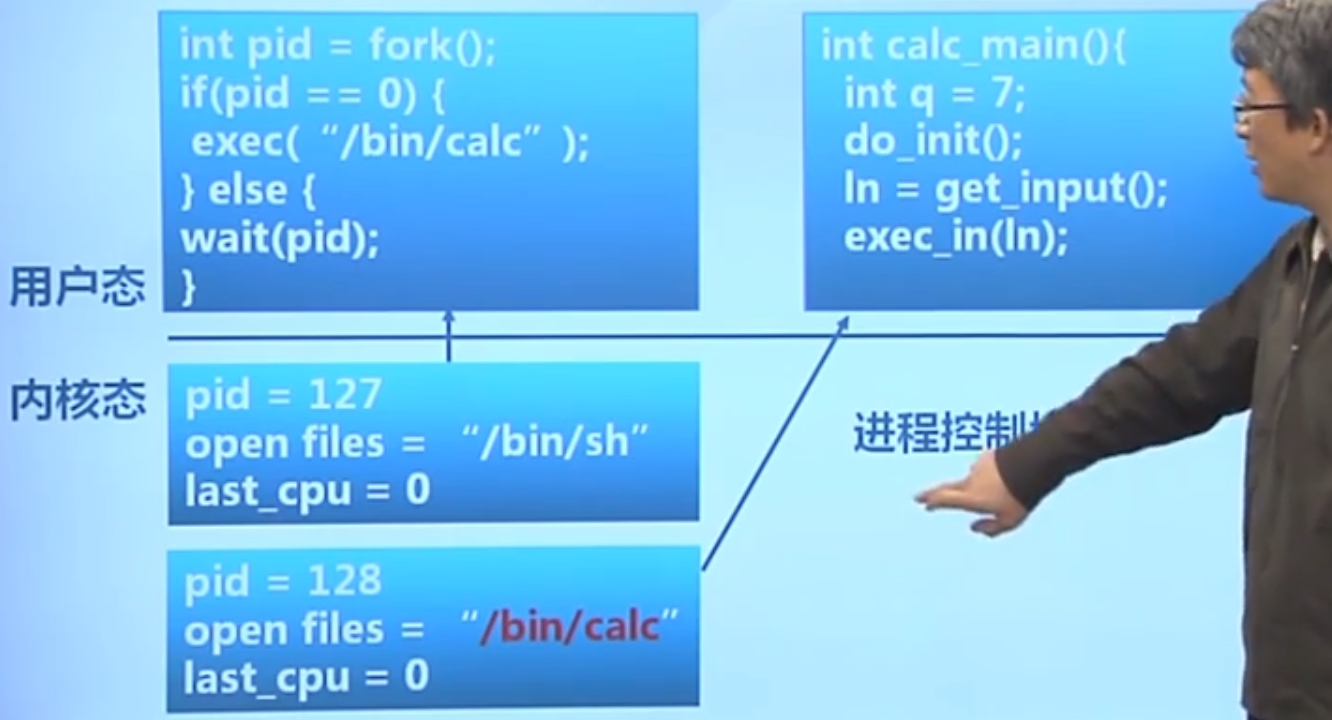
eg:
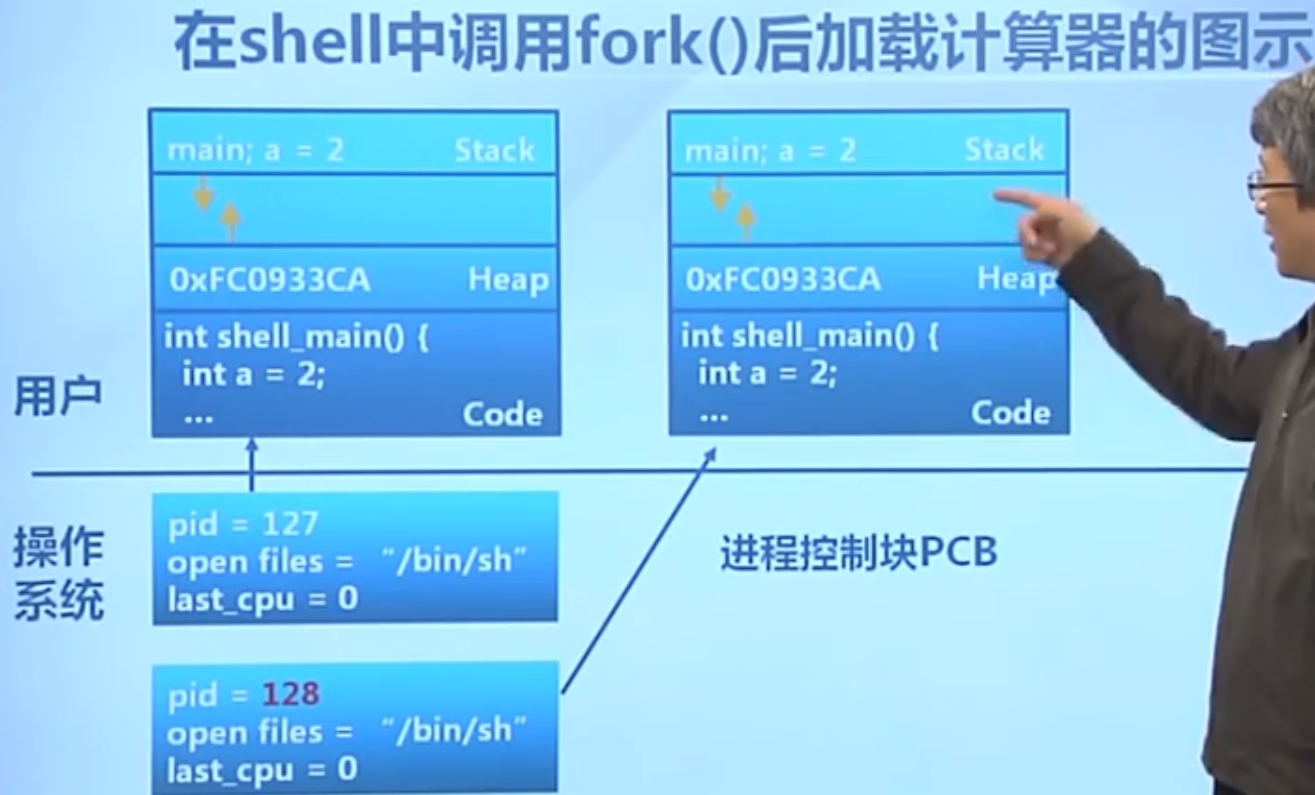
fork使用实例:
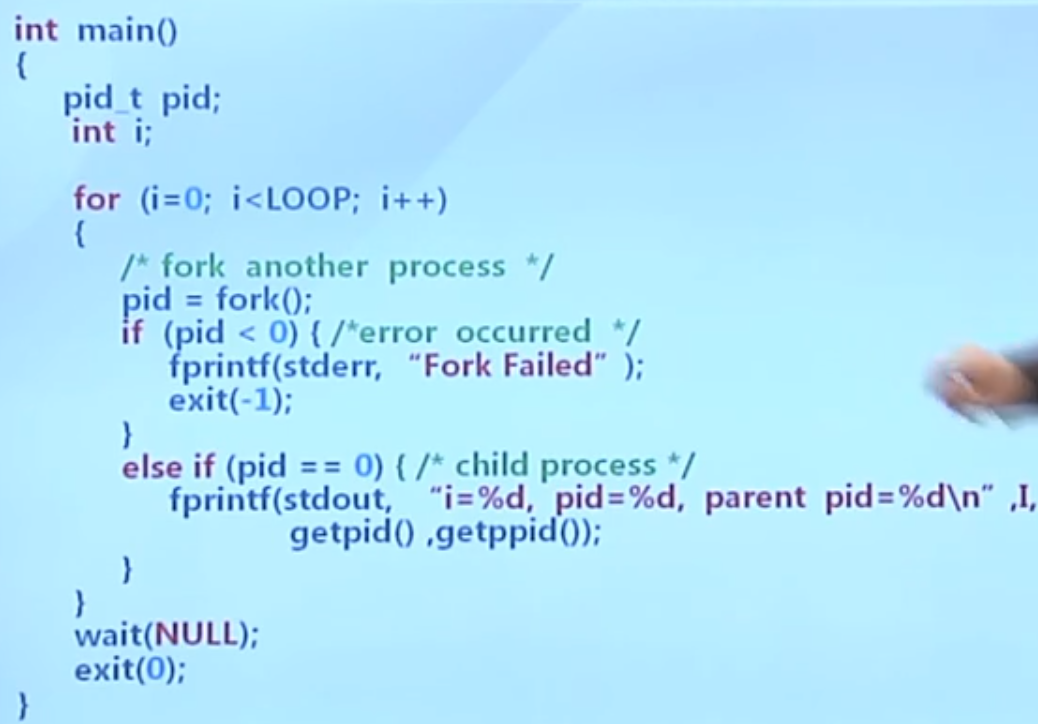
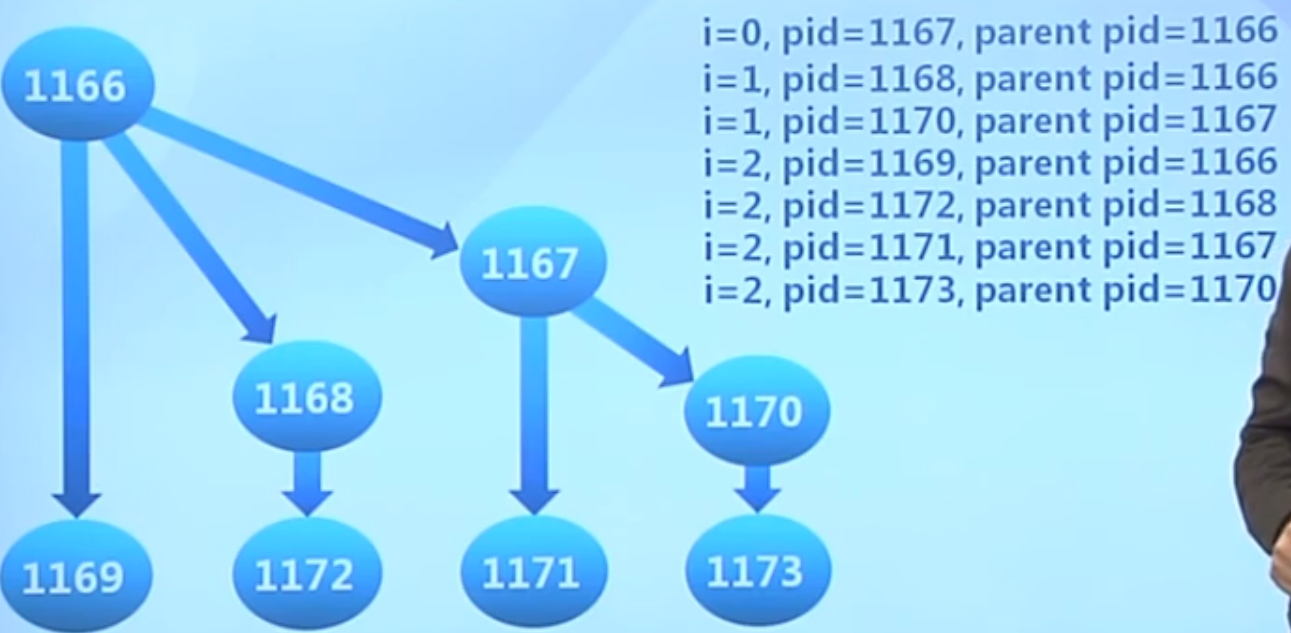
fork()在循环内部,每次都会执行复制。一个变两个,两个变四个。


ucore中fork()的实现
do_fork()做的工作:
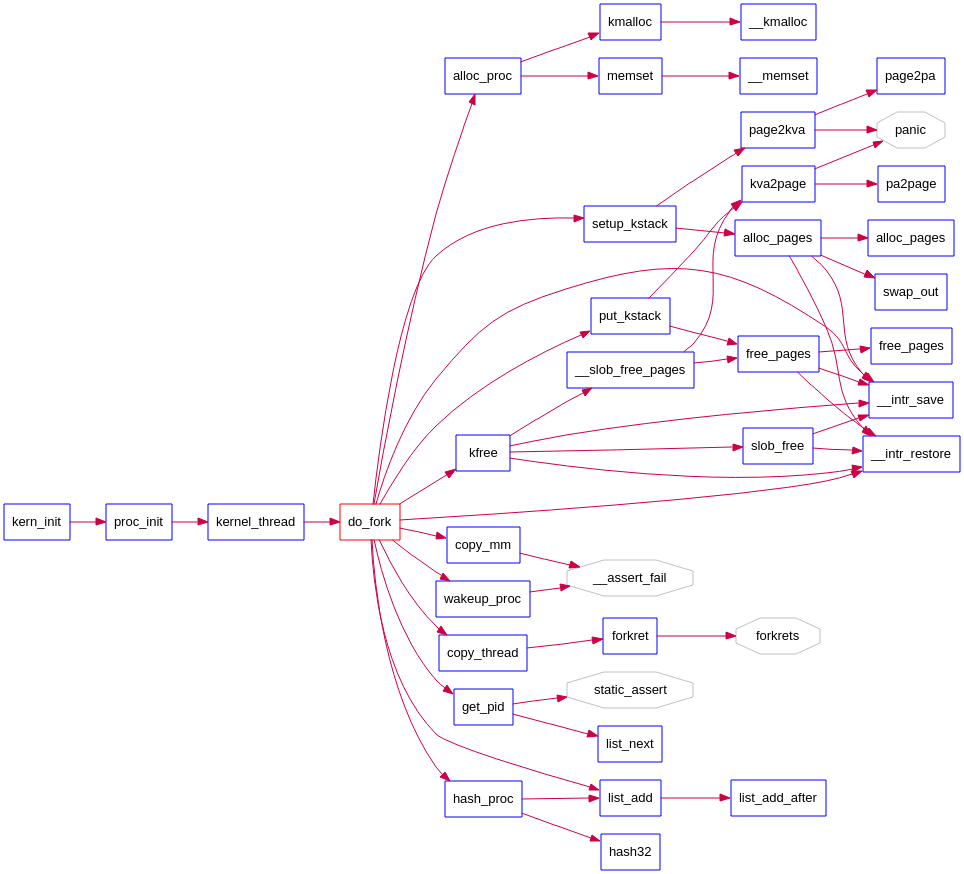
我们主要关心的几个:copy_mm、copy_thread
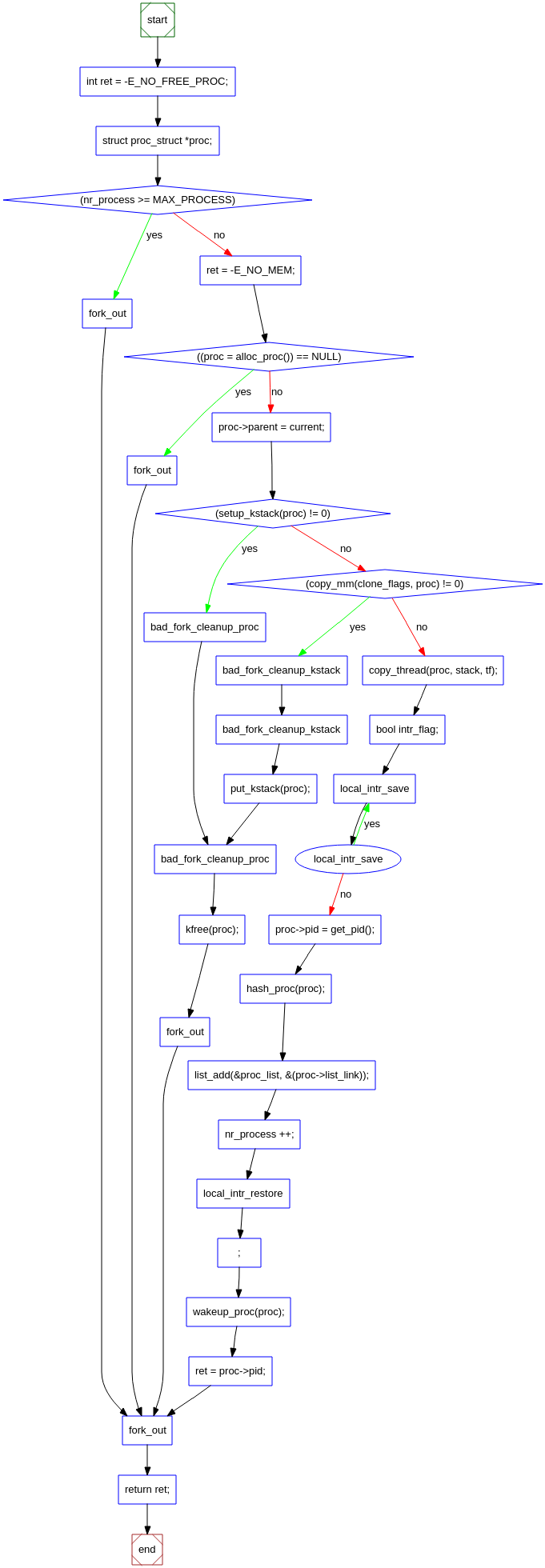
do_fork()实现流程图:
空闲进程的创建
当系统没事可干的时候(进程都执行完了),就创建空闲进程。


fork()的开销?

接下来,在大多数情况下,复制过来的东西也会被马上覆盖掉。

我们可以通过一次调用就完成创建和加载:

解释上图:用的时候再创建和加载。
进程加载

系统加载:CPU加电 – 启动bios程序 – 从磁盘上加载引导扇区 – bootloader – 内核映像 – 内核做一系列工作后到应用程序映像
应用程序加载:跟我们最开始学的加载操作系统一样。需要先将可执行程序的映像加载到在内存中,再跳到指定位置执行。这里就有可执行程序文件格式问题,不同的操作系统可执行程序文件的格式不同。


ucore中exec()实现
在外存上把可执行文件加载进来并跳转到上面的位置执行。这和引导扇区不一样,引导扇区放一块内容上去,我对她的格式是没有任何要求的。但可执行文件的格式在这里是严格要求的。
所以我们exec中主要做的工作就是格式识别。
分成三个主要的函数:
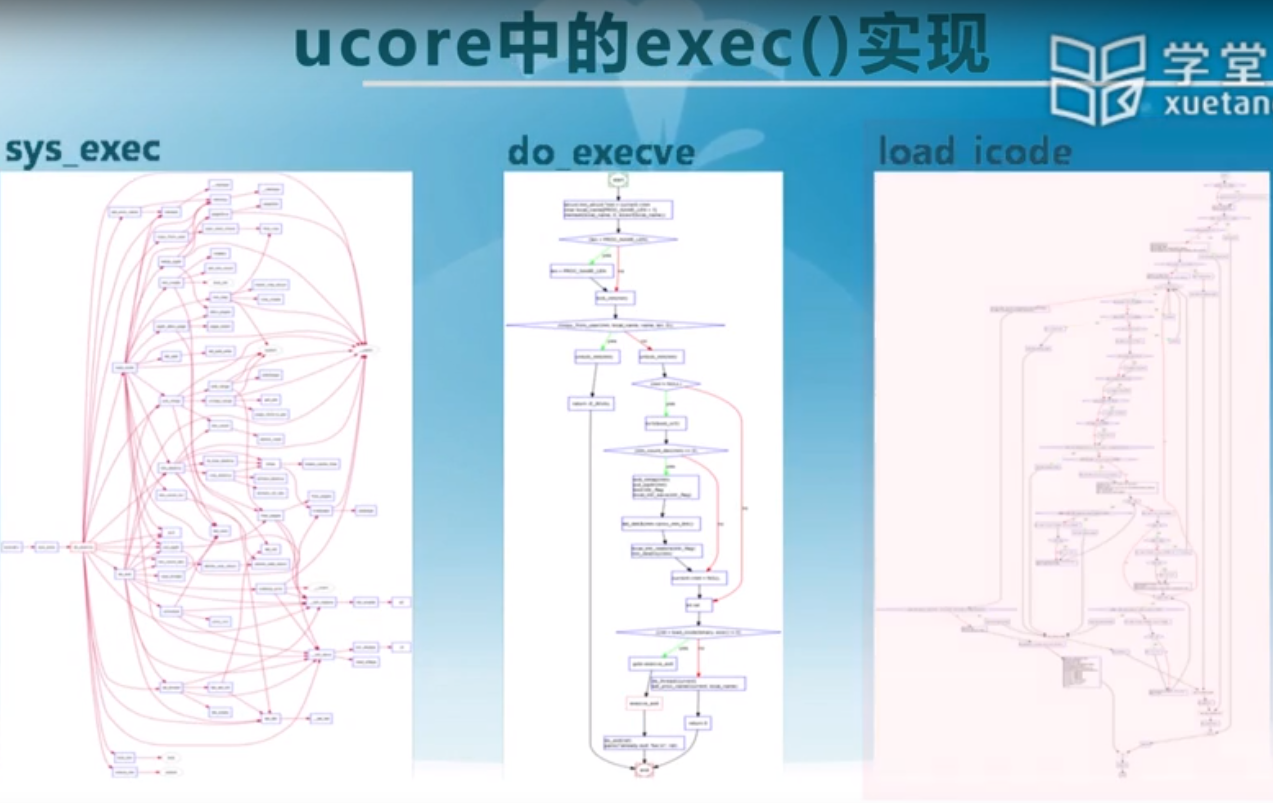
左图:获取相应的参数
中图:核心的加载功能
右图:识别格式,加载段,然后开始执行
ucore中第一个进程
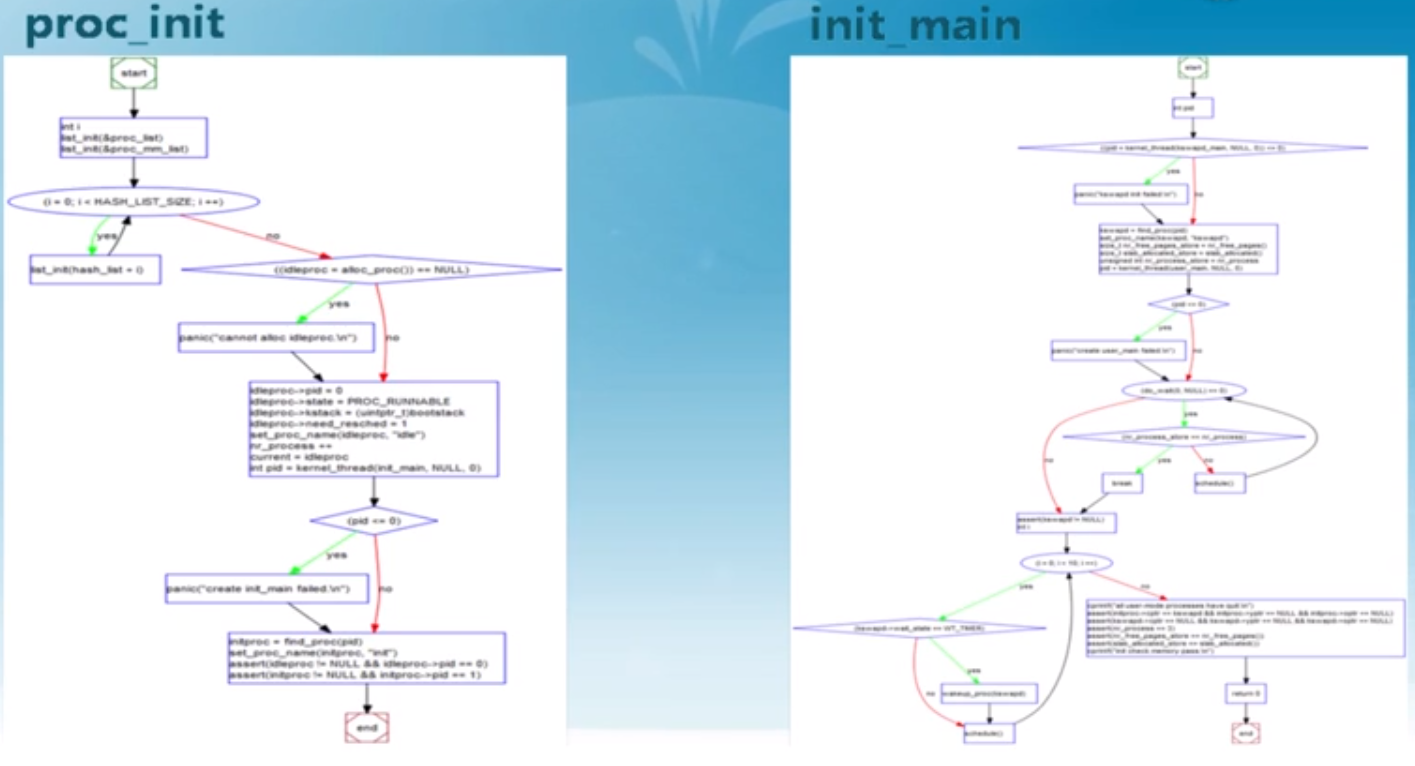
具体的执行过程通过阅读代码来理解。
进程等待与退出
父子进程之间的交互,完成子进程的回收。
等待


进程的有序终止exit()

子进程执行exit的时候检查父进程。

其他进程控制系统调用