本文已收录到:CMU数据库系统学习笔记 专题
视频课程(中字幕)、课件
视频:
https://www.zhihu.com/zvideo/1416169097633234944
https://www.zhihu.com/zvideo/1416174789904379904
课件:
Tree Indexes
表索引
什么是表索引?
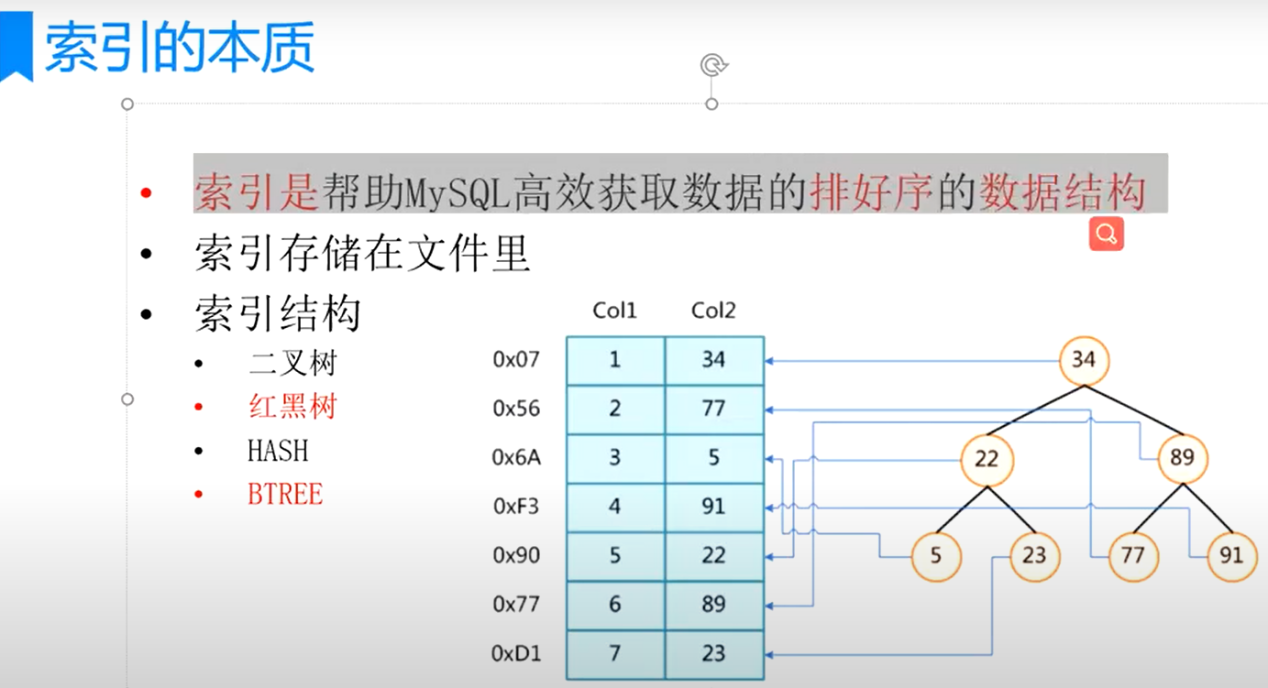
索引是存储在磁盘中的。
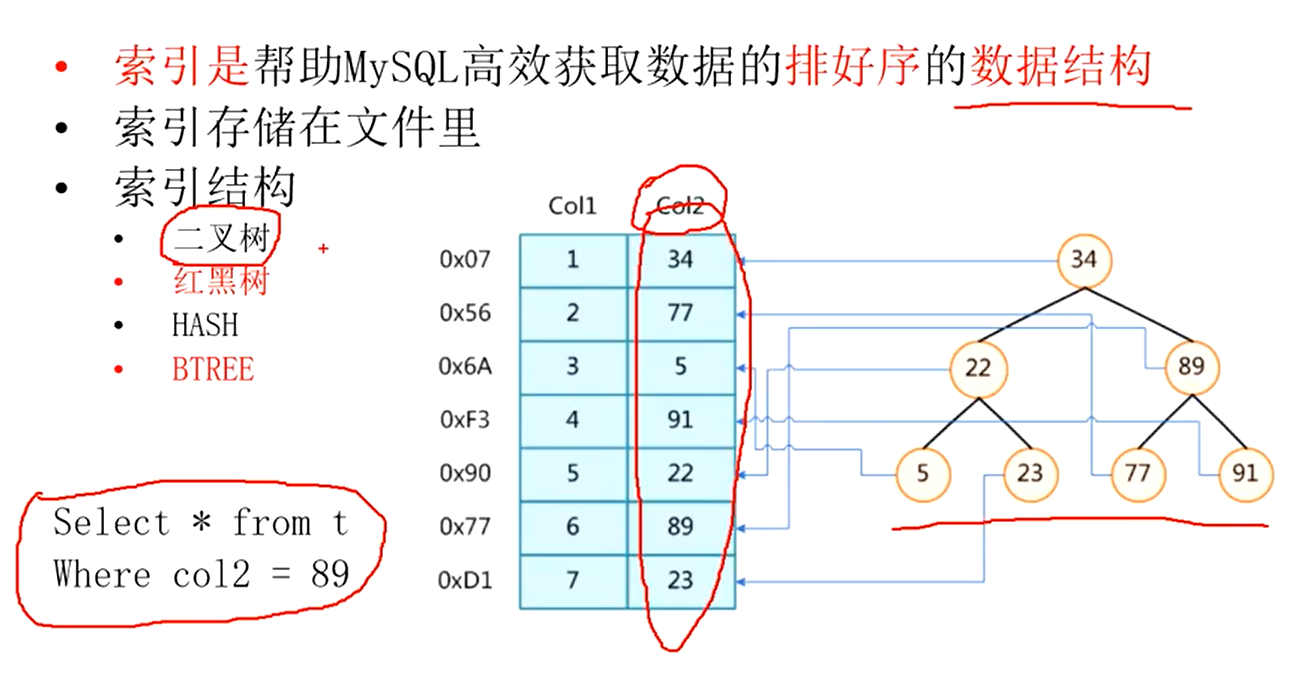
将索引字段放入到二叉树中。


数据库系统会帮助我们管理索引,在使用者更新、插入等操作表时会自动更新索引。

该什么使用索引,这不是本课程所要讨论的东西,这一部分你可以花钱请DBA来做。






表索引是表属性子集的副本,这些属性是使用这些属性的子集进行组织和/或排序以实现高效访问的。
DBMS确保表和索引的内容在逻辑上是同步的。
个人猜想:有点像书本的目录
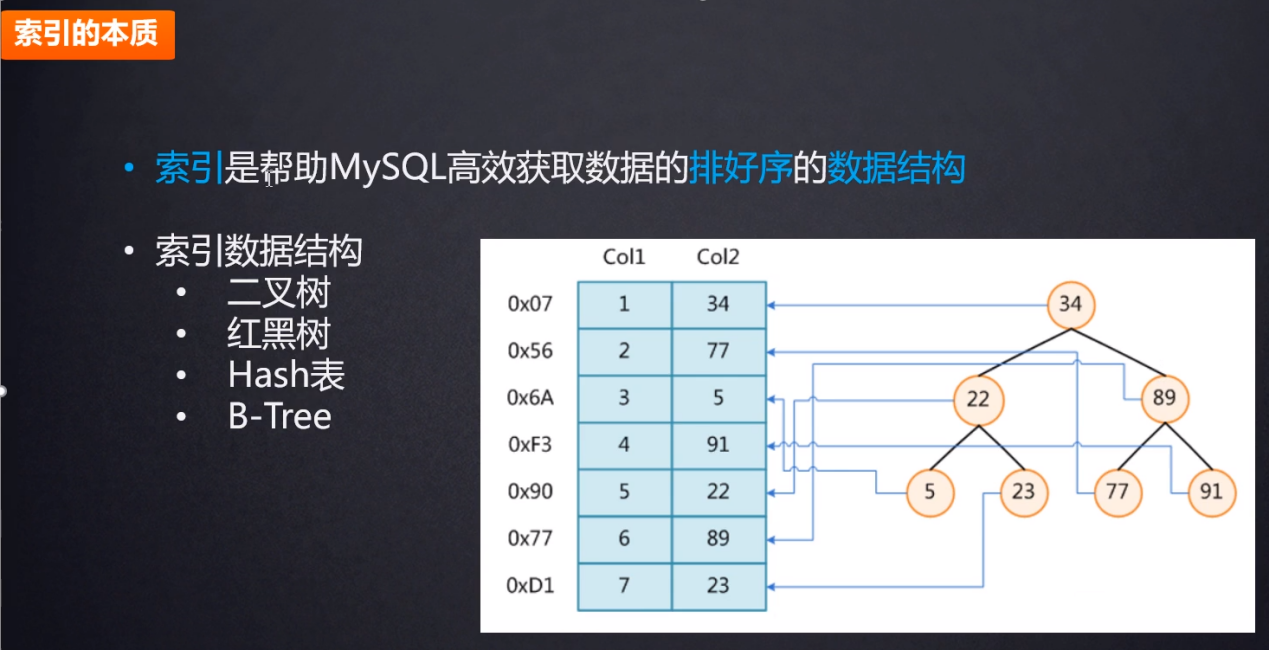
索引就是个数据结构。索引底层也是存储在文件上面的,如图:

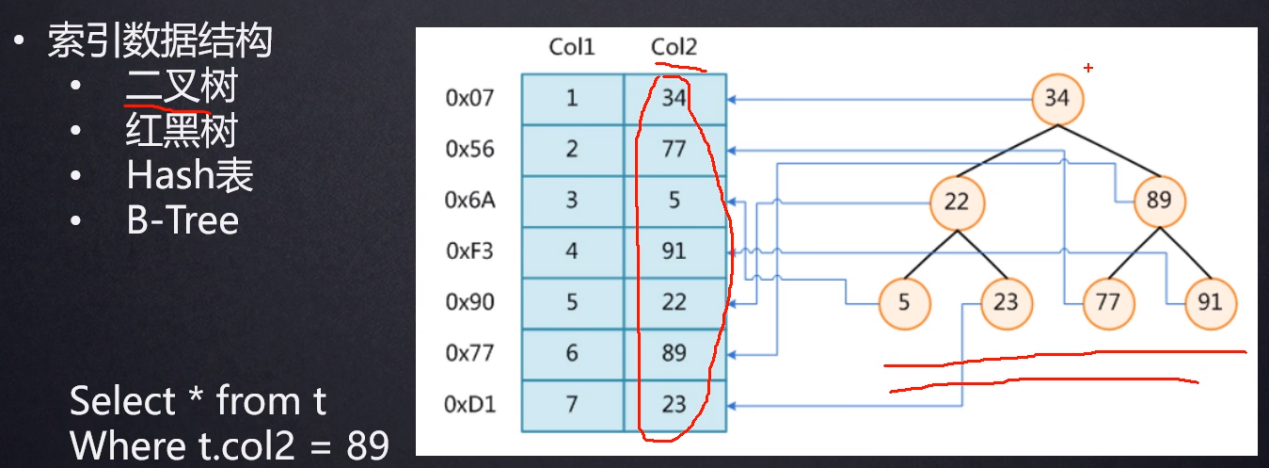
把左边的数据索引成数据结构中的二叉树。
通过表索引这个数据结构,可以高效的找到数据。
当我对表进行更新后,也必须更新索引,已反映我的更改。






DBMS的工作是找出执行每个执行所使用的最佳索引,每个数据库创建的索引数量有一个折中。
- 存储开销
- 维护费用
为什么使用表索引?
为“书本”建立目录,更快的查找章节。
B -Trees(B树家族)
上节提到,DBMS 使用一些特定的数据结构来存储信息:
- 内部元数据
- 核心数据存储
- 临时数据结构
- Table Indexes

我们将重点放在B+Tree。
本节将介绍存储 table index 最常用的树形数据结构:B+ Tree,Skip Lists,Radix Tree。
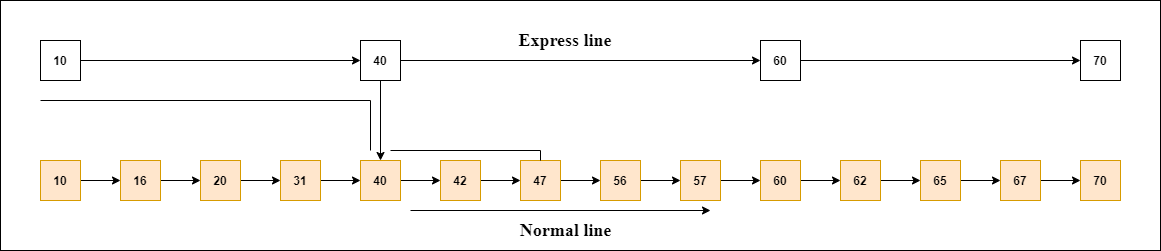
补充:跳过列表
跳过列表的工作:让我们以一个例子来了解跳过列表的工作。在此示例中,我们有14个节点,因此这些节点被分为两层,如图所示。
下部是连接所有节点的公共线,顶层是仅连接主要节点的快速线,如您在图中所看到的。
假设在此示例中要查找47。您将从快速线路的第一个节点开始搜索,然后继续在快速线路上运行,直到找到等于47或大于47的节点。
在该示例中,您可以看到快速行中不存在47,因此您搜索的节点小于47(即40)。现在,借助40转到法线,并搜索47,如图所示。
来源:https://www.javatpoint.com/skip-list-in-data-structure
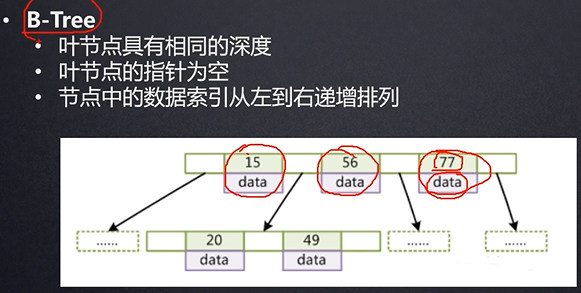
有一种特殊的数据结构叫做B-树,人们通常也用这个词来指代一类平衡树数据结构。
红黑树(二叉平衡树)【数据库不用】
https://www.bilibili.com/video/BV1Y4411C7UV?p=1 第20分钟开始
红黑树用来存储索引有弊端,在表数据巨大的时候,有500万行数据,数的高度(磁盘读取次数)会有23层。2的23次方 ~= 838万
B-Tree(B树、多路平衡查找树)【数据库不用】
B树(B-Tree)和平衡二叉树稍有不同的是B树属于多叉树又名多路平衡查找树(查找路径不只两个)。
https://www.bilibili.com/video/BV1Y4411C7UV?p=2 第0分12秒开始
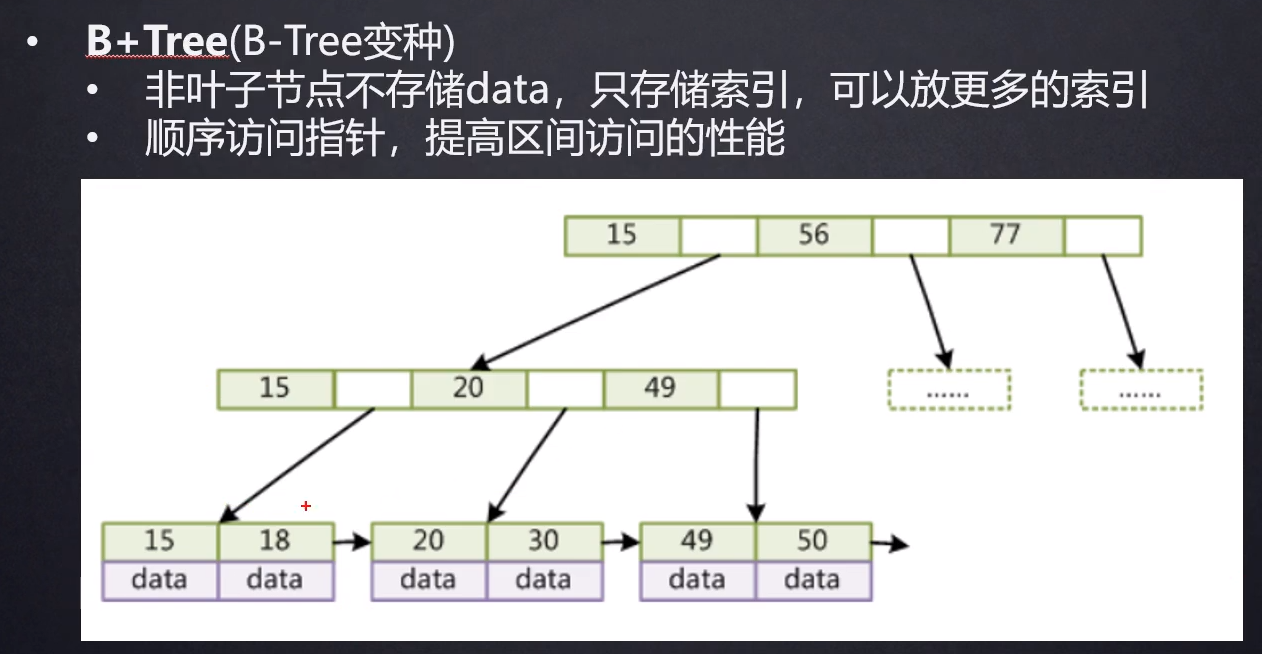
B+Tree【数据库真正广泛使用的数据结构】
https://www.bilibili.com/video/BV1Y4411C7UV?p=2 第4分钟开始
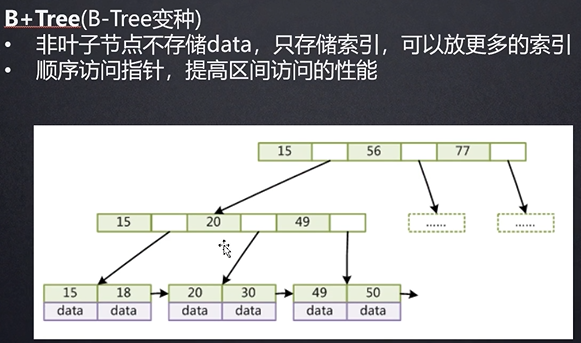
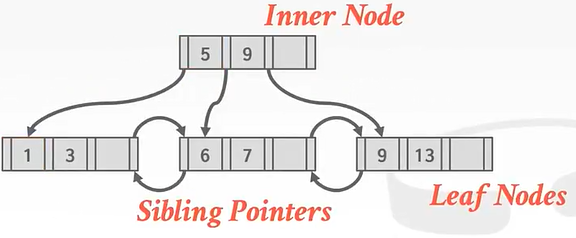
其实最下面的叶子节点就有点像线性表,也是通过指针相连。与线性表不同的是B+Tree除了叶子节点以外的结点存储的没有数据而是索引,这些索引可以帮助我们快速的在“线性表”中找到位置。
B+Tree是一种多叉平衡树。


虽然B+Tree是40年前的东西,但直到今天也在广泛使用。


这是数据库中最好的数据结构。
————————————————————————

保证每个节点至少是半满的状态。



如果结点不处于半满的状态,

非叶子结点:
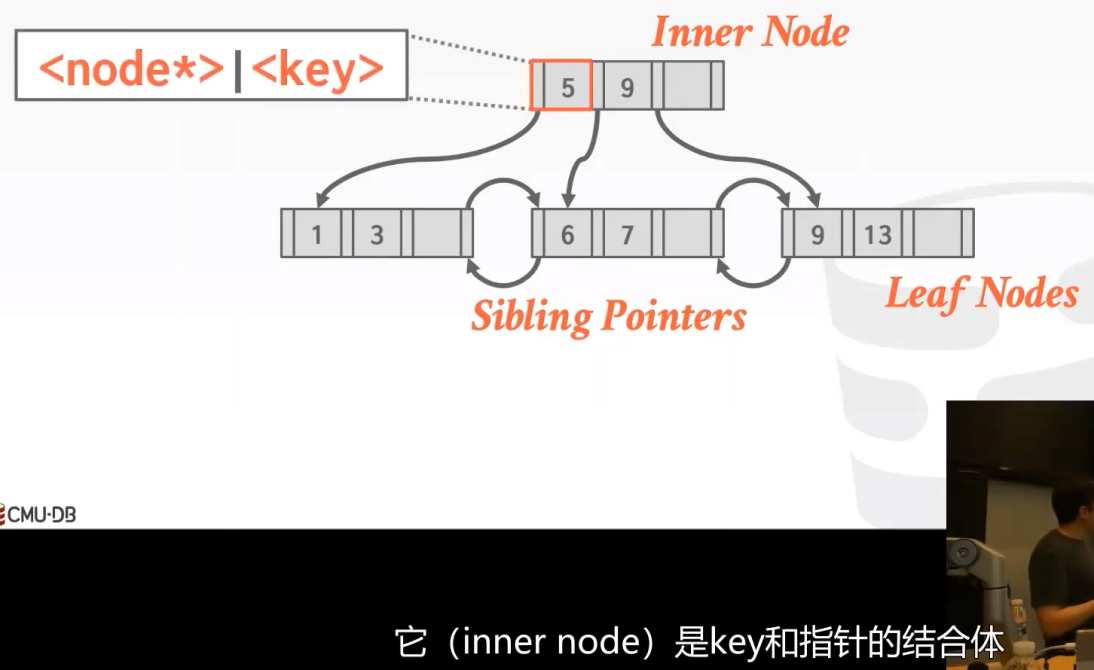
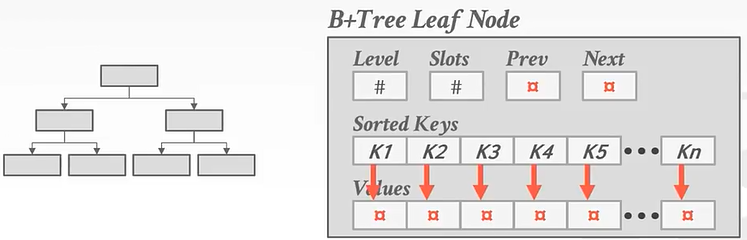
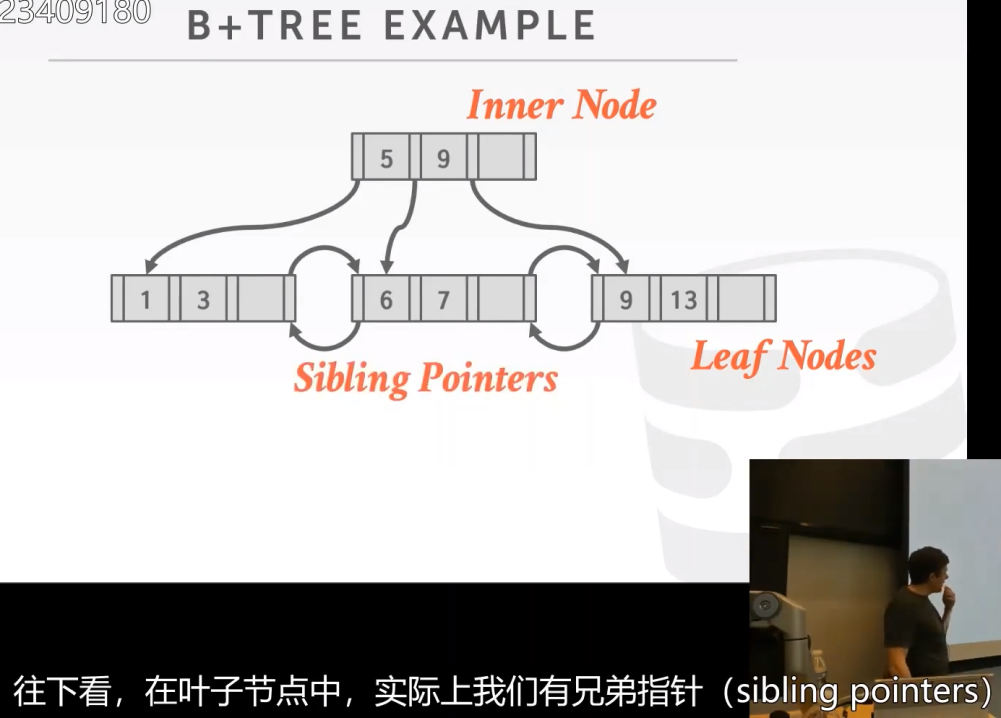 在非叶子结点中没有兄弟指针,但叶子结点有。
在非叶子结点中没有兄弟指针,但叶子结点有。

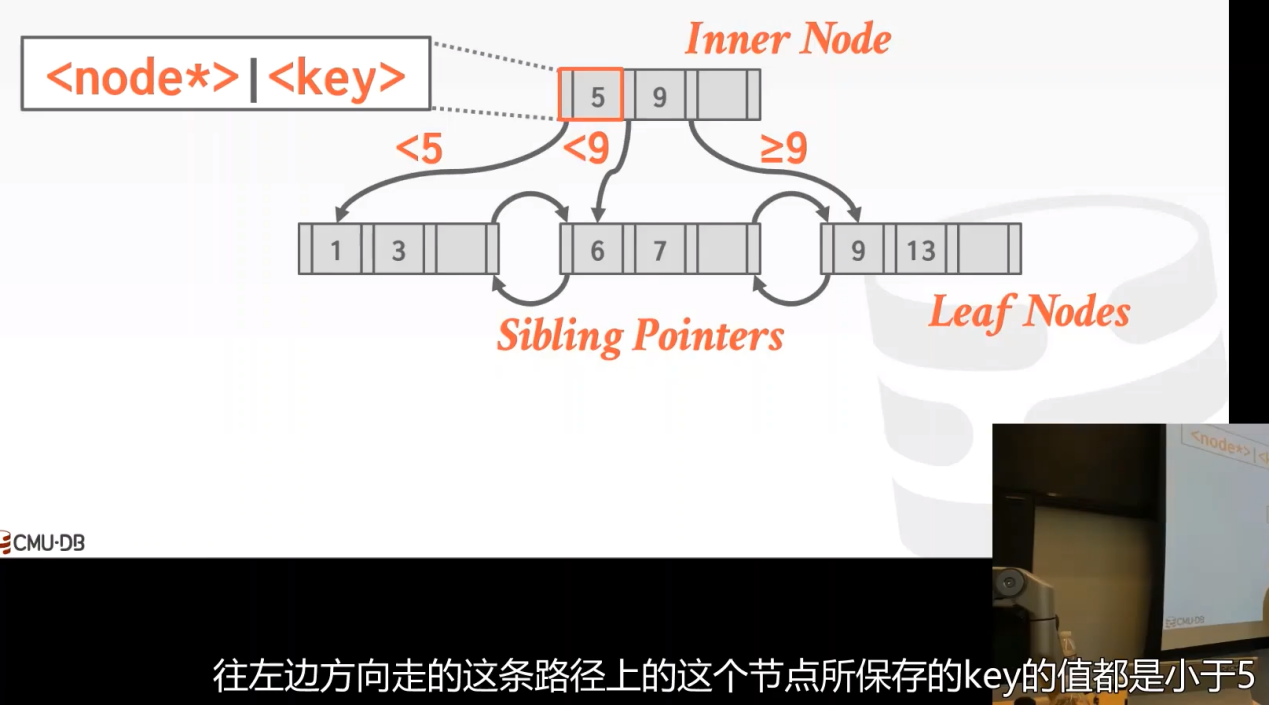

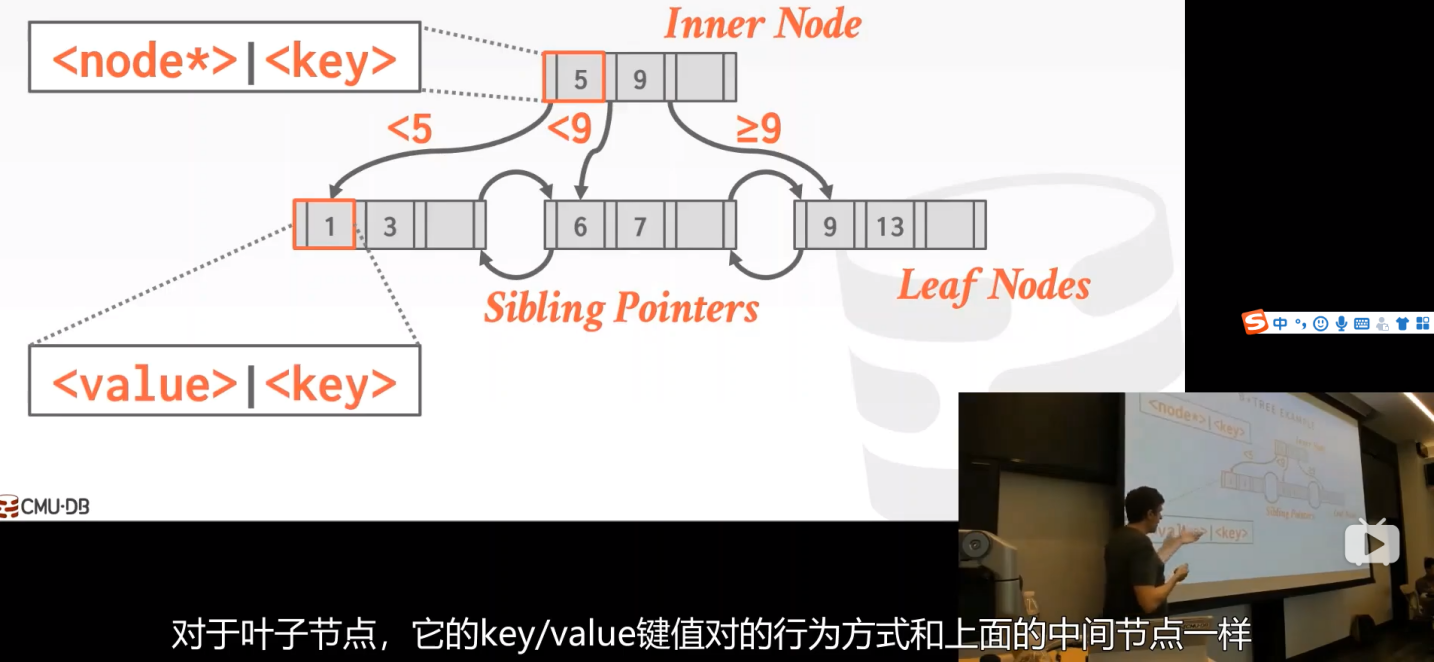







提问:

叶子结点:
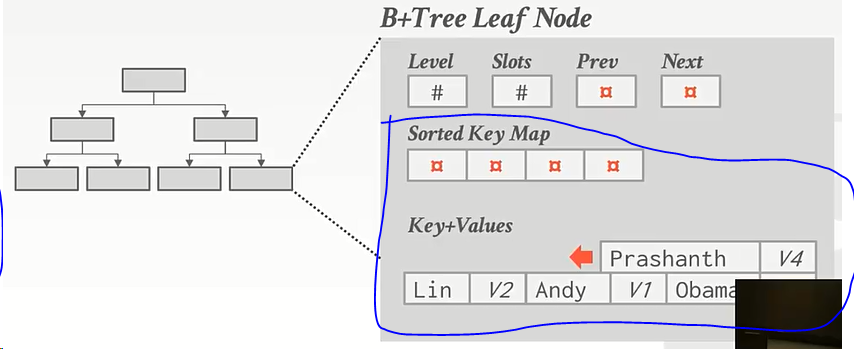
在数组的开头和和末尾会存放其他兄弟结点的指针,方便我们跳转到前面的page id或者后面的page id。
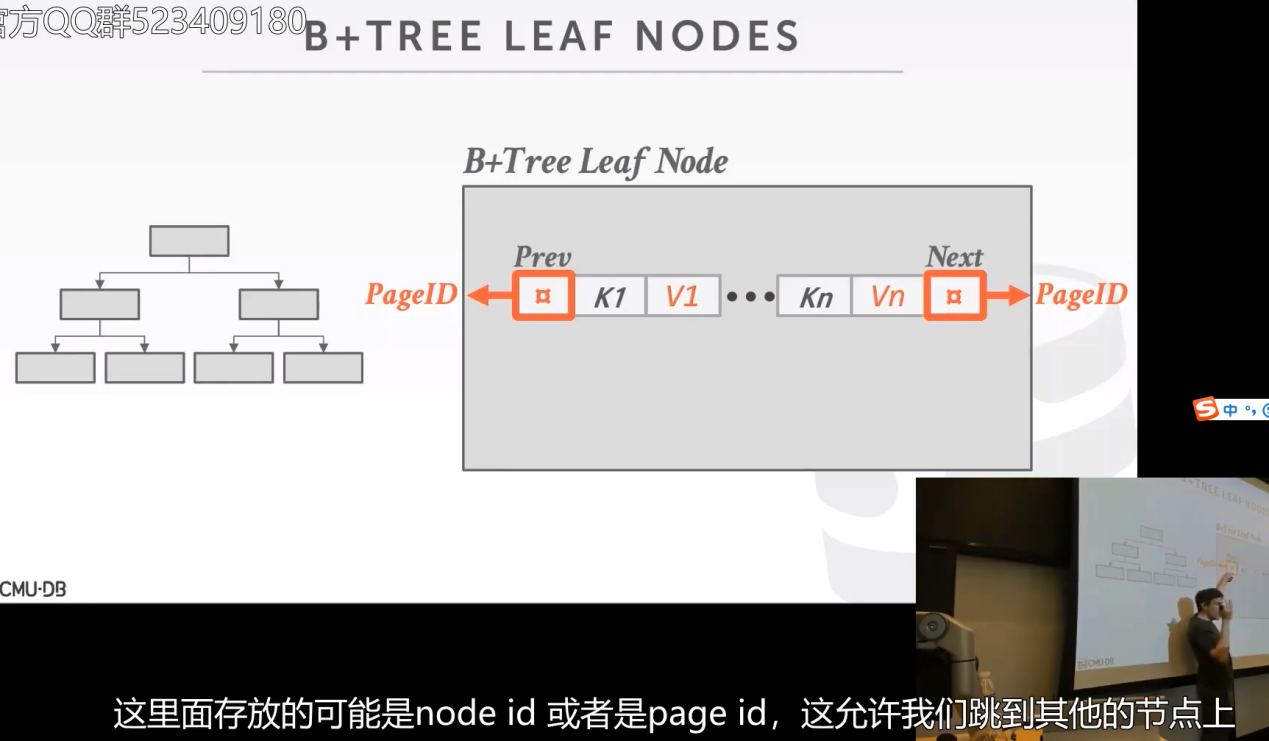
一般来讲他们是分开保存的:
问:为什么要拆开存放而不是像上上面那张图保存在一起?
答:因为我们并不需要用到value,我们只想找到key。如果拆分后我就可以在sorted Keys这里找key,这可以更高效的在key之间跳转。,  ,我找到key后拿到了offset值然后我跳转到value数组中的那个offset处,拿到我想要的东西。
,我找到key后拿到了offset值然后我跳转到value数组中的那个offset处,拿到我想要的东西。
不同的数据库系统有不同的方案,有的是记录id,有的是记录tuple本身数据:

 ,
,  ,
, 
B-Tree和B+Tree最大区别:
1972 年的原始 B-Tree 中所有的结点存储了value。而B+Tree 仅将值存储在叶节点中,非叶子结点仅指导搜索过程。在B-Tree中不会有任何重复的key,我可以保证我的树中每个key仅出现一次。而在B+Tree中,非叶子结点存储的是路标,会有重复的key——可以联想路标的概念,你从北京到上海,高速公路上一定会有很多指向上海的路标。当我们删除了“上海”后,路上一堆的路标怎么办?
问:为什么不使用B-Tree呢?
答:相比之下,B-Tree更加经济,占用空间也更少,路标只有一个非常好处理。不用他的真正原因是B-Tree的非叶子结点总是乱动啊!他还带这数据一起乱动!这样子的话,当我  ,
,  ,
,  以防止非叶子结点带着数据动来动去,这会引起很多问题。但如果是B+Tree,因为只有叶子结点存数据,处理就比B-Tree要简单。
以防止非叶子结点带着数据动来动去,这会引起很多问题。但如果是B+Tree,因为只有叶子结点存数据,处理就比B-Tree要简单。
B+Tree操作
删除元素时
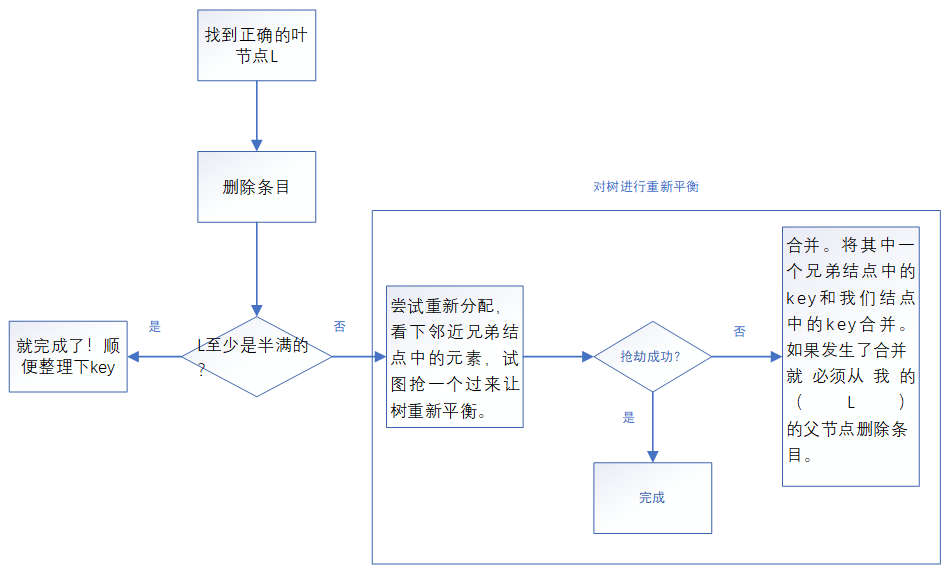
如下图:
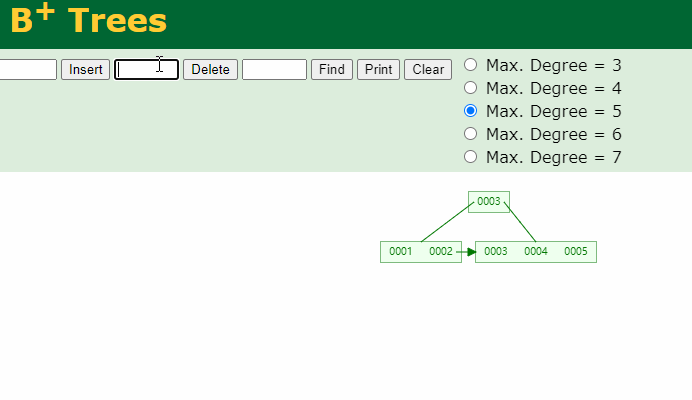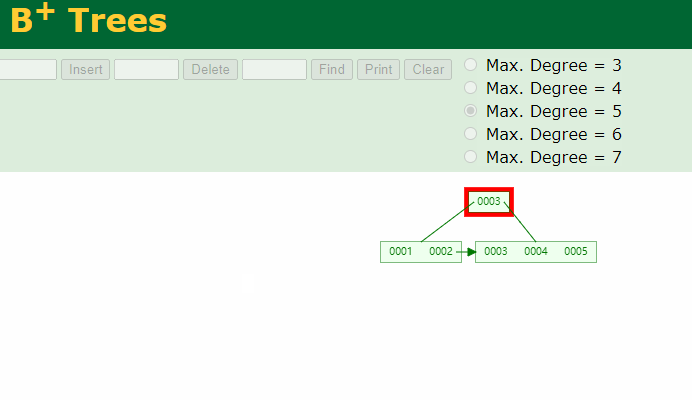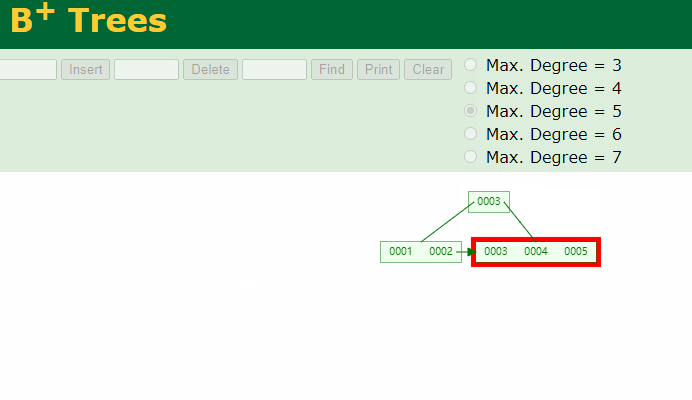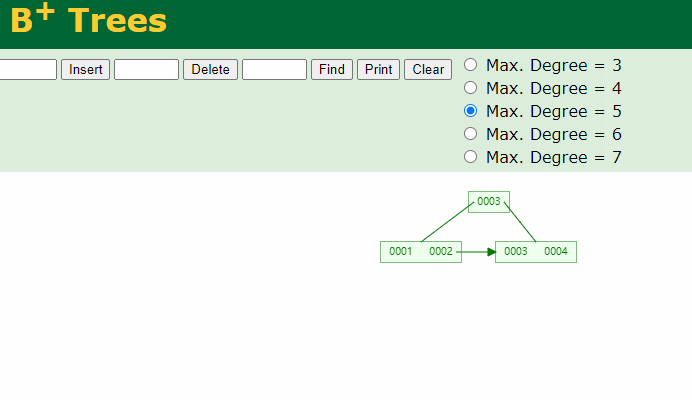
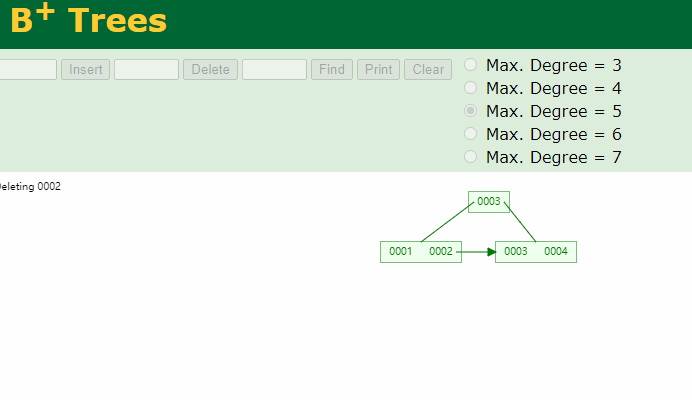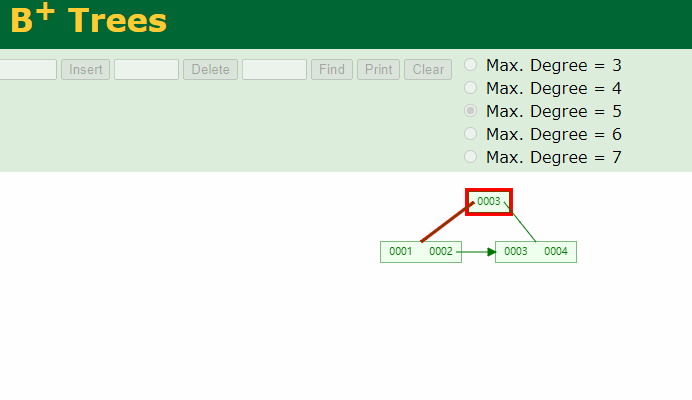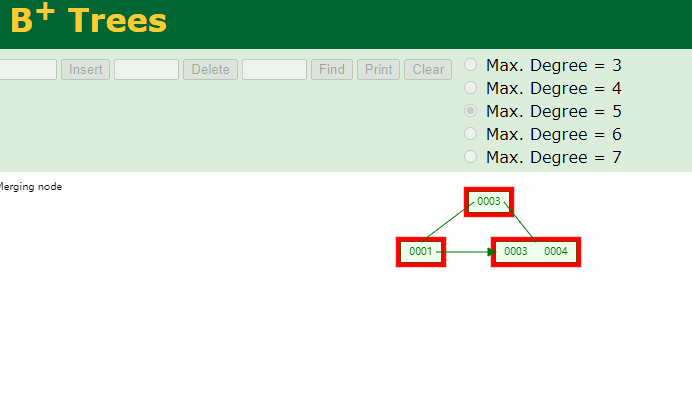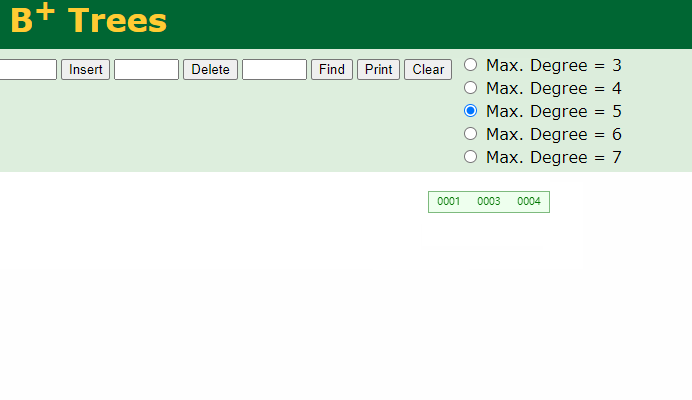
请注意:在强调一遍,B+Tree的非叶子结点仅仅是指路牌,不存放数据,数据都存放在叶子节点上。
难点:在重新整理B+Tree的时候 如何保证线程安全。
注意一种情况:
看视频Tree Indexes(上)第23分钟43秒。
将5删除后,叶子结点就没有5了,5这个路标虽然还在非叶子结点上,但他不是一个真正的key。B+Tree中数据只在叶子结点上。
关于B+Tree的插入删除操作可以看这里的动画:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
叶子中的key允许被重复吗?
可以说,能重复、也可以说是不能重复。不能重复的原因是数据库系统中,B+Tree结构用于存放唯一的索引,key是唯一的,所以不会重复。
插入元素时
每个结点所能存放的key的个数是一个参数,可以人为指定。例如下面的Max. Degree设定为3:
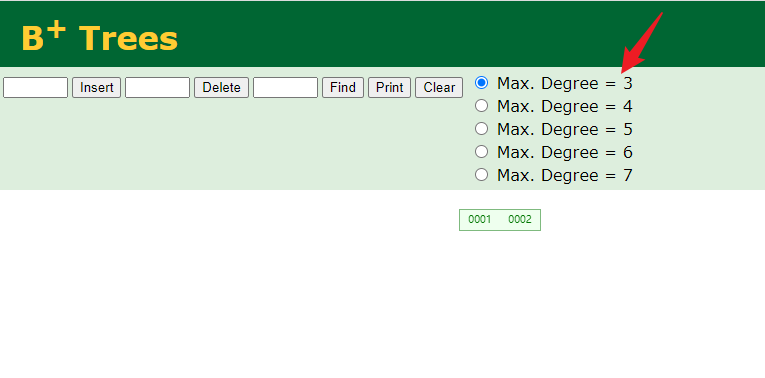
当存放>=3个key树就会分列重新排布:
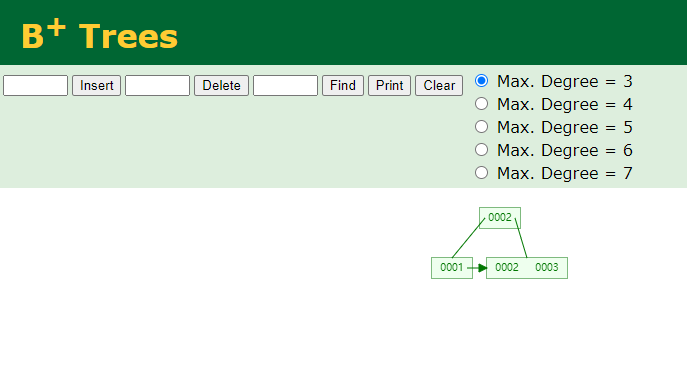
也可以理解为从一个非叶子结点至多只能出来三条线;非叶子结点至多保存两个key:
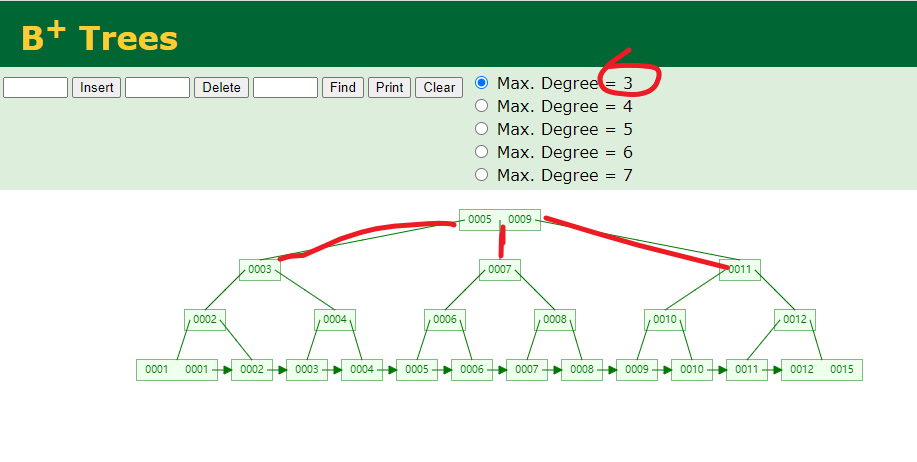
自己动手试一试:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
Ps:
例如数据表中有一列存储的全部都是数字5,虽然都是一样的,但数据库系统依然会让我们创建索引,这看起来很蠢,或者你可尝试下反向索引。在真正业务的数据库表中,如果某列(字段)存储的是电话号码、电子邮箱等这些每个人不会一样,都是千差万别的value,这时候构建索引是再好不过的。尤其是对某字段有唯一值约束的时候,构建索引是理所应当的。
如何在B+Tree上查找
前缀查找:如下图,有三个索引<a, b, c>。支持使用(a = 5 AND b = 3)这种语句对一个以上的索引做查询

复合键:
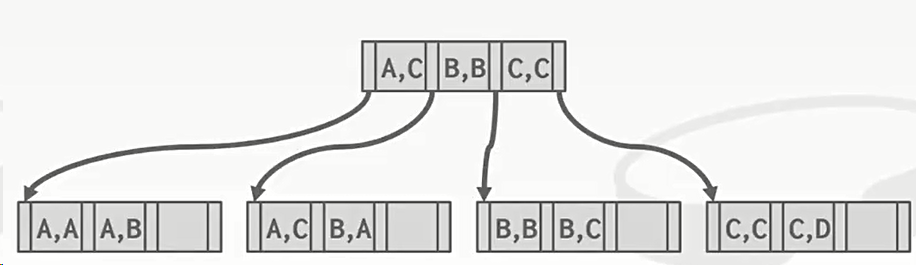
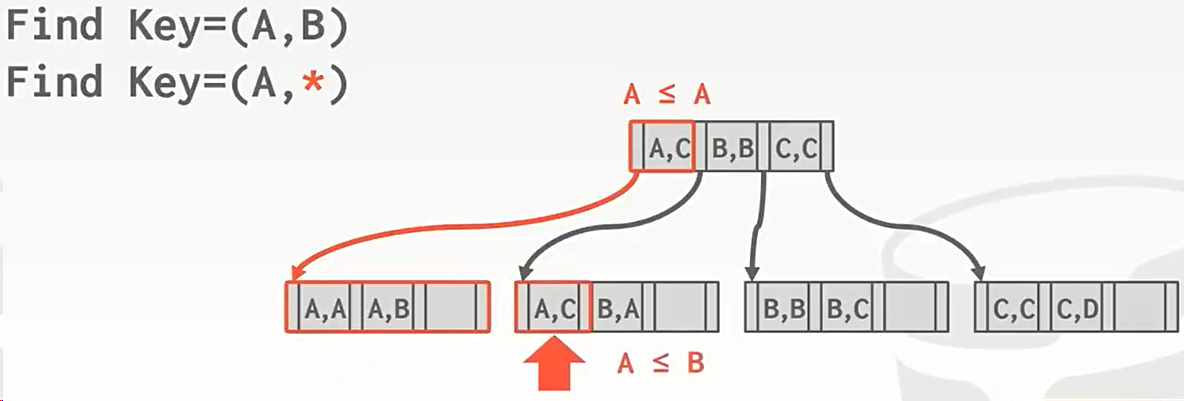
下面这两种知道前缀的复合键查询就比较简单,具体看视频 CMU 15-445 20 Tree Indexes(上) 第43分30秒开始。这种情况查询,多数数据库都是支持的。
真正难的是下面这种情况:
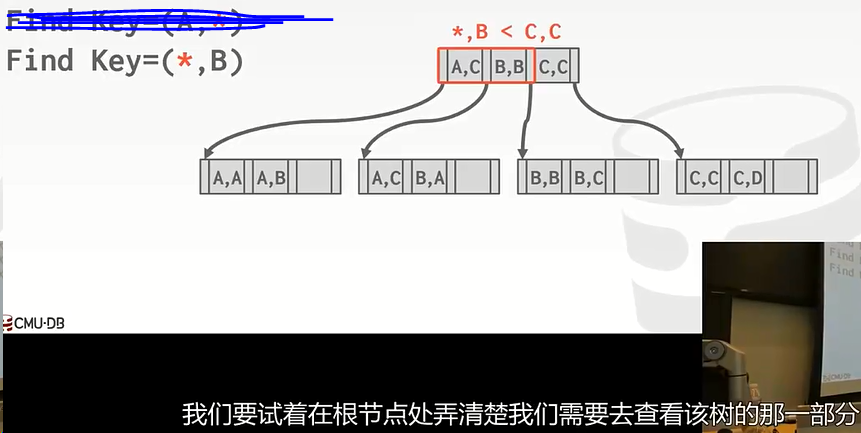
不论前面是什么,但我知道  ,基本思路是
,基本思路是 
B +树的设计选择
有关B+Tree具体设计实现的一本书:

node的大小如何设定
一个node的大小等同于一个page的大小,通常来说,disk 的数据读取速度越慢,node size 就越大。
| Disk Type | Node Size |
| HDD | ~1MB |
| SSD | ~10KB |
| In-Memory | ~512B |

如何进行合并?合并策略
当结点没有达到半满状态就需要随时进行合并。刚才的案例非常简单,及时合并就可以了,  。频繁的拆分和合并对系统而言是消耗巨大的,在实际中我们愿意忍受不是那么平衡的B+Tree,我们希望在某个时候去维护数据库,重建索引,让这颗树变得平衡。例如你经常会看到某个银行在周末的凌晨维护系统,这可能就是在维护他们的B+Tree。
。频繁的拆分和合并对系统而言是消耗巨大的,在实际中我们愿意忍受不是那么平衡的B+Tree,我们希望在某个时候去维护数据库,重建索引,让这颗树变得平衡。例如你经常会看到某个银行在周末的凌晨维护系统,这可能就是在维护他们的B+Tree。
如何处理可变长度的key
在此之前,我们讨论的key都是固定大小的,但实际中key可能长度不一。
解决方法:
- B+Tree结点不存放key本身,而是存放指向key的指针。eg:如果属性的varchar,
 。在以前内存很昂贵,所以没有人用这种方法。
。在以前内存很昂贵,所以没有人用这种方法。 - 当结点长度可变化,去适应key的长度不一。这是一种很糟糕的办法,
 ,这样就不会多出来一堆我们不知道该怎么维护的空余空间。这种方式也无人使用。
,这样就不会多出来一堆我们不知道该怎么维护的空余空间。这种方式也无人使用。 - 填充。不管你key是多大,我的node是一定比你大的,多余的空间我放null和0好了,让所有数据都完美对齐。——这种方法有人使用。PostgreSQL采用了这种方式。
插句题外话:
在数据表设计的时候,长度填的过于冗长就会不利,注意合理填写类型长度:

关于超过这个长度会怎么做?
这个不同的系统做着不同的事情。  ,MySQL做的最糟糕,他会直接截掉超过长度的字符。其他的所有系统会报错给你。
,MySQL做的最糟糕,他会直接截掉超过长度的字符。其他的所有系统会报错给你。
- 更为常见的方式是间接映射。内嵌一个指针数组sorted key map,指向 key/val list
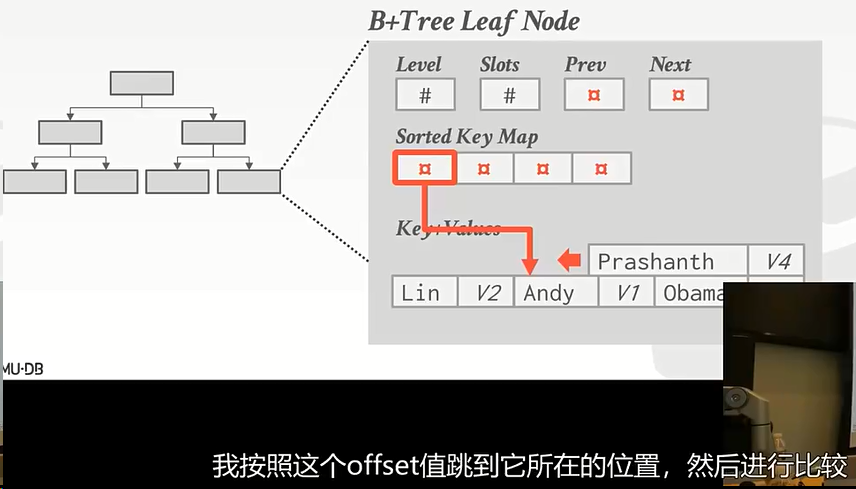
关于sorted key map与key+value之间的查找与映射问题,这是微优化。不同的系统做法也不相同,例如采用字典之类的算法东西… …但需要注意的一点是这里都是在内存中操作,不存在miss cache问题,在内存中的比较是非常快的。
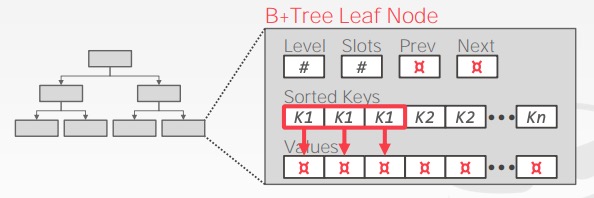
如何处理非唯一键
方法:
- 存储多次相同的 key:
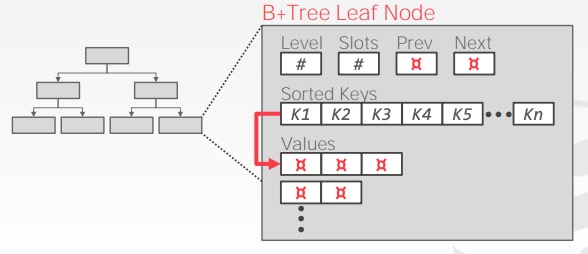
- 每个 key 只出现一次,但同时维护另一个链表,存储 key 对应的多个 values,类似 chained hashing:
提示:数据库是被人设定的,所以他知道哪个key是唯一的,哪个key不是唯一的——这是由数据表设计人员所给出的,在数据库面板中被声明过的。所以它搜索key的时候会考虑这个问题。
在结点中进行搜索的几种方式
在节点内部搜索,就是在排好序的序列中检索元素,手段通常有:
线性扫描:one by one。

二分查找:自己去看数据结构查找章节的二分查找法。
插值:通过 keys 在结点中分布的统计信息来估计大概位置进行检索。
如何维护重复的索引,重复的key?
方法1:  让每个key不同。
让每个key不同。
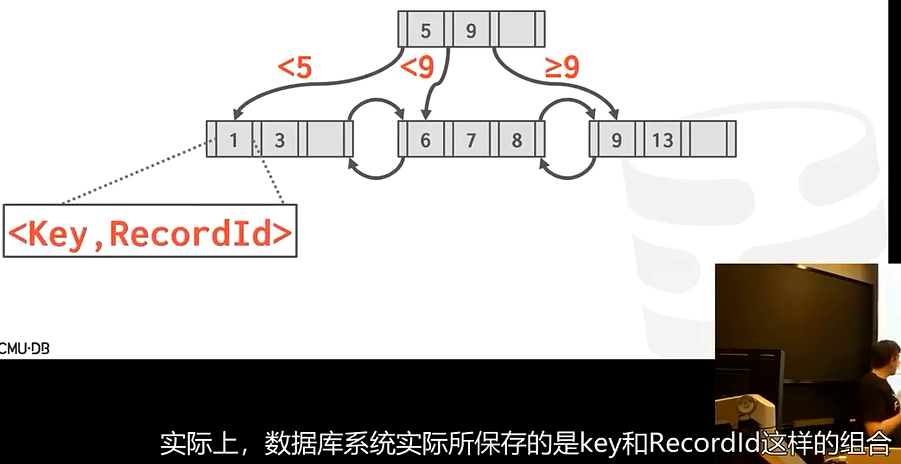
想插入key6,但现在叶子结点位置已满,只能使用overflow
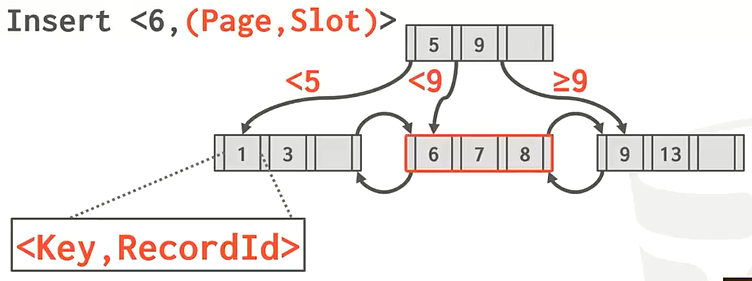
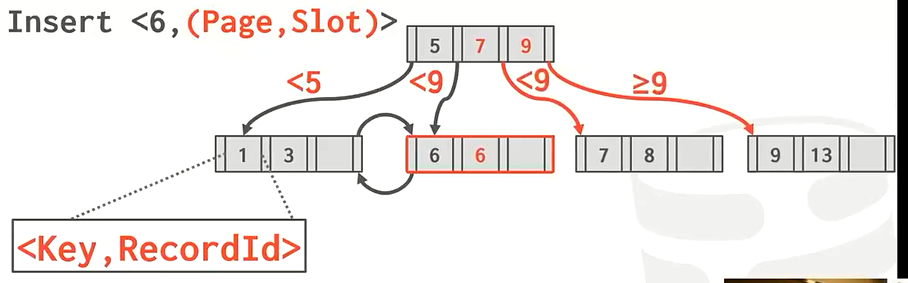
方法2:将重复的key保存在overflow的叶子结点上,竖向保存,就像之前的链式哈希表保存相同key一样。这种情况比较复杂, 
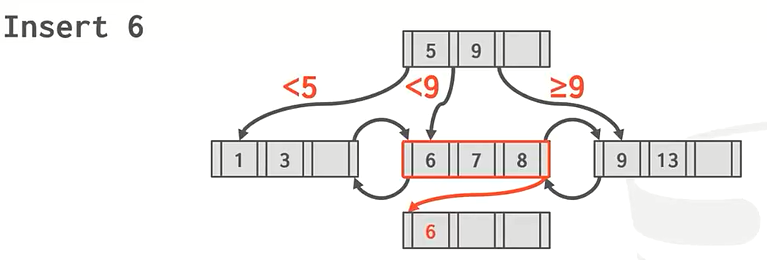
Ps:我们看到上面中间叶子结点中的key是无序的,但实际上很多教科书默认对B+Tree进行了排序,这样做可以使用二分法快速的查找key。
大部分人会选择第一种方法。
问题:这个B+Tree接收的是key,那么在查找到tuple后会返回什么?
答:返回 record id。
问:如果继续overflow了会怎么办?
答: 
B+Tree和hash tables区别

但对于范围查询来说,当知道这些值的分布情况,他就会沿着叶子结点进行索引扫描。
优化:让搜索变得更好
 .
.
前缀压缩
压缩数据方面,使用前缀压缩,前提是我们的key都是有序的。三个key都有共同的前缀 rob,可以把rob提出来:
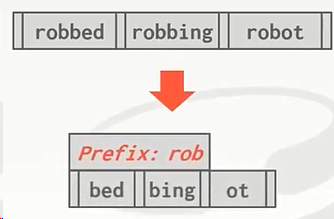
扩展一下,也可以将page id用这种前缀压缩的方式来存储。page id 1000和 1001 ,可以只存储个0 和 1 ,前缀100可以只存一份。
后缀截断
简单的来说,就是路标,我们有南京、上海、杭州的路标,假设只有这三个城市,我们的路标只存储南、上、杭即可。
Bulk Insert
建 B+ Tree 的最快方式是先将 keys 排好序后,再从下往上建树,如下图所示:

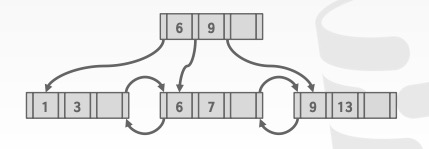
因此如果有大量插入操作,可以利用这种方式提高效率。
Pointer Swizzling
DBMS 每次需要首先从 page table 中获取对应的内存地址,然后才能获取相应的 nodes 本身,如果 page 已经在 buffer pool 中,原来时候我们的结点存放的是page id,然后去告诉缓冲池,让他依据这个page id找到page本身(也就是page在内存中的指针)。
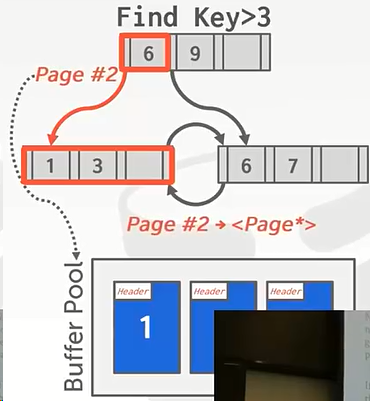
我们可以直接存储其它 page 在 buffer pool 中的内存地址作为引用,从而提高访问效率。目前很多主流的数据库都使用了这项优化。
B+Tree实际方面、MySQL为例的树结构
补充:数据结构B树家族总结
https://segmentfault.com/a/1190000020416577
二叉树 –>二叉树(红黑树)–> B树(又叫B-树)–> B+树
二路查找树 二路平衡查找树 平衡多路查找树 多路、所有的元素都存在叶子节点
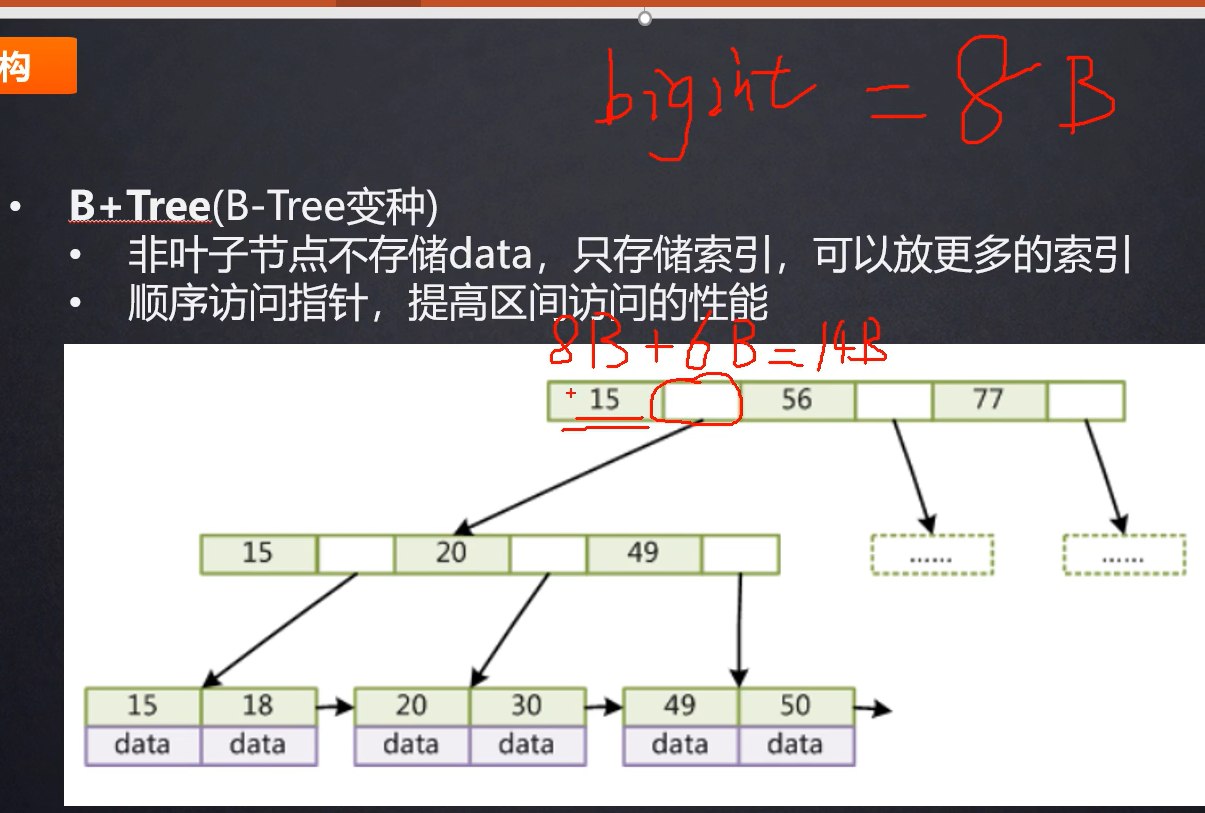
问:使用B+Tree三层能够存放多少数据?
答:MySQL中一个整型占用8B大小,一个指针占用6B大小。MYSQL的第一层、第二层 … …(即:每层的非叶子节点设置为16kb),非叶子节点存储一条数据需要8B+6B=14kB的空间,所以共可存储16kb/14B = 1170条数据。因为叶子结点没有指针,所以可全部存放数据,也就是一个叶子结点占用16KB大小,假设我们存放1KB的数据在每个叶子结点,那么一个叶子结点可以放16条数据。最后计算下两层非叶子加上一层叶子节点共存放1170x1170x16 ~= 21,90万条数据。
补充:MYSQL底层既可以用B树,也可以用哈希表
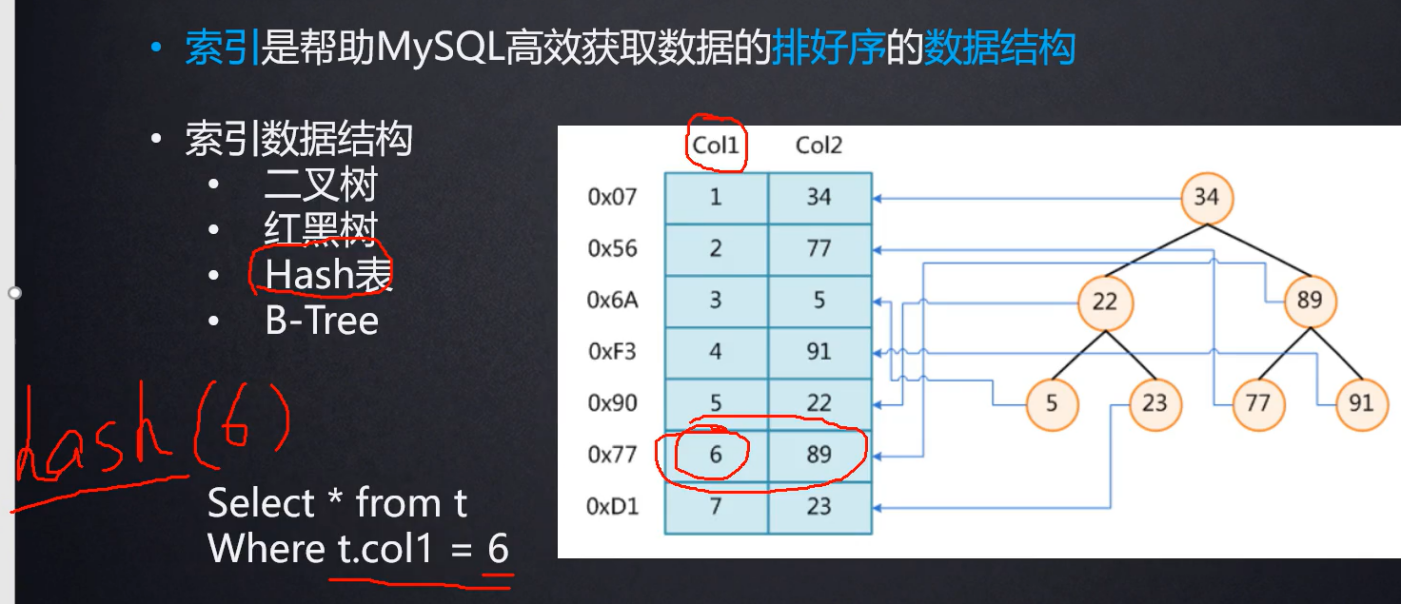
对col1列做哈希运算(散列算法)。
【MySQL索引】Hash索引与B-Tree索引 介绍及区别 :http://blog.sina.com.cn/s/blog_6776884e0100pko1.html
补充:MySAM存储引擎
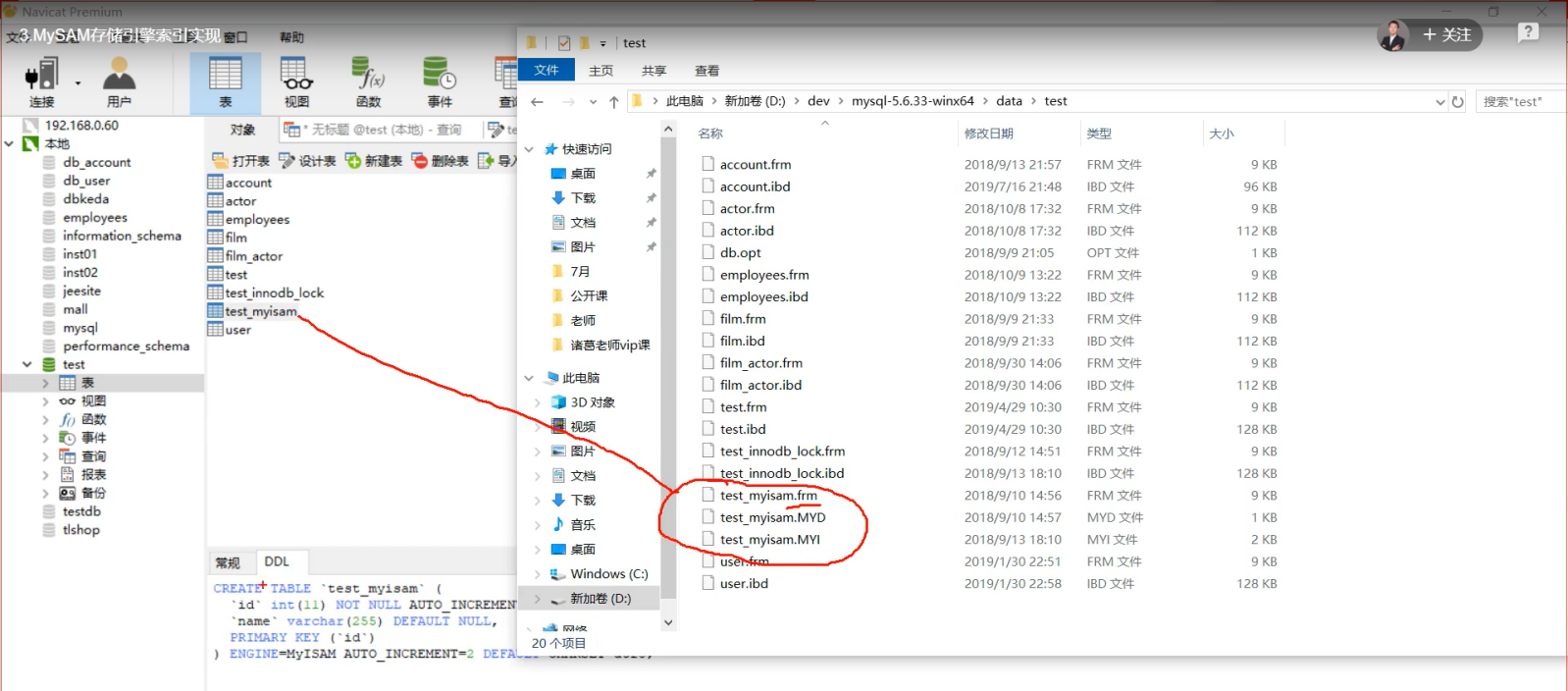
frm:存储表结构
MYD:D是data缩写,存储表的数据行。
MYI:I是index缩写,存储表索引。
索引举例:
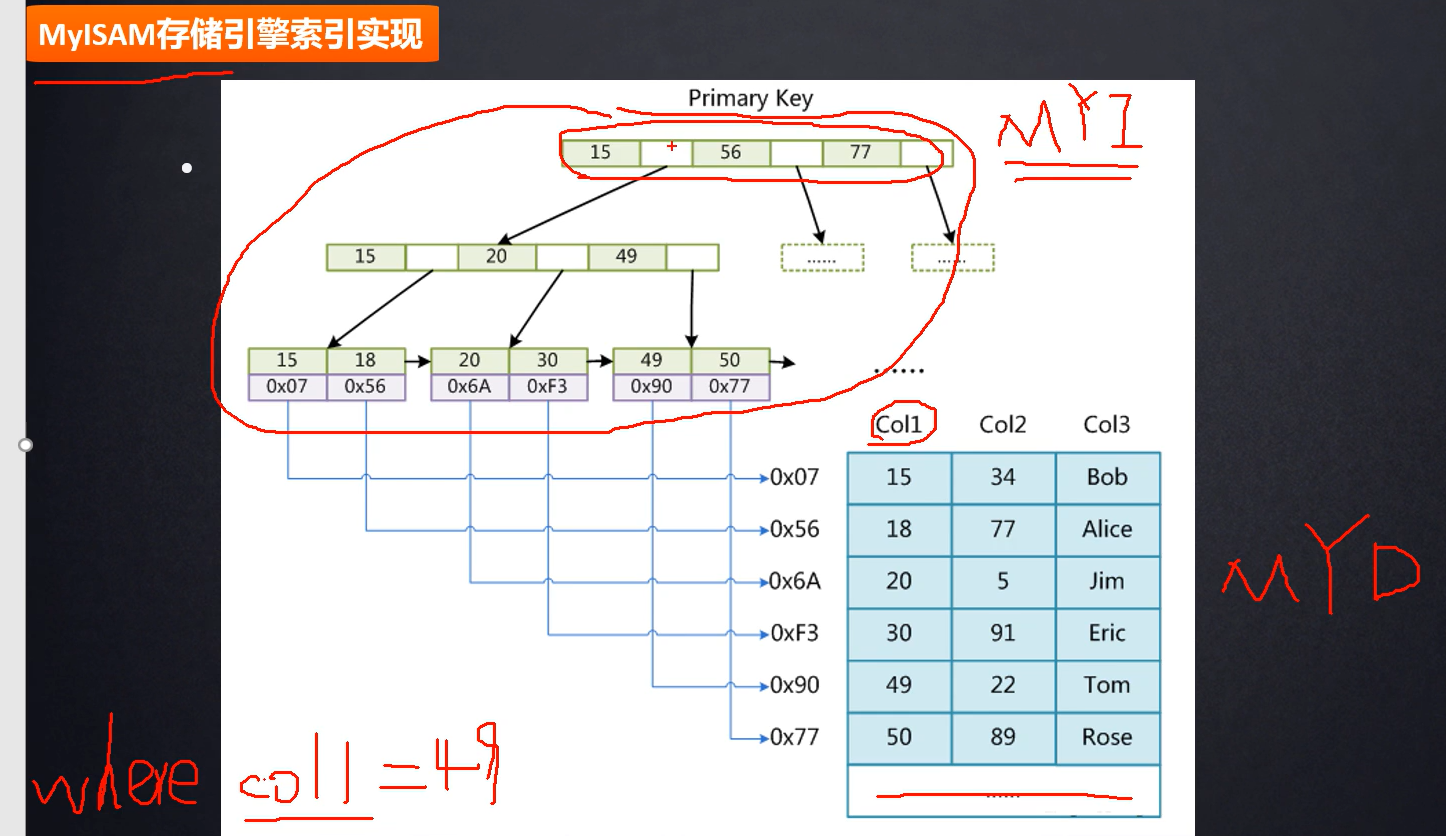
上图是主键索引的查找过程,非主键索引也差不多。
补充:InnoDB存储引擎
存储引擎指的不是形容数据库的,存储引擎是形容数据表的。
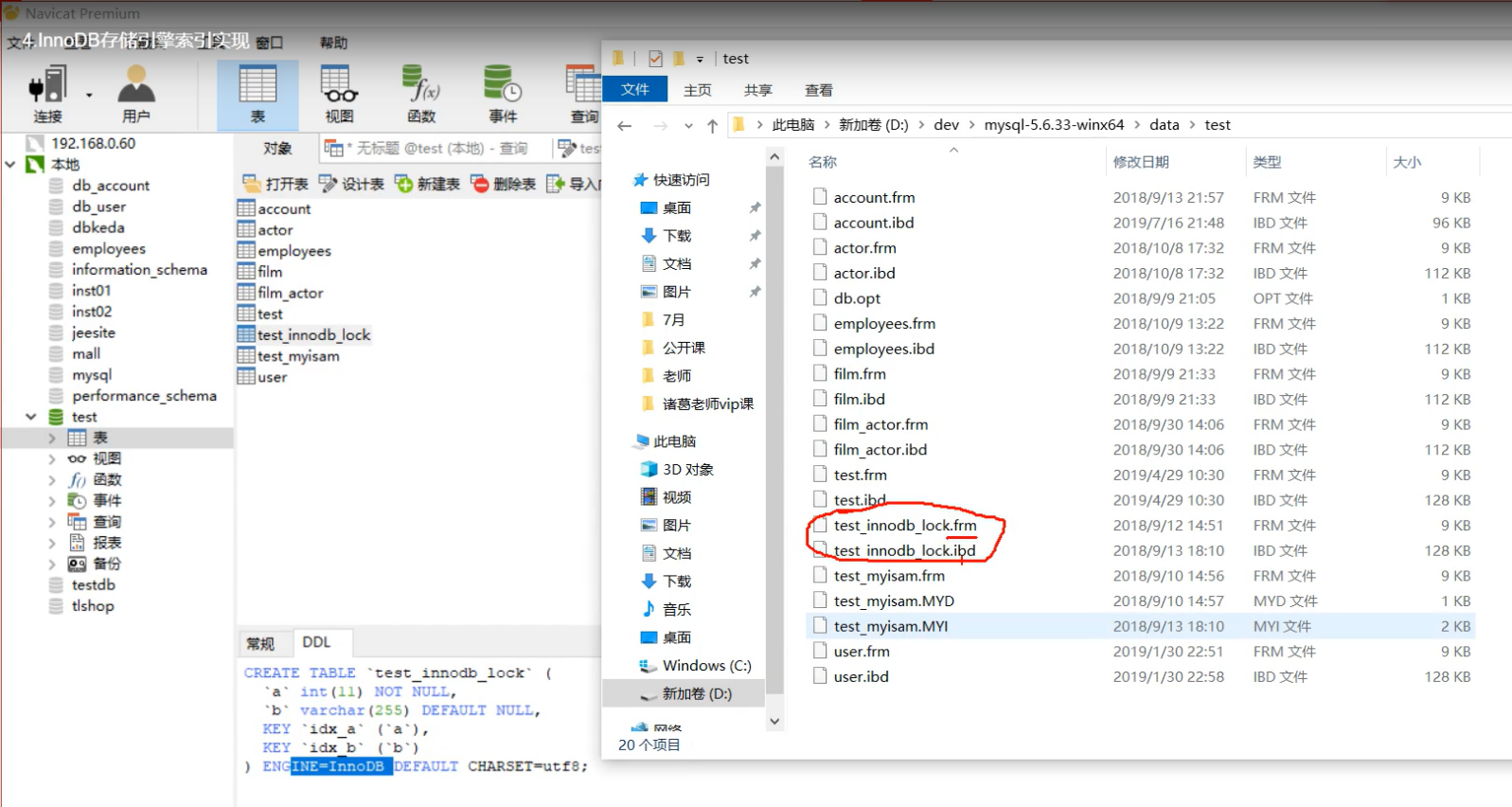
ibd:存储的是索引+数据
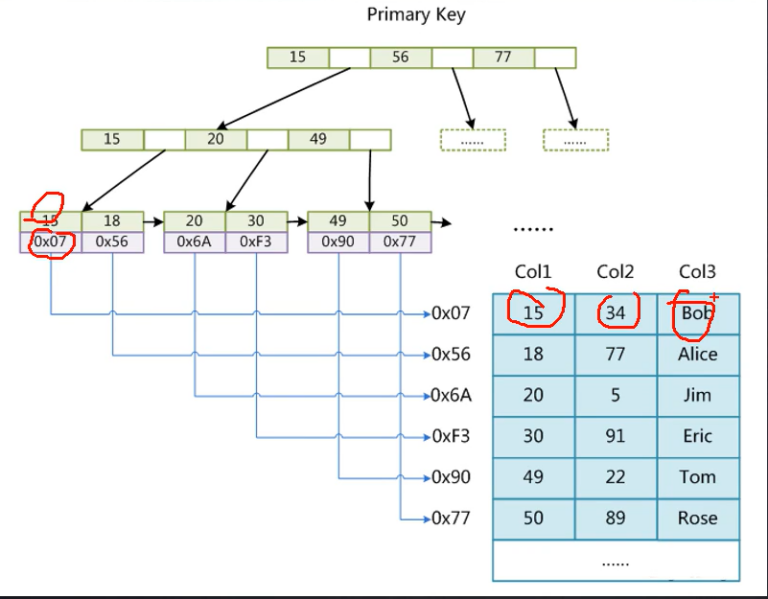
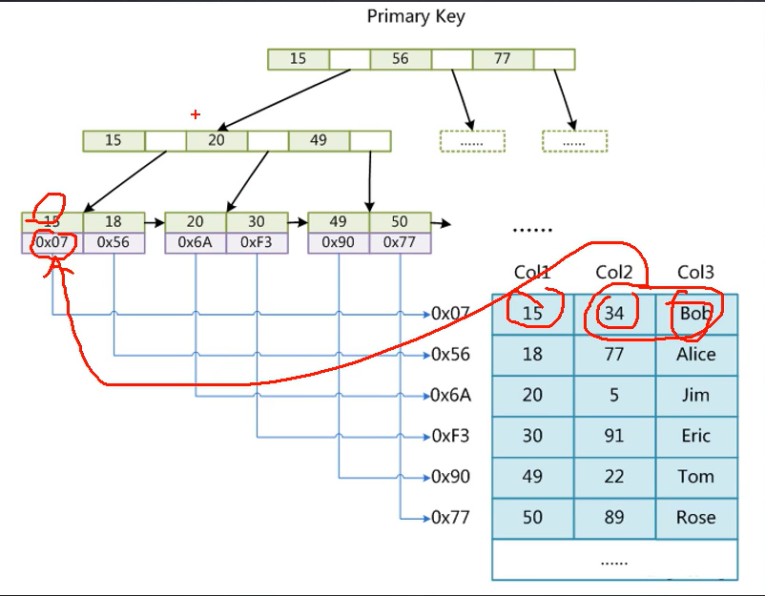
少了一次磁盘IO。
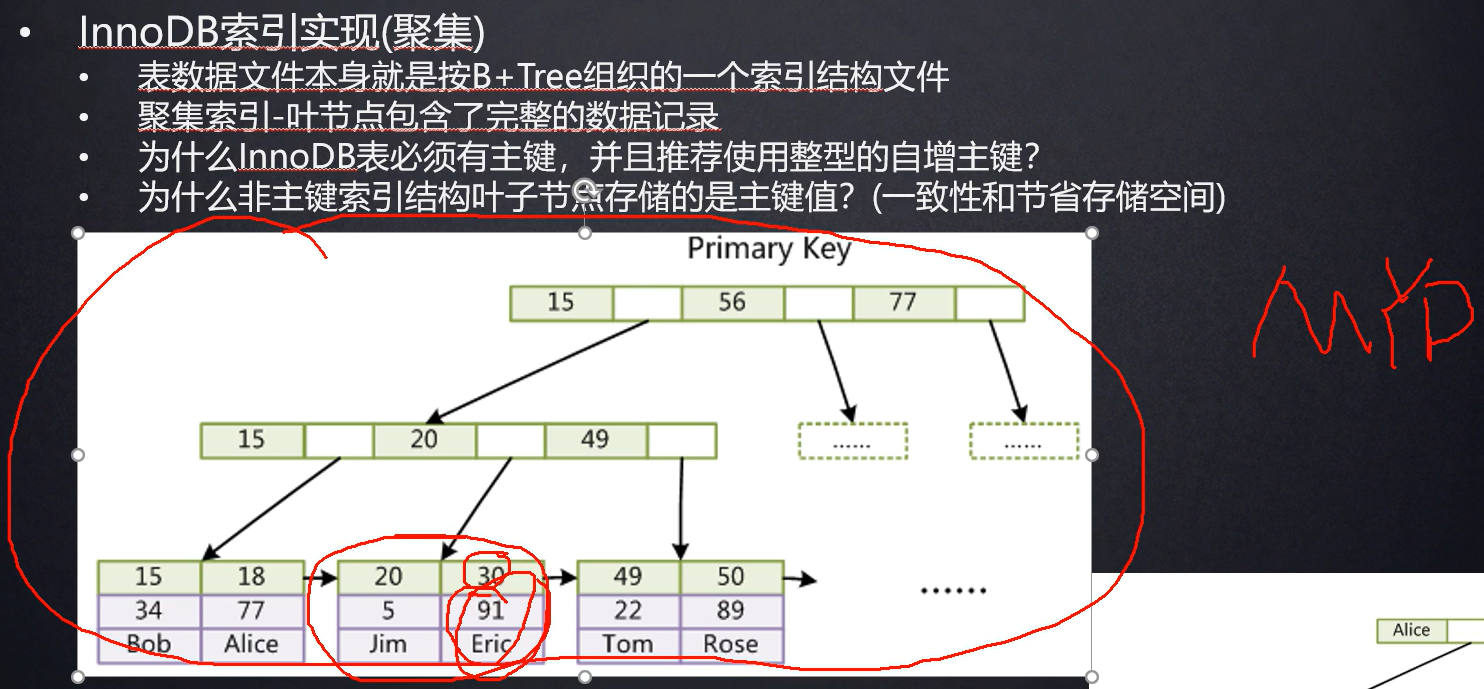
聚集索引:叶子节点包含了完整的数据记录。
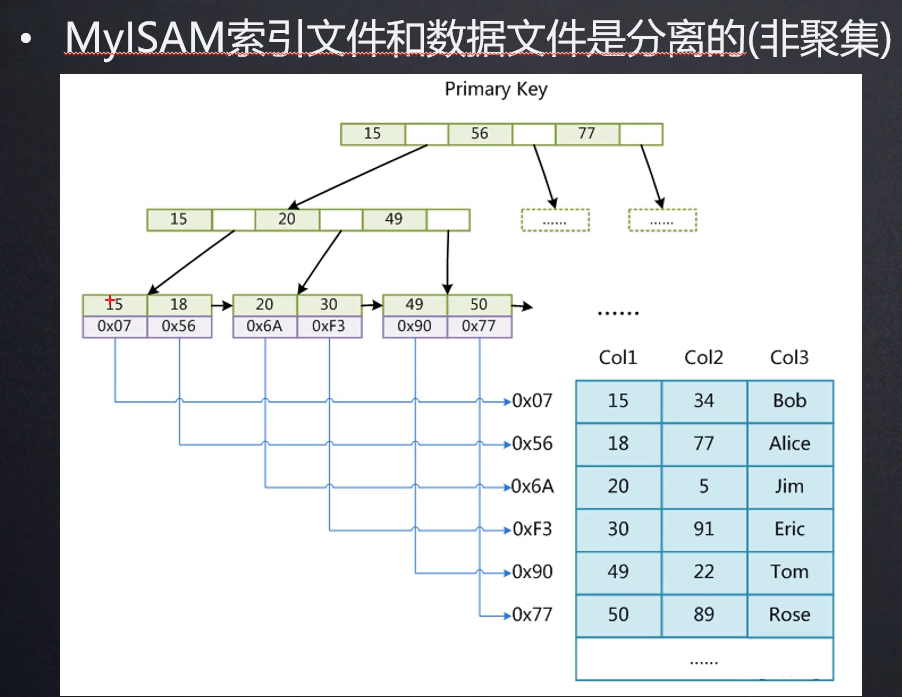
MySAM索引是非聚集索引。

为什么必须有主键:有主键来组织数据,你不建立主键,数据库系统也会自己建主键。
为什么使用整型自增主键:因为B+树要用到一堆比大小步骤。比较数值比比较字符串快多了。如果自增的话永远是往后面插入的,不会导致结点分裂。
用这些索引能干的其他事情:聚簇索引
聚簇索引规定了 数据表本身的物理存储方式,通常即按 primary key 排序存储,因此一个 数据表只能建立一个 聚簇索引。有些 DBMSs会强制性的为其自动生成一个primary key,  而有些 DBMSs 不支持聚簇索引。——主键
而有些 DBMSs 不支持聚簇索引。——主键
更多B+Tree
索引的补充
隐式索引
会为我们的主键PRIMARY KEY、唯一性约束UNIQUE自动生成索引:

部分索引
这种用法非常常见,案例一:



案例二:

覆盖索引
什么是覆盖索引?
建立的索引都可被select需求完整覆盖到。
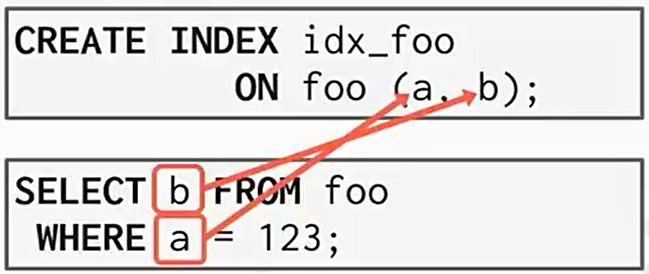
例如上面的部分索引案例二,如果查询的需求都能在索引本身(骨干、党员、干部和经理)找到,这就是全部覆盖了索引。
覆盖索引不需要使用者去声明,DBMS会自动做。

甚至可以在索引中有意加入别的数据列(INDEX INCLUDE COLUMNS):
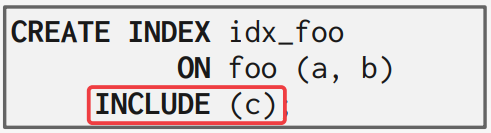


支持这个数据库很少。但许多数据库支持部分索引。
函数式索引/表达式索引
index 中的 key 不一定是 column 中的原始值,也可以是通过计算得到的值,如针对以下查询:

直接针对 login 建立索引是没用的,这时候可以针对计算后的值建立索引:

上述部分索引、覆盖索引、函数式索引本质都是听取了使用者select需求,为了更快查找到业务上需要用到的数据,对B+Tree索引做出调整,“牺牲”一些对使用者来说不会用到的数据。
问题:当创建索引的时候,是什么索引类型?
答:B+Tree
————————————————-
如果创建一张表没有索引他就会顺序搜索。
Radix Tree——B+Tree的替代品
TRIE索引、TRIE key span

TRIE::
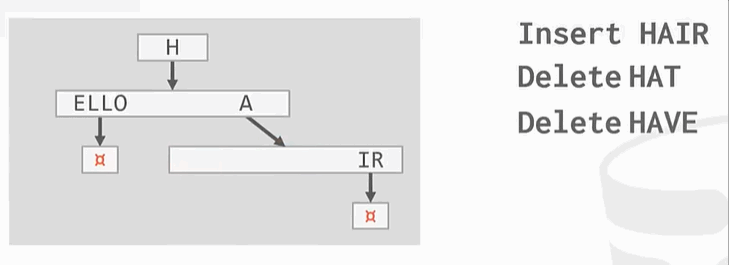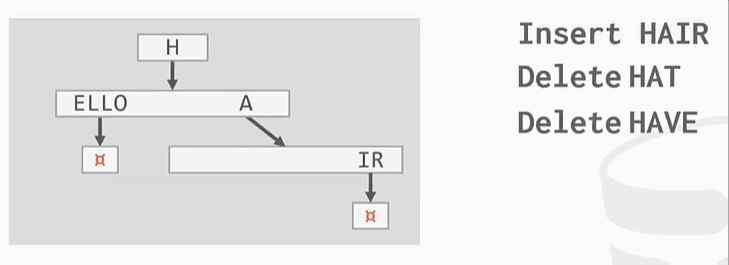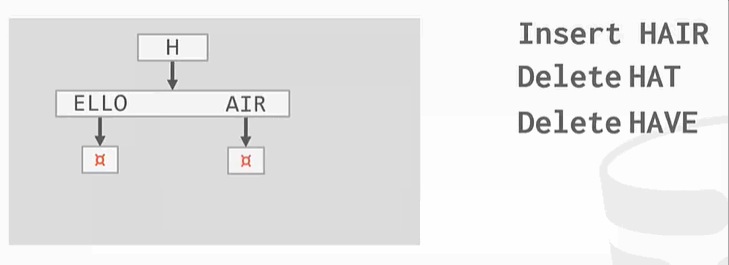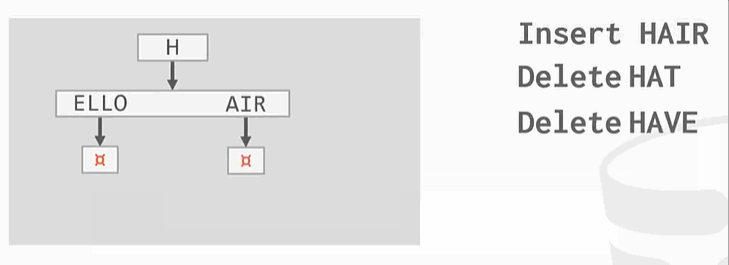
与之前的B+Tree不同,没有在树的叶子结点保存key的完整拷贝,而是会去保存key的digit,digit是key中某些原子子集。例如 
Ps:HELLO HAT HAVE 三个key的第一个digit都是H,这只保留一个。
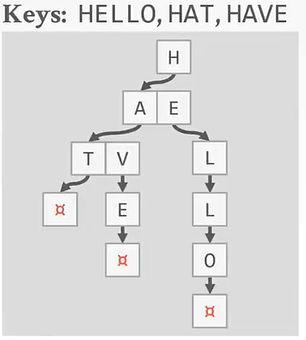
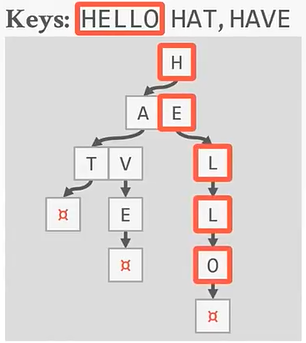
 ,
, 
特点:每个单独的叶子结点不保存key,而是在路径上保存key。这种结构将使用栈来保存每个dight,会有回溯的情况,并且只能退出到分叉点再换分支查找。所以对于点查询(具体查某个key)来说,trie要不b+tree快得多。但是对于扫描查询来说,因为不可以像B+Tree那样沿着叶子结点查找,所以就要比b+tree慢了。
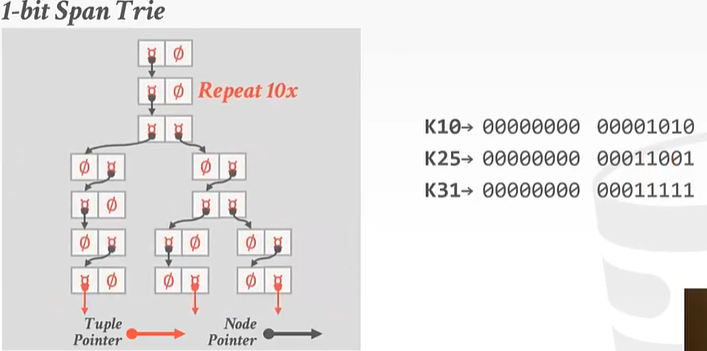
举个例子:最简单的Radix Tree——1 bit
1bit树代表着每一层我们都只会看1个bit。
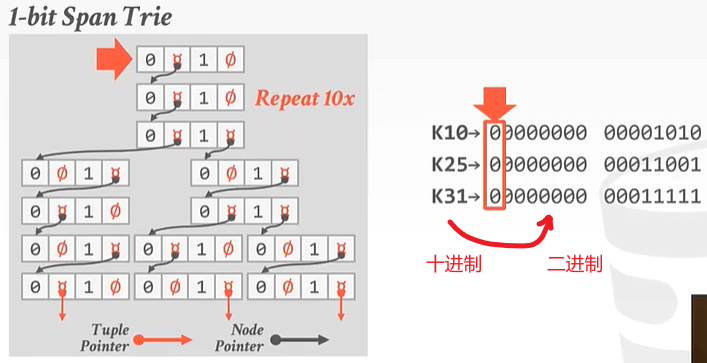
接下来的[2, 11] 10个数字都是0,步骤一样,可以省略。
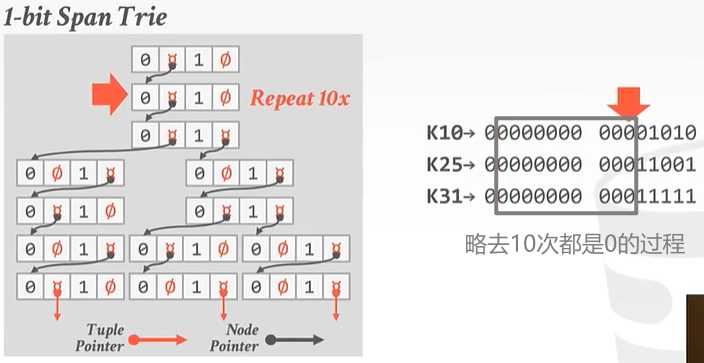
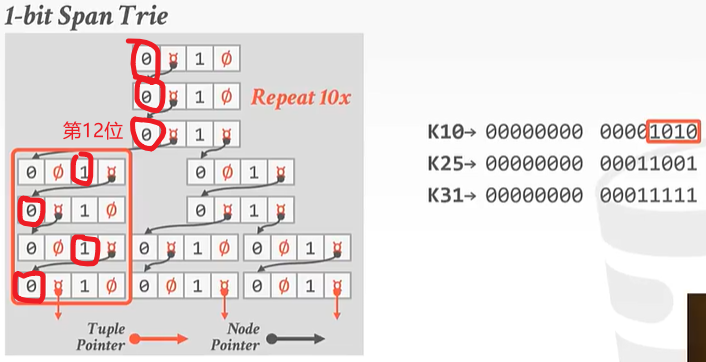
到了第12个数字,对于K10来说它的二进制第12位是0,所以应该走左边。是1的走右边。
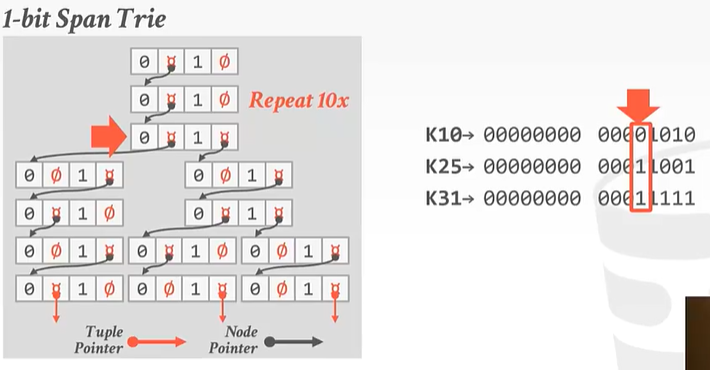
对于K10来说:

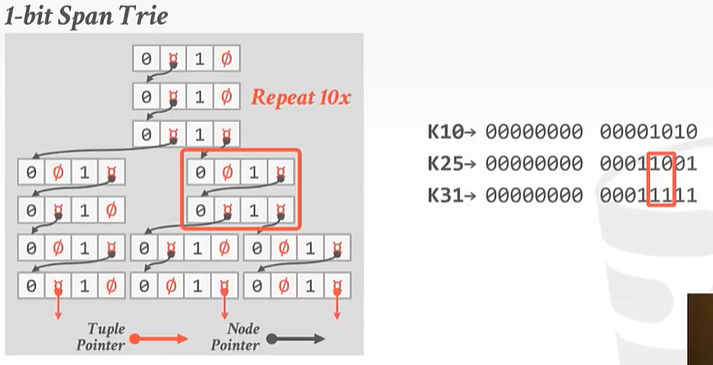
对于K25和K31:
优化:水平压缩 – 只保存指针
radix tree

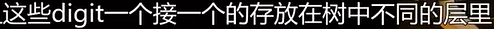
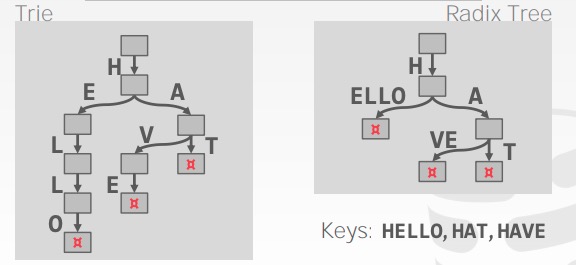
插入操作:
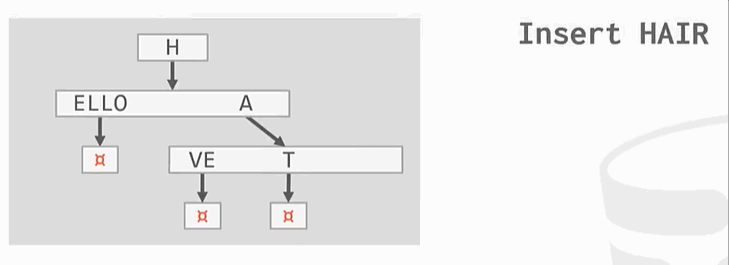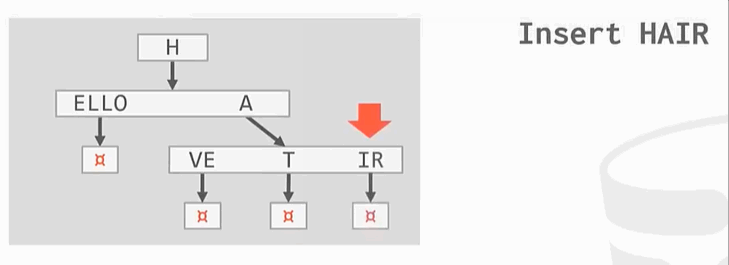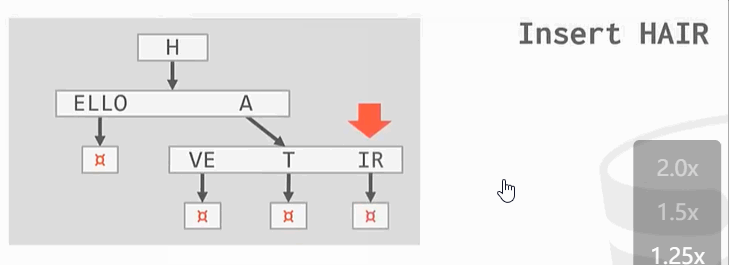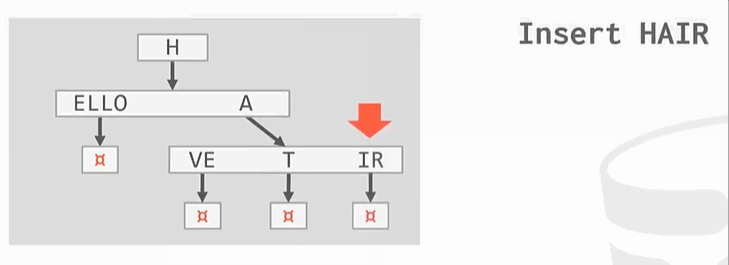
删除操作:
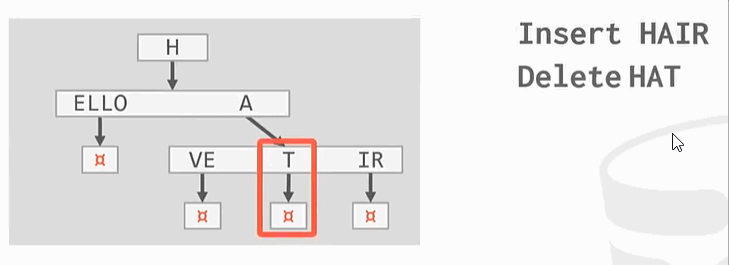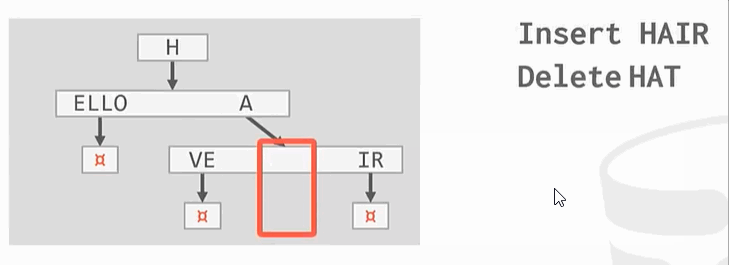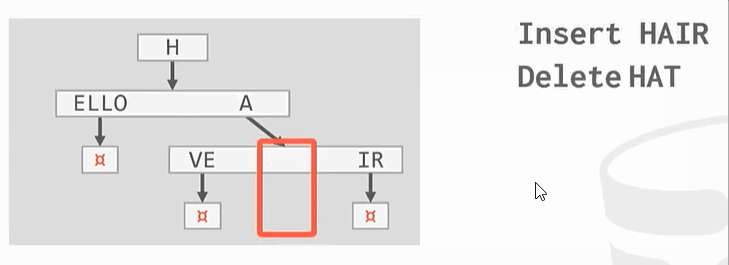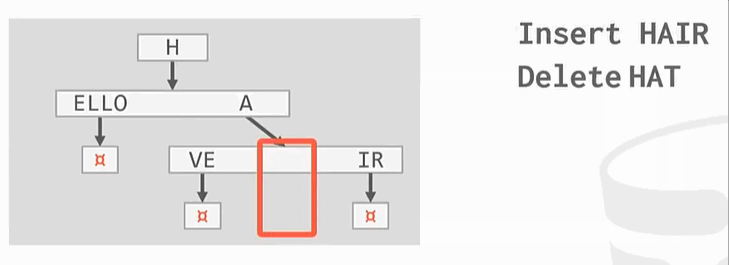
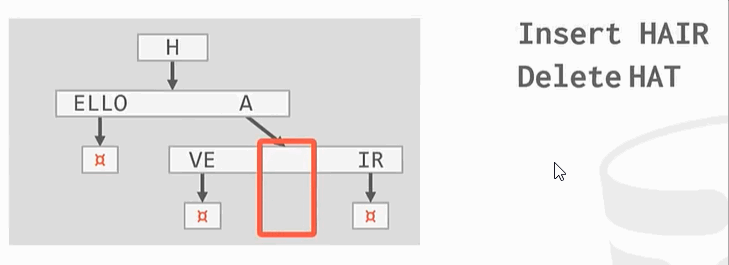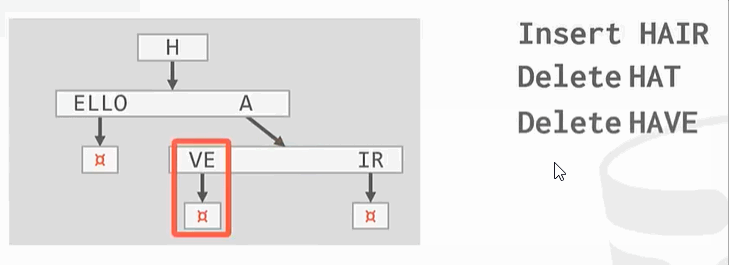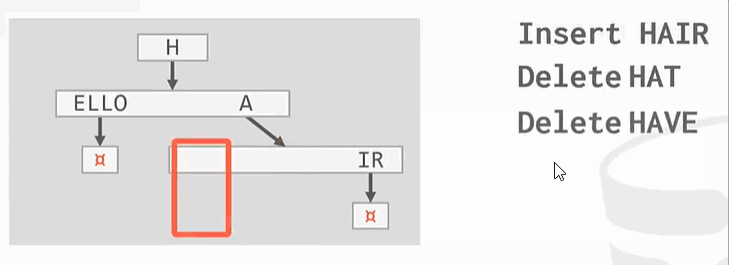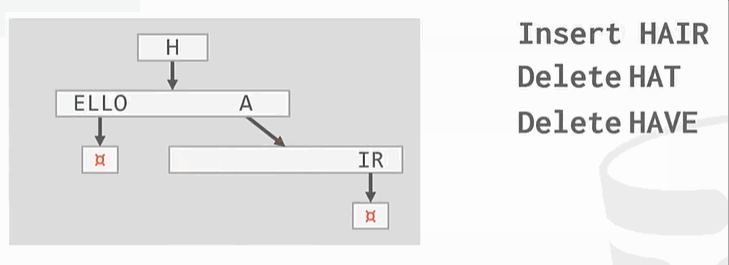
整理:
商业上:  ,
,  ,它是基于radix tree构建出来的。但目前B+tree仍然是霸主地位。
,它是基于radix tree构建出来的。但目前B+tree仍然是霸主地位。
倒排索引:解决关键字搜索问题
总结:到现在为止,hash table、B+Tree、radix tree能够解决范围查找和精确查找问题。但是对于部分查询支持的就不是很好。例如百科上搜索有关 上海 开头的所有关键词。

这里只是讲下有这么个东西,不会展开讲。在你遇到无法用B+tree索引的东西时候你可以想到倒排索引。
倒排索引可以解决这个问题。

倒排索引也有叫全文搜索索引的。现在的数据库系统基本支持这种索引方式,你只需要说你想要一个全文搜索索引。
商业上:有专门为此卖点的数据库系统,全文搜索数据库。

 ,其他数据库是有原生支持的。对于原生支持倒排索引的数据库,可以在数据更新、删除的时候更新这些索引,但如果是像MySQL这样原生并不支持倒排索引的数据库可以通过定时任务去更新倒排索引。
,其他数据库是有原生支持的。对于原生支持倒排索引的数据库,可以在数据更新、删除的时候更新这些索引,但如果是像MySQL这样原生并不支持倒排索引的数据库可以通过定时任务去更新倒排索引。
关于倒排索引的实现,最简单的方式就是让每个词指向一个tuple,然后通过计数的方式来判断“远近”从而寻找其关联程度。这种具体的实现不展开讲解,倒排索引的实现在CMU 11-442或11-642搜索索引课程。
除了以上的索引,还有许多索引。
 ,在绝大多数情况下B+tree索引已经足够我们使用了。其他的索引会在图像数据库、数据库中存在。
,在绝大多数情况下B+tree索引已经足够我们使用了。其他的索引会在图像数据库、数据库中存在。