本文已收录到:CMU数据库系统学习笔记 专题
视频课程(中字幕)、课件
Buffer Pools
课件:
引言
上一讲数据库存储中我们讲的是问题1,本节来讲问题2:
- 如何使用磁盘文件来表示数据库的数据(元数据、索引、数据表等)
- 2.(本节)如何管理数据在内存与磁盘之间的移动

因为数据库系统无法直接在磁盘上进行操作。这是冯诺依曼结构的特性,计算机是无法直接处理硬盘中的数据的,需要先将其加载到内存中。
空间控制策略:将 pages 写到磁盘的哪个位置?使经常在一起使用的page在物理上尽可能靠近。
时间控制策略:何时将pages读入内存,何时将pages写回到磁盘。目标是减少从磁盘上读写数据。
引出问题:
我们必须决定对哪个page进行写出。这就是今天要研究的问题。Ps:这里有点像操作系统里的页置换。
系统的其他部分无需去知道和关系哪些东西在内存里面,哪些东西不在内存里面。他会等到你拿到你需要的东西后,给你返回一个指针,然后呢,你去做你想做的事情。
现在,我们研究如何去创建一个buffer池管理器(buffer pools manage)。有的会叫做buffer缓存(buffer cache)。buffer池是一个由数据库系统所管理的内存。
本节的提纲如下:
- Buffer Pool Manager
- 替换策略
- 分配策略
- 其他内存池
缓冲池管理器——一段由数据库系统管理的内存
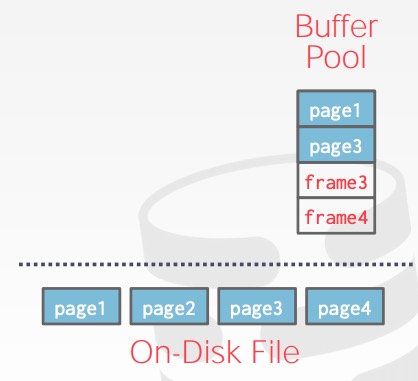
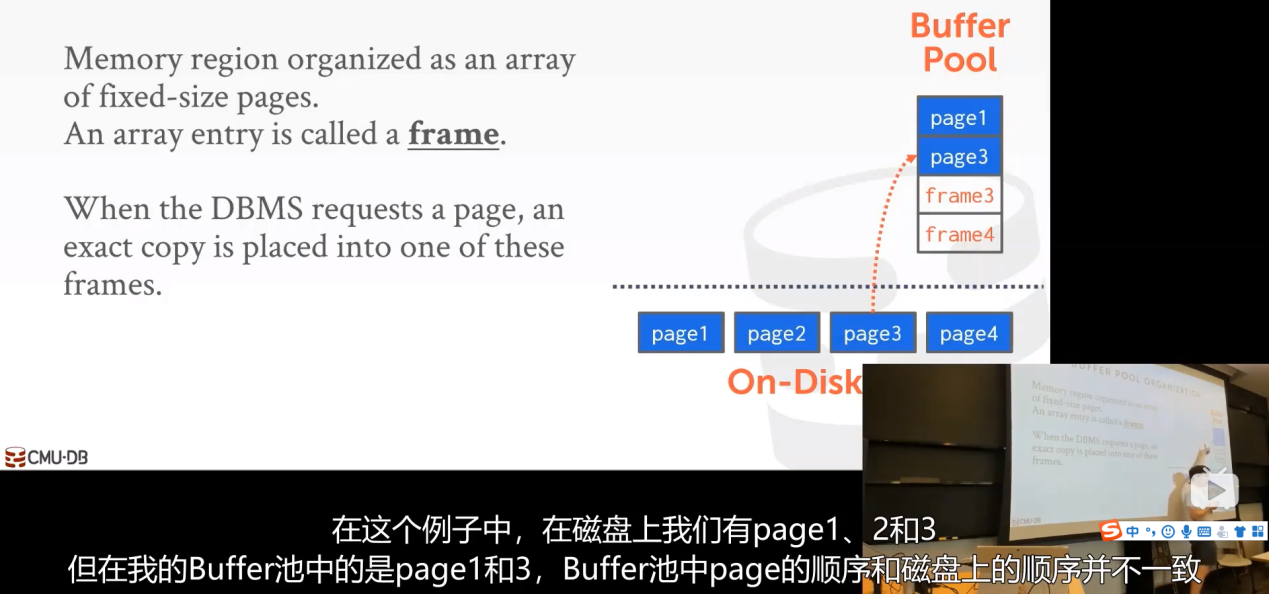
DBMS 启动时会使用malloc申请一片内存区域,我们将这段内存区域分成一个个固定大小的chunk并将这块区域划分成大小相同的 pages,为了与 disk pages 区别,通常称为 frames。
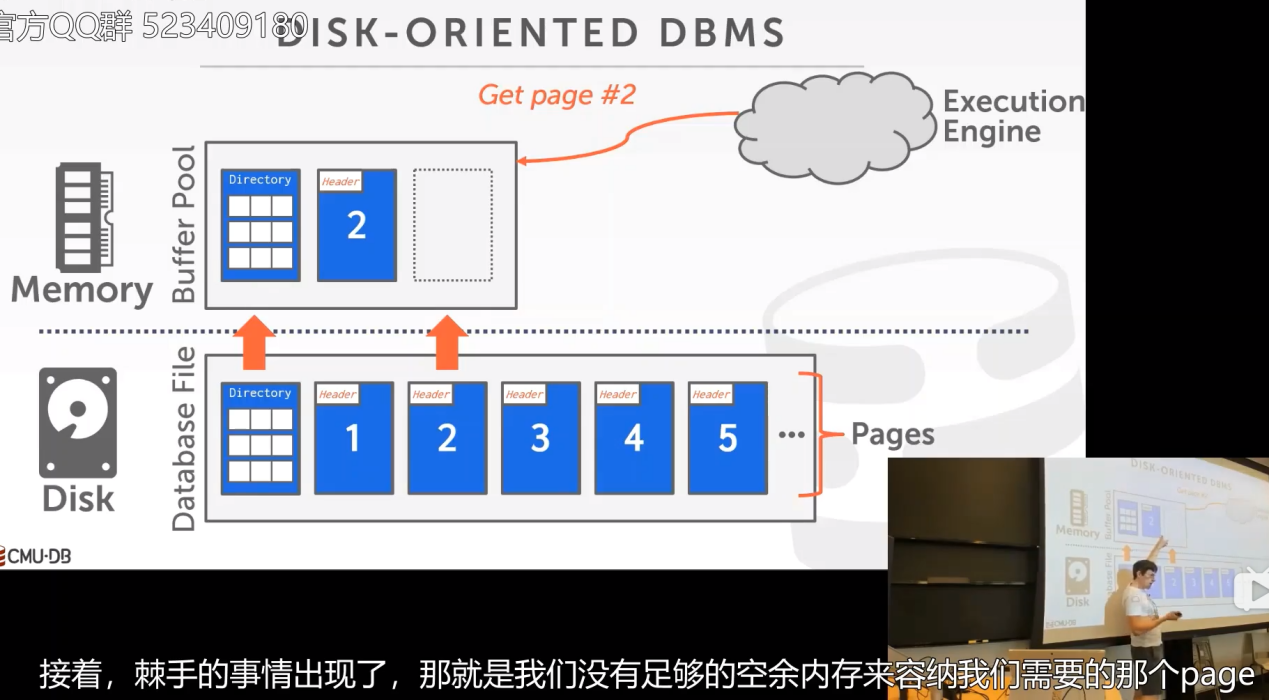
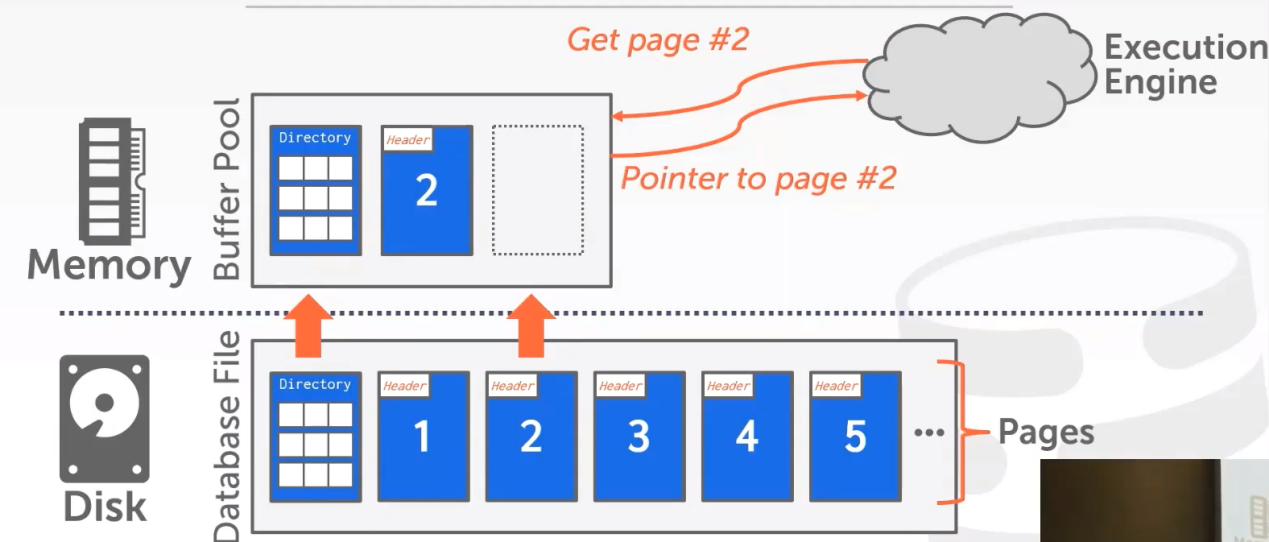
当 DBMS 请求一个 disk page 时,它首先需要被复制到 Buffer Pool 的一个 frame 中,如下图所示:
并且会把从磁盘中读取到的所有page放入到frame中。
此处我们使用malloc手动分配内存。请注意:这段内存完全是由数据库系统控制的,不是由操作系统来分配这些内存的。
slot相当于操作系统里的页表项,用于存放page的地址。对于Buffer池凯硕,这叫frame,对于page来说,是slot。
当系统发出一个请求表示想要一个page,会发生什么?
会先去buffer池中看是否存在这个page,

注意:将磁盘page拷贝到buffer池的frame中,这个顺序是任意的,不一定要与磁盘中page的顺序一致。同时这就是很简单的拷贝,我们暂时不考虑压缩这种问题。这个page在磁盘中是什么样的,在内存中就什么样,没任何改变。同时我们对其他可能需要的page也同样调出到内存中。

所以,DBMS 会维护一个 page table,page table所做的事情:
- 负责记录每个 page 在内存中的位置,
- Dirty Flag,这个flag给我我们当我们读取到这个page后,这个page有没有被修改过,甚至还要追踪是谁进行了这项修改。
- 引用计数,记录当前正在使用、正在查询该page的线程数量。如果该page还在被引用的话,我们并不想让它写回到磁盘上。
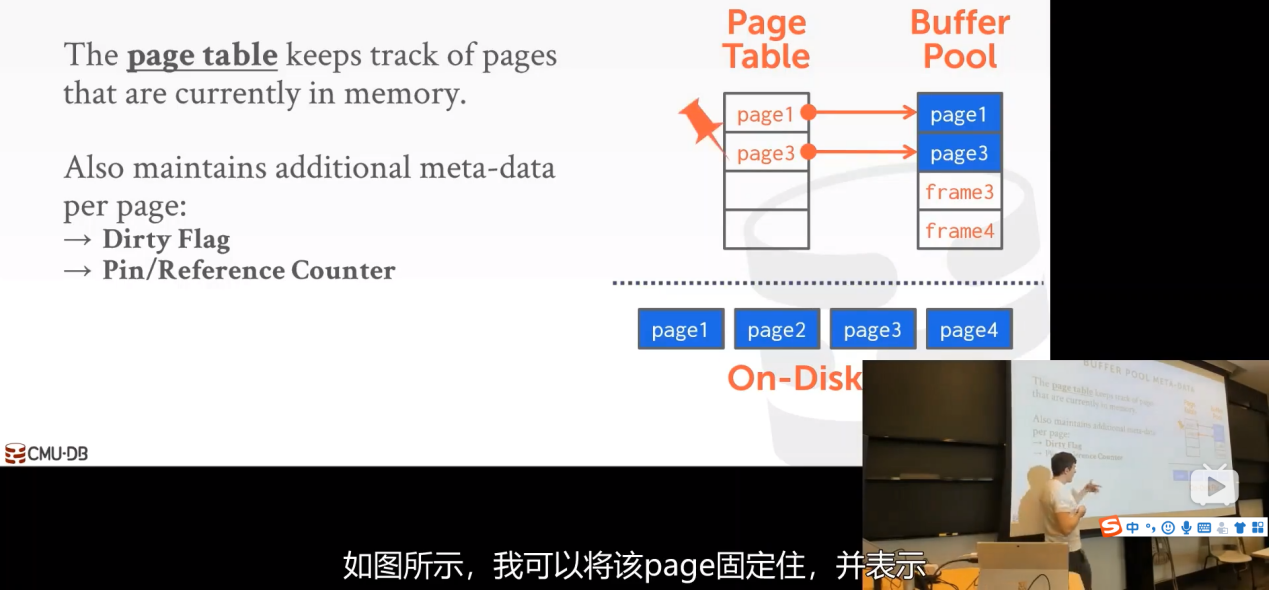
这也将阻止我们去移除那些还未安全写回磁盘的page。
- 其他元信息
上述这些也说明了为什么mmap是个糟糕的方案,操作系统根本不会考虑这些情形,他只会换入换出。在FreeBSD上操作系统允许数据库系统做这些自主化的操作,但是像Windows和Linux就不会给我们数据库系统这些自定义的操作权限。
page table本质是hash table,用于追踪这块内存(也就是buffer池)中有哪些page。如果我们想要找一个page,通过page table和page id就可以知道这个page在哪个frame中。
锁
当被请求的 page 不在 page table 中时,DBMS 会先申请一个 latch(lock 的别名),表示该 entry 被占用,然后从 disk 中读取相关 page 到 buffer pool,释放 latch。以上两种过程如下图所示:


Ps:P15讲 11分48秒
lock(锁)与latch(锁存器)区别:

locks是数据库系统中的抽象锁, locks可以
- 可以保护数据库中的内容,例如tuple、表等。
- 事物在运行时会持有这个lock。
- 交易期间持有需要能够回滚更改。——后面并发控制等章节会讨论
- 数据库系统会为使用数据库的人提供这个API或者函数,为程序开发人员使用。
latches,是操作系统中的锁,

 他可以
他可以

 用来保护DBMS的关键部分与其他线程之间的互斥。
用来保护DBMS的关键部分与其他线程之间的互斥。- 保护DBMS在运行期间进行独享。
- 不需要能够回滚更改。
这些内容也会在第一次project中涉及到。

mutex:互斥


关于回滚方面的问题会在后面的并发控制中讲到。后面会花费一节课的时间专门讲解这个问题。
区分page Directory与page table
page Directory是数据库文件中page id 到page位置的映射,我们对pageDirectory所做的改变必须持久化,所有变更必须记录到磁盘,重启后可以让 DBMS 找的page。

page table是buffer池frame到硬盘page的映射,这不需要保存到磁盘上。是一种在内存中的、临时的映射表,无需在磁盘中备份。

关于实现:不用持久化,我们可以使用hashmap或hashtable实现。

但是我们必须保障是线程安全的,不用持久化。
补充:线程安全意味着两个线程不能同时修改同一个对象,从而使系统处于不一致状态。也就是说,在遍历字典时不能修改字典。这有点像python中的字典,依赖键值对存储。无需关心持久化,但需要确保线程安全,Python 内置类型 dict,list ,tuple 是线程安全的。
缓冲池优化
接下来讨论如何为buffer池分配内存。分为全局策略和局部策略。大多数系统会同时尝试两种优化。
全局策略:为数据库系统整体考虑。
局部策略:为具体的查询或者事物考虑。
 ,仅仅需要找到最近最少使用的page,将其移除即可。但是这种策略对某个特定的查询来说可能会很糟糕。
,仅仅需要找到最近最少使用的page,将其移除即可。但是这种策略对某个特定的查询来说可能会很糟糕。
多缓冲池
我们可以分配多块内存区域,构造多个buffer池。让每个表都有一个buffer池。在每个buffer池上使用局部策略。这样就可以为你放入的数据量身定制,选择最好的局部策略。
例如,有些表需要进行一系列的循环扫描。


还可以减少 latch 竞争,改善局部性。





这意味着我会遇到多个线程争抢同一个latch的情况,他们会访问同一个page表,这就会导致多核处理器没法完全利用性能。因为关键部分会有争抢。

——即现在的多buffer pool解决方案。


这样就大大的减少latch竞争,虽然现在的根本原因是磁盘是瓶颈,但这样至少我们不再担心latch竞争这种情况的出现。

 oracle中可以做很多关于多缓冲池的事情,mysql中就比较简单些,只让你设定你要创建几个缓冲池。oracle中还可以为每个page指定策略,做很多疯狂的事情。
oracle中可以做很多关于多缓冲池的事情,mysql中就比较简单些,只让你设定你要创建几个缓冲池。oracle中还可以为每个page指定策略,做很多疯狂的事情。


对MySQL来说,是这样维护的:

这就有点像数据结构中的哈希表了。通过这种方式可以快速找到你想要的数据。
预读取、mmap
下一步我们能做的优化是预读取,操作系统就可以帮助我们实现这种预读取处理。用mmap
扫描共享

P16讲第12分
通俗的理解为搭别人的顺风车。复用从磁盘中获取的数据用于其他查询。这和结果缓存(result caching)效果相同。通俗理解:你办事情,我在结束的地方等你,等你办好,我也用你的结果,然后去办自己的事情。

游标共享:Oracle支持的,基于扫描共享的技术


P16 14:50
Buffer Pool Bypass
当遇到扫描量非常大的查询时,如果将所需的 pages 从磁盘中一个一个的换入 Buffer Pool,将会造成buffer池的污染,因为这些 pages 通常只使用一次,而它们的进入将导致一些可能在未来更需要的 pages 被移除,因此一些 DBMS 做了相应的优化。
思路:分配一小块内存给那个线程,当他从磁盘中读取page时,不管这个page已经在buffer池中了还是不在,都要放在这一小块另开辟的内存中,当查询完成时就会释放掉这块内存,这样不会污染buffer池。
目前主流数据库都支持:

操作系统page缓存
数据库系统有缓冲池,操作系统也有硬盘与内存之间的缓存策略,这会导致一份数据(一份磁盘page)分别在操作系统和 DMBS 中的缓冲池被缓存两次。因此大多数 DBMS 都会使用 (O_DIRECT) 来告诉操作系统不要缓存这些数据,Postgres是主流数据库中唯一使用了操作系统page缓存得数据库。
为什么这样做?
因为我们数据库缓冲池中有一份副本,而操作系统也缓存了一份磁盘page副本,在我们更新数据库缓冲池中的page后,操作系统缓存的那份page就是旧的,这显然是一份多余的数据。作为数据库系统,我们希望自主管理我们的page,不想让操作系统掺和。
另外,不同操作系统的page缓存策略也是不同的,同一种数据库有linux也有Windows版本,为了保证跨操作系统之间的一致性,这也需要数据库自己本身来管理一切。
替换策略
当缓冲池空间不足时,读入新的 pages 之前必然需要 DBMS 从缓冲池中移除一些pages。这与操作系统中的置换算法差不多。



因为那些高端数据库拥有非常复杂的替换策略,会去统计page相关使用数据以便做出最好的决策。但也并不是说开源数据库和一些较新的数据库的替换策略很糟糕,这里只是相对的。下面讲一个非常简单的技术。
LRU(最近最久未使用算法)
这一部分可以参考操作系统的页面置换算法,清华大学操作系统课程笔记。

基本思想就是追踪最后被访问的时间戳,我们仅需去看哪个时间戳最老,将其置换出去即可。
具体实现方面,操作系统页面置换LRU算法提到了使用栈来解决,当然这里也可以使用队列来实现,如果有人读写了这个page就将其从队列中剔除然后放在尾部,头部的page会被一个个换出。
Clock(时钟置换算法,项目中需要实现)
Clock是LRU的一种近似算法,无需追踪时间戳而是追踪标志位(这一部分在操作系统中页面置换算法里也讲过,可以回顾参考)。


思路:最开始,被换入的内存中的page标志位都是0,一旦被访问了就将其标志位置为1。

当需要换出时,就像一个钟表一样顺时针或者逆时针旋转,如果发现指向的这个page标志位为1就将它改为0,然后旋转,发现标志位是0的下一个page,就将其换出。
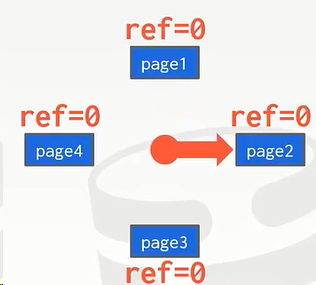
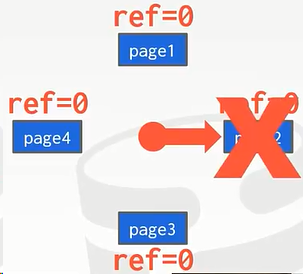
这种算法之所以是LRU的近似算法是因为LRU算法记录了最久,是单纯的按照时间来决定换出的。但是Clock算法(时间片轮转调度算法)的时间窗是固定的,重点关注是“未使用”。
缺点:Clock算法的缺点是sequential flooding(顺序洪水)问题。执行某种特殊的操作时会连续的将page换入,这会导致我们需要的page被从缓冲池中移除掉。——这一部分跟上面Buffer Pool Bypass遇到的问题一样。
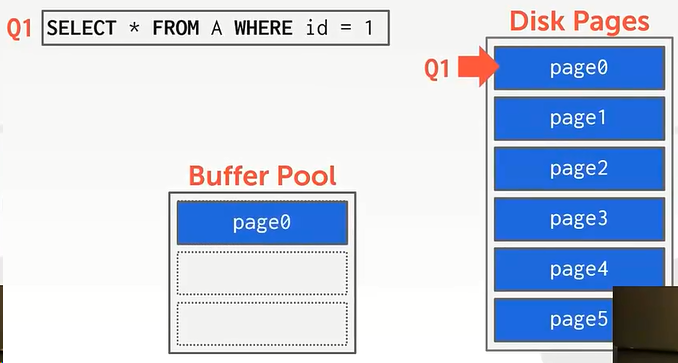
我们来看下面的举例:
- 执行Q1,当id=0时,读取了page0,将page0换入到缓冲池:
- 接下来执行Q2,以此读取page1、page2、page3、page … …等等后面的page。
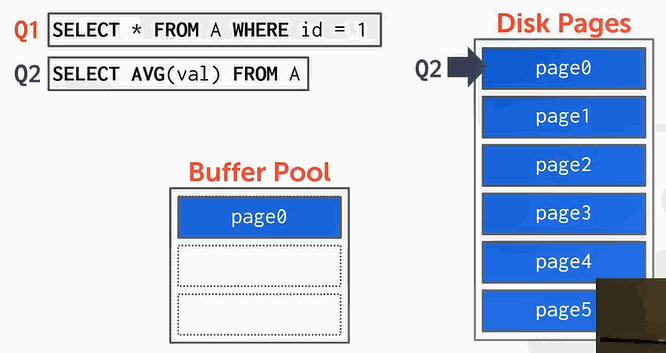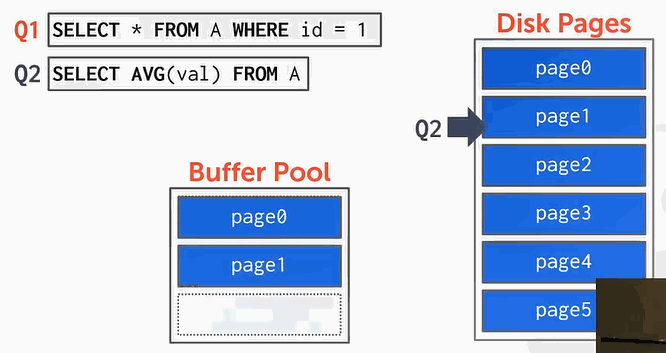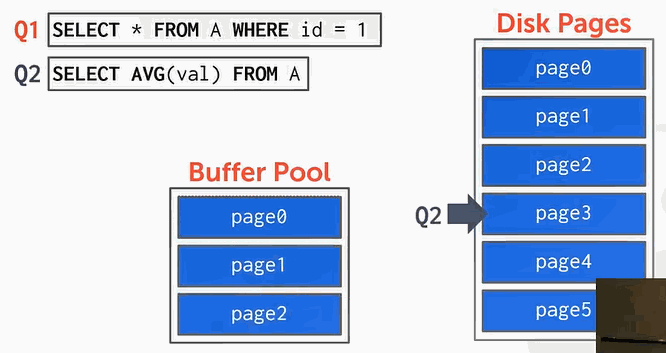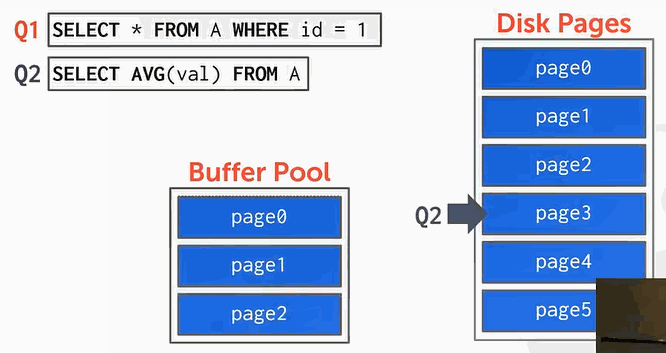
但是在想换入page3的时候,缓冲池空间不够了。如果使用的是LRU算法则会把page0换出。但是我们还要用page0,没有办法,page0只能不断的被换入换出,这样就降低了效率。
我们有三种方法来解决上述问题。
LRU-K


越复杂的数据库系统可能采用这种方法,MYSQL可能就是,——Andy老师上课说的。
多缓冲池

这里并不是将我所扫描的这张表放入全部的缓冲池中。而是各说各的事 ,会移除对我而言最近最少使用的那个page,而不是以全局角度。
优先级提示
有时候 DBMS 知道每个 page 在查询执行过程中的上下文信息,因此它可以根据这些信息判断一个 page 是被保留还是移除。——这比操作系统page置换策略“聪明的多”
举例:
看视频 CMU 15-445 18 Buffer Pools 04 第9分07秒。
脏页
 脏页其实就是缓冲池中被修改过的page,它需要写回到磁盘page中。
脏页其实就是缓冲池中被修改过的page,它需要写回到磁盘page中。
这里我们讨论的是脏页刷新策略。我们知道移除一个脏页的成本要高于移除一般 page,因为前者需要写回到磁盘中,后者可以直接 drop掉。
当我需要从缓存池中移除page时,最快的方法就是找到一个未被标记脏页的page将其移出,将一个新的frame放入缓冲池中。

为了避免必须立即将缓冲池的page换出以腾出空间的问题,除了直接在置换策略中考虑到,有的 DBMS 使用 后台写 的方式来处理这个问题,它们定期扫描 page table,发现 脏页就写入 磁盘,这样在置换时就无需考虑脏数据带来的问题。
因此,数据库系统中会有一个定时执行任务的线程。在平时,这个进程会去缓冲池中寻找脏页将他们写出到磁盘上,然后再将这些page标记为干净的,这样当遇到置换策略需要将其换出时就可以直接drop掉。后面还要考虑到日志、顺序、完整性问题,这些问题的解决都需要考虑到置换策略可能会带来的负影响,这也是数据库系统不想用操作系统mmap的原因,操作系统mmap无法做到。
其他内存池
除了存储 tuples 和 indexes,DBMS 还需要 Memory Pools 来存储其它数据,如:
- Sorting + Join Buffers
- Query Caches
- Maintenance Buffers
- Log Buffers
- Dictionary Caches