本文已收录到:CMU数据库系统学习笔记 专题
视频、课件
视频:https://www.bilibili.com/video/BV1TR4y1W7ny/?spm_id_from=333.788
执行模型
迭代器模型、火山管道模型——一个一个吐数据
每个查询的操作符都要实现一个Next()方法。在每次调用中,操作符要么返回单个元组,要么返回空标记(如果没有更多元组)表示算子跑完了。操作符实现了一个循环,在它的子对象上调用Next()来检索它们的元组,然后处理它们。也被称为火山管道模型。我们依次来看每个算子是如何执行的,下面是每个算子的Next()方法:
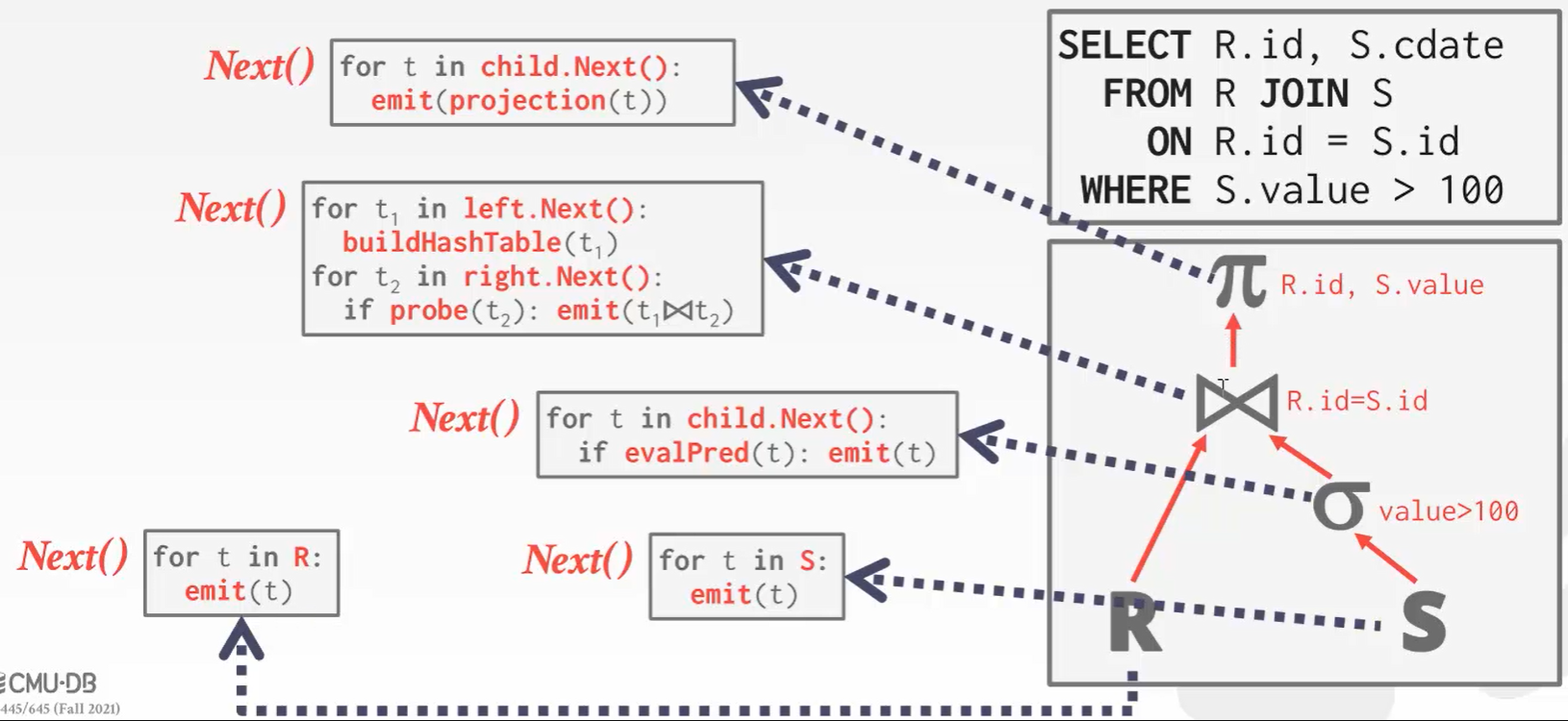
从上往下的执行顺序,第一个算子是投影算子,负责输出。在一个for循环中不断的调用子算子的Next()方法,每次调用都执行一个 projection(t)函数,来处理要输出的列——因为是投影算子。

下一个算子是JOIN算子。调用左孩子的Next()方法去构建hash表。

调用右孩子的Next()方法去右表拿到数据,然后去与hash表作比较,如果匹配上就往上吐数据。4也会调用5然后往上吐数据。

这种算法就像一个火山喷发一样,从底往上逐渐喷发。顶部函数不断的调用叶子函数,等待叶子函数有返回值了上面的顶部函数才能继续下去,否则一直处于阻塞状态。
物化模型——通过数组方式一次性的向上输出数据
下面的函数调用,每个函数(也叫算子)的返回值是整个数组,函数之间都是通过数组将自身筛选出来的数据一股脑的返回给调用者。

交易型数据库是OLTP(联机事务处理)型的,一般来说所有的语句都仅涉及数据库的局部。–> 回顾 OLTP和PLAP两种WorkLoad
因为OLTP数据库大多都是点查询,用这种一股脑的返回数据的物化模型是可以接受的。但如果是OLAP型就不行了,一股脑返回大量甚至是一张表的数据,容易出事…
向量化模型、分批模型——中和下火山和物化模型
中间派。对火山模型做改进,Next()方法不再返回一条数据,而是返回数条数据。

两点好处:
- 这种向量模型对OLAP型数据库友好。
- Intel最新处理器含有AVX指令集,它有一条指令(SIMD指令)可以实现在一个时钟周期内处理多条数据。例如元组中4个数值都需要与数字2做对比,那么AVX指令集可以一次性处理这个元组得到大于数字2的元素。如果数据库使用向量化模型就可以完美利用指令集的这一特性。
补充:函数调用方向
从顶至下:顶部的函数调用叶子函数。
自底向上:叶子函数往上调用。
访问方法:查询是如何执行的
全表顺序扫描遍历

会有一个指针或者说游标cursor记录迭代到哪里了。
优化
预加载:提前把需要用到数据加载到缓冲池中。
缓冲池:全表遍历的话不用缓存这个表,因为后面就不用了。我们用的时候直接将其送到执行器,用完就扔了。如果进缓冲池就会把宝贵的经常要用的东西冲掉。
并行执行:多算子查表,一个算子从头,一个从中间这样扫。
Zone Maps:给每个page做个统计信息。

有两个问题:占用空间;这统计信息存哪?我现在要解决的是这个page要不要读到内存中的问题,如果把统计信息存在page中,那不就白忙活了;如果原始信息变了,统计信息是不是要改?会不会更麻烦。
以下数据库做了这种策略,对page统计信息。

晚物化:向上返回行id,不要返回整个数据。

扫描索引
使用哪个索引需要下列条件:
- 索引包含哪些属性查询引用了哪些属性?
- 索引的值的范围?
- 索引含不含有我要的输出列?
- 谓词压缩
- 索引是否是唯一键或非唯一键?
Ps:什么是谓词?
Ps:下下课讲解。
抛出个问题:
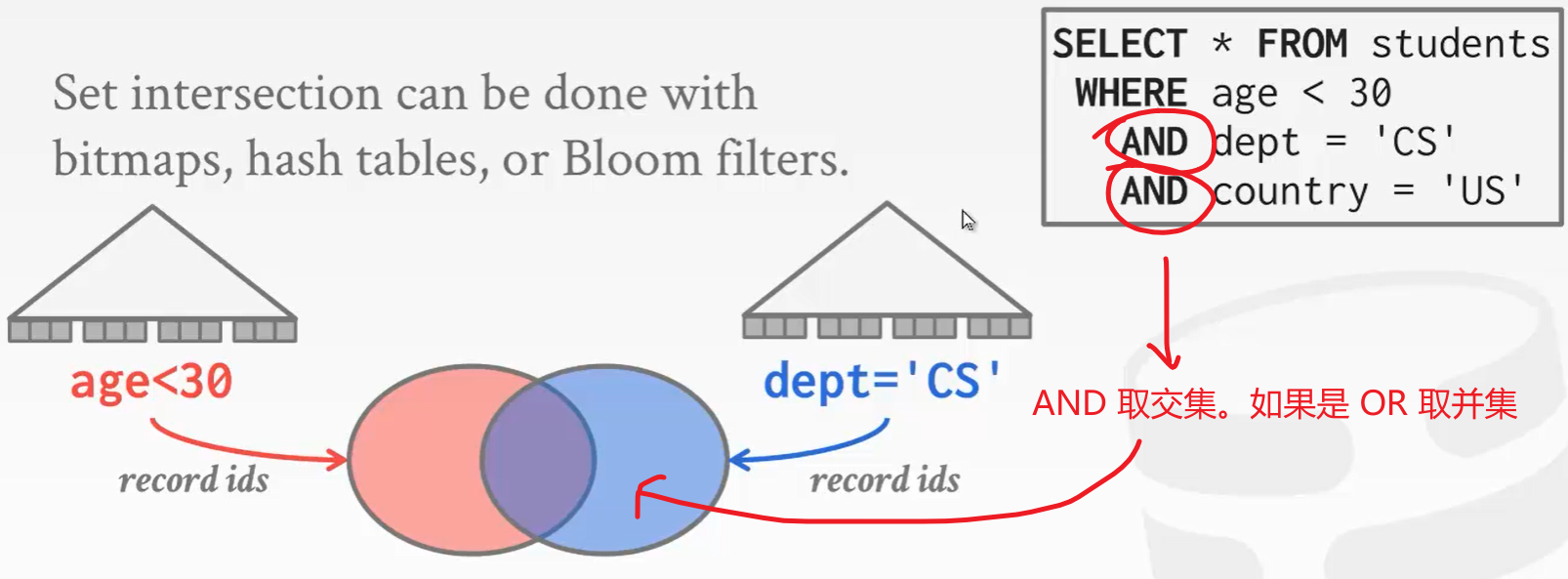
有两个索引 age和dept。查询SQL有三个谓词 age、dept和country。那么用 age和dept这两个哪个索引好呢?

个人意见:我觉得用dept好,因为在一个学生表中,学校的学生年龄大部分都是在30岁以下,但是系是分散的。使用age做索引最终查询到剩下的数据还会有很多。但如果对dept做查询,剩下的记录会少的很多。例如100名学生,可能有80个人都是30岁以下,但是 CS 专业的可能只有20人。
多索引扫描
继续上面抛出的问题。我们现在是在纠结选取哪个索引的问题,是二选一问题。但是,我们可以都要,一边筛选 age,以便筛选 dept,最后去个交集,这样不是更快吗?
修改查询:增删改是如何执行的
修改查询涉及到 insert、update、delete。与select不同,他们是对数据库做修改的。
在insert一条数据之前,不能无脑的就插入了。还有检查约束(唯一性等),如果有索引的话还要更新索引,如果page由统计信息,还要更新统计信息。
UPDATE/DELETE的两种执行思路
与晚物化一样,例如删除:要求子算子一个个把id吐出来就行了,然后我去删除记录。
但是update和delete有个问题:算子必须记录这次执行删除了什么数据。为什么要这么做?我们看下下面update例子:
SQL语句准备把所有 salary < 1000d 的人的薪水加上100。下面红色指向的是当前tuple Andy。发现他的salary < 1000。

于是将其处理后插入回去,现在Index(people.salary)的位置改变了。

但往后,红色的箭头再一次指向 Andy,它并不知道这个 Andy 已经处理过了。这会导致又被加上了100。所以我们需要一个游标来记录操作过的tuple。
INSERT的两个方案
————————————-这一部分没太懂———————————–
在算子内部物化,然后把整个行记录插入。
子算子去把行记录物化好,
————————————-这一部分没太懂———————————–
表达式计算
最直接的办法是拆成子算子。这里有点像 编译原理中的语法树~

下面这种查询SQL语句会存在很大的效率问题:

每次查询都要不断的计算 ? + 1。一个好的解决办法是提前算出来 ? + 1 的值。
更有甚者,在SQL语句中使用 WHERE 1 = 1 这种谓词:
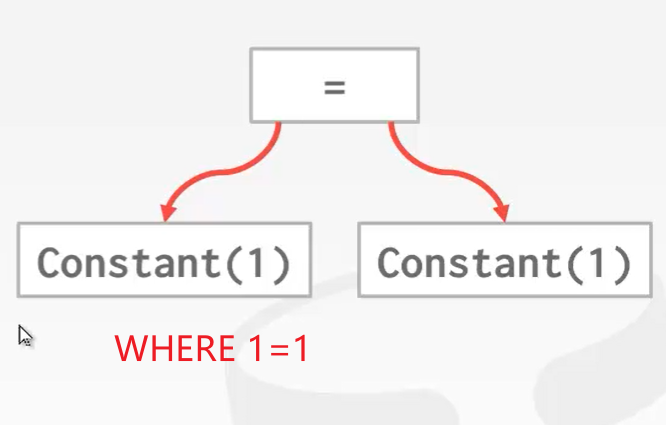
像这种恒为真的谓词,在查询中不断去比较,这是很降低效率的。一个高效的数据库往往会直接干掉这种语句!
这里补充一个Java中的JIT技术。JIT可以把Java字节码中不断重复的代码转换为二进制,这样可以提高效率。在我们手机安装Java软件的时候,有段工作就是把字节码翻译成二进制。