八爪鱼下载
八爪鱼采集器号称不用写代码就可以爬取数据,我是在专业课老师的推荐下使用的,特写这篇文章记录下第一次使用八爪鱼工具。
https://www.bazhuayu.com/download/windows
这里我使用最新 8.2.2 版本。体验下八爪鱼。
初次使用八爪鱼需要注册账号,请自行注册。八爪鱼是可以免费使用的。
任务:爬取BOSS直聘有关php职位的招聘信息
爬取上海市php相关招聘:https://www.zhipin.com/job_detail/?query=php&city=101020100&industry=&position=

将需要爬取采集的上述网址粘贴在框中:

八爪鱼会自动开始识别网页:

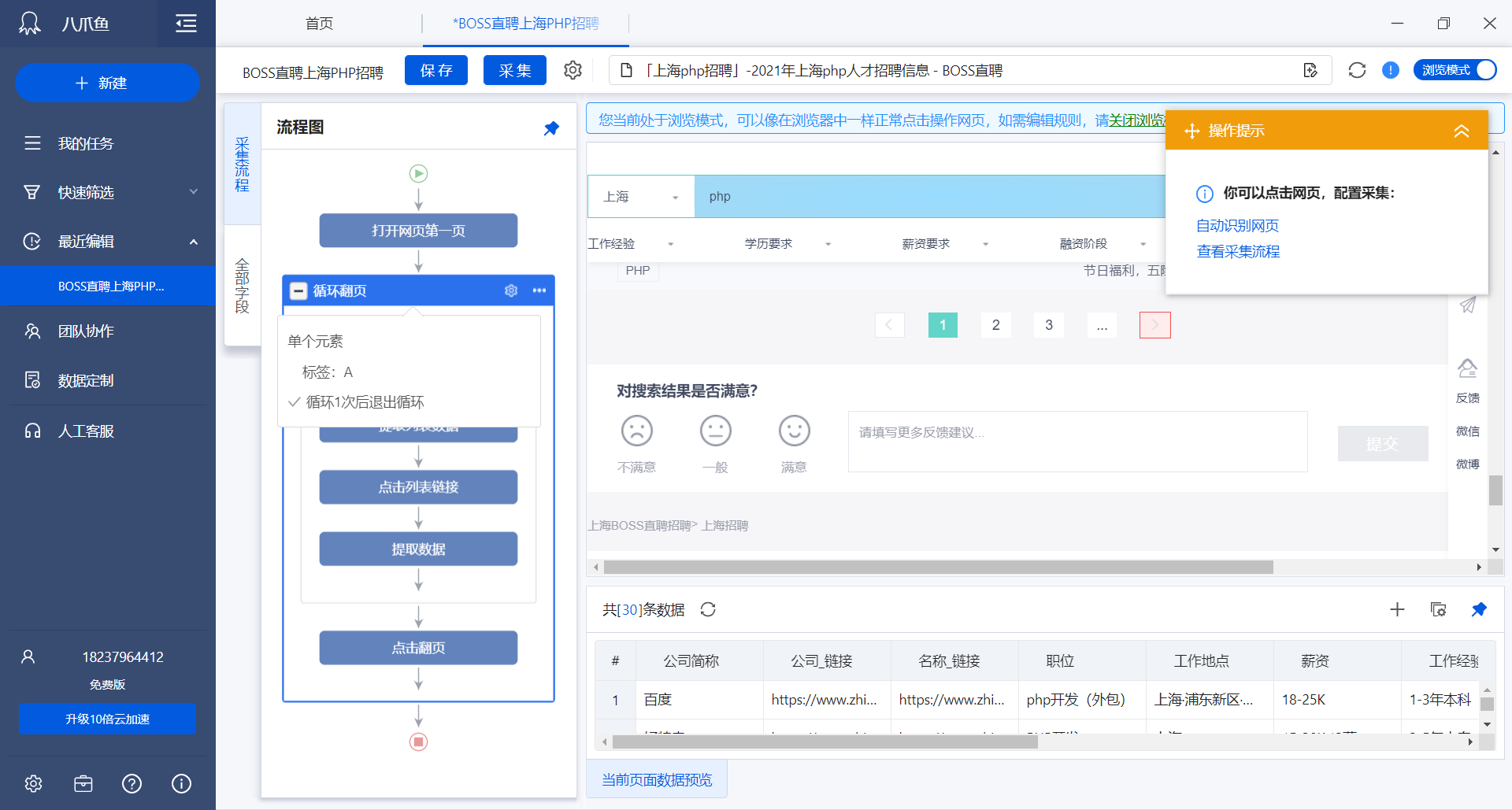
识别完成,列出网页中被识别出的所有字段:
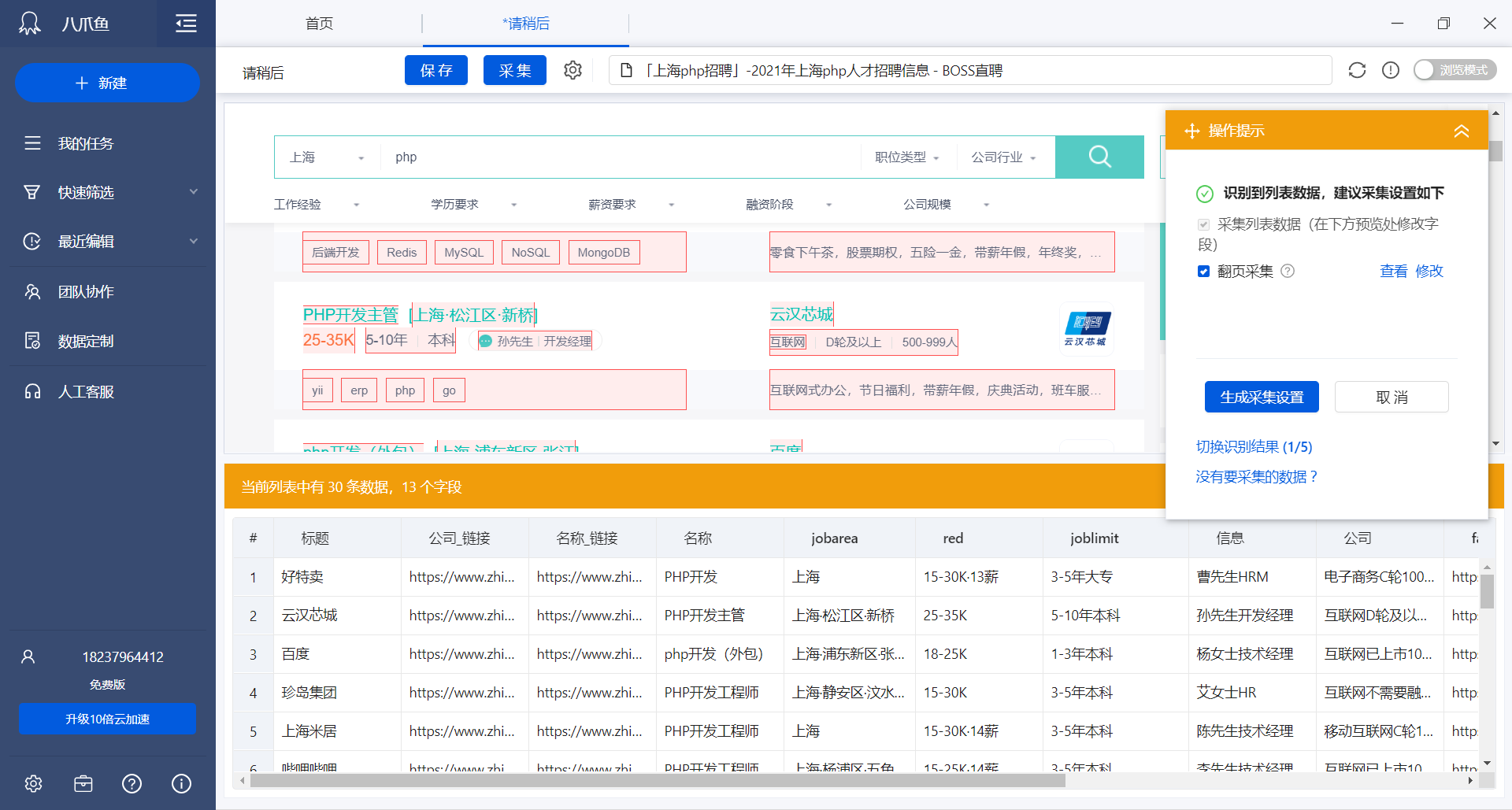

字段设置完成后,下一步是翻页采集,八爪鱼会自动帮助我们完成翻页配置,在爬取网站的时候就不需要我们自己考虑如何自动翻页的问题了。
招聘每一页的列表只显示基本摘要信息,有关于职位详情我们还需要点进详情才能看到,这里用到采集下一级网页数据:
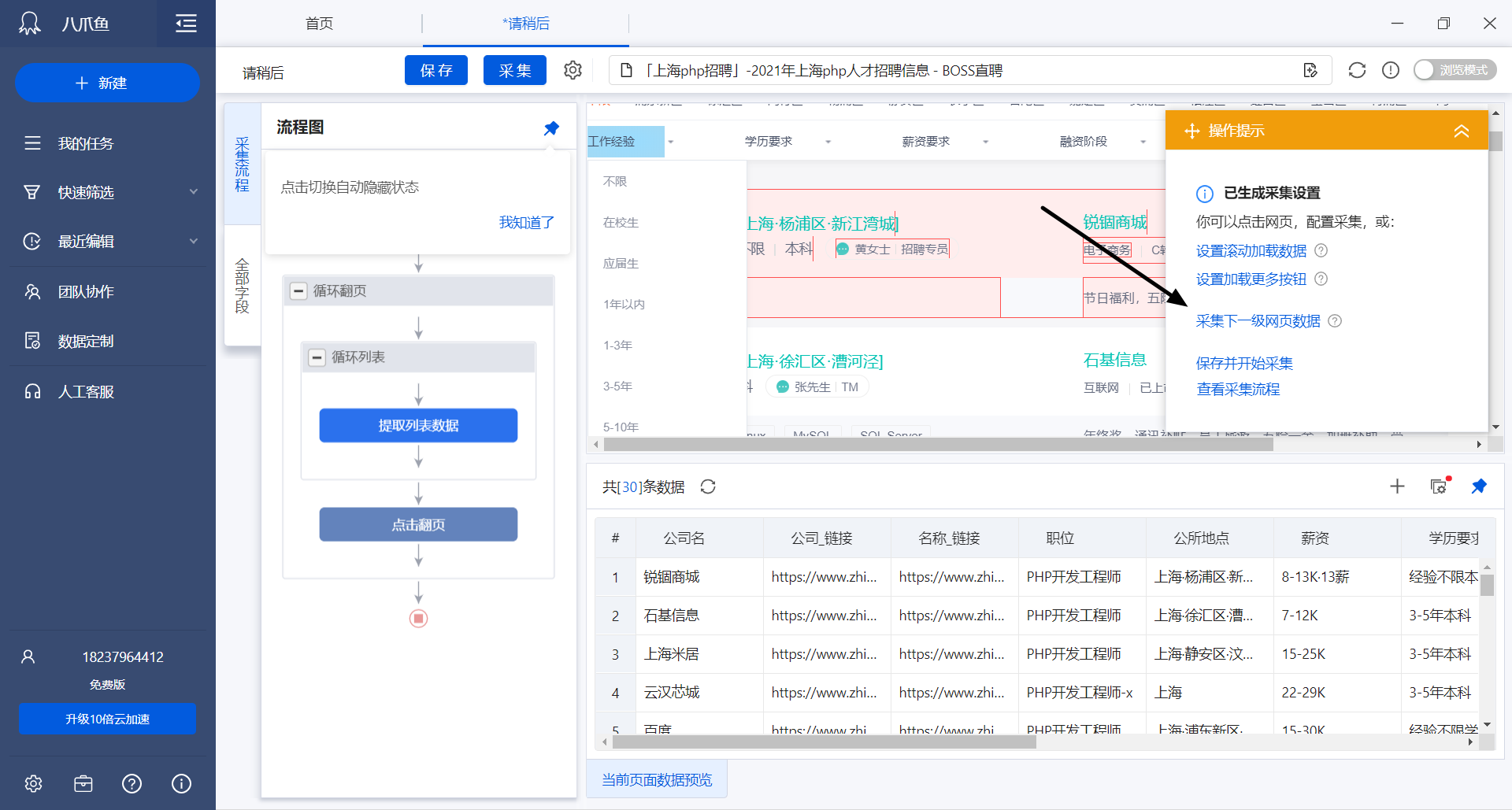
同样的我们配置内页采集字段:

现在基本配置已经完成,可以顺利开始采集了。


点击采集,启动任务,由于我们用的八爪鱼账号是免费的,没有下面的云采集功能,只能使用上面的本地采集:

点击“全部字段”可查看本次任务最终获得的全部字段:

遇到的问题——IP异常访问被拦截
由于BOSS直聘本身的反爬虫技术,由于我们短时间大量爬取网站数据被网站反爬技术拦截,IP被封锁。

手动输入验证码可以继续爬取。
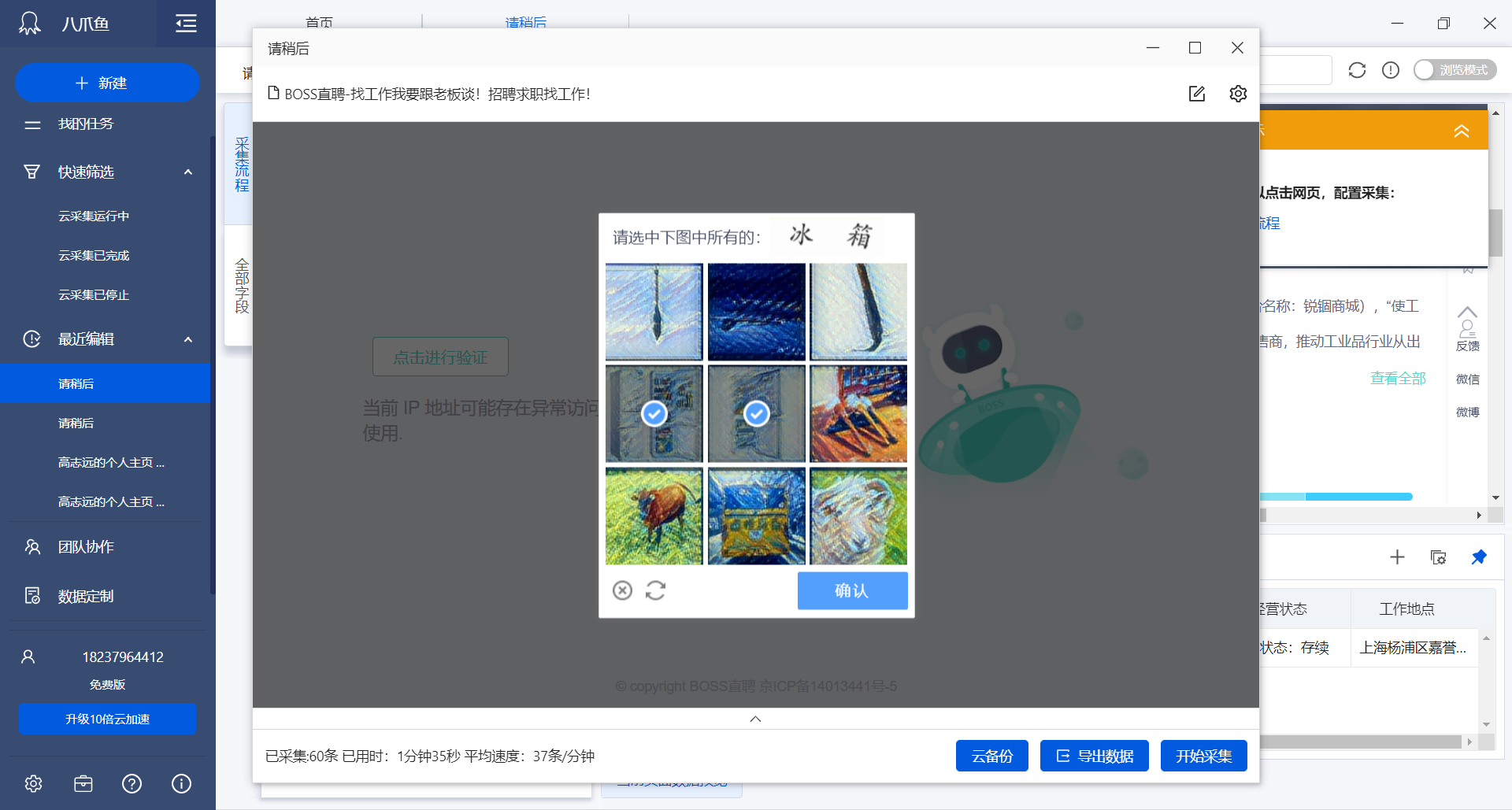
但是在输入验证码后会跳转到第一页而不是我们终止的位置。爬虫也会从第一页开始爬取,显然不符合我们的要求。
解决方法——使用代理IP,控制爬取数据个数
我们可以使用代理IP的方式,这里我使用clash软件配合国外节点将本地数据包全部代理出去,以避免BOSS直聘封锁IP。
一个高质量、高可用、高数量的代理IP池是爬虫技术的核心本领。
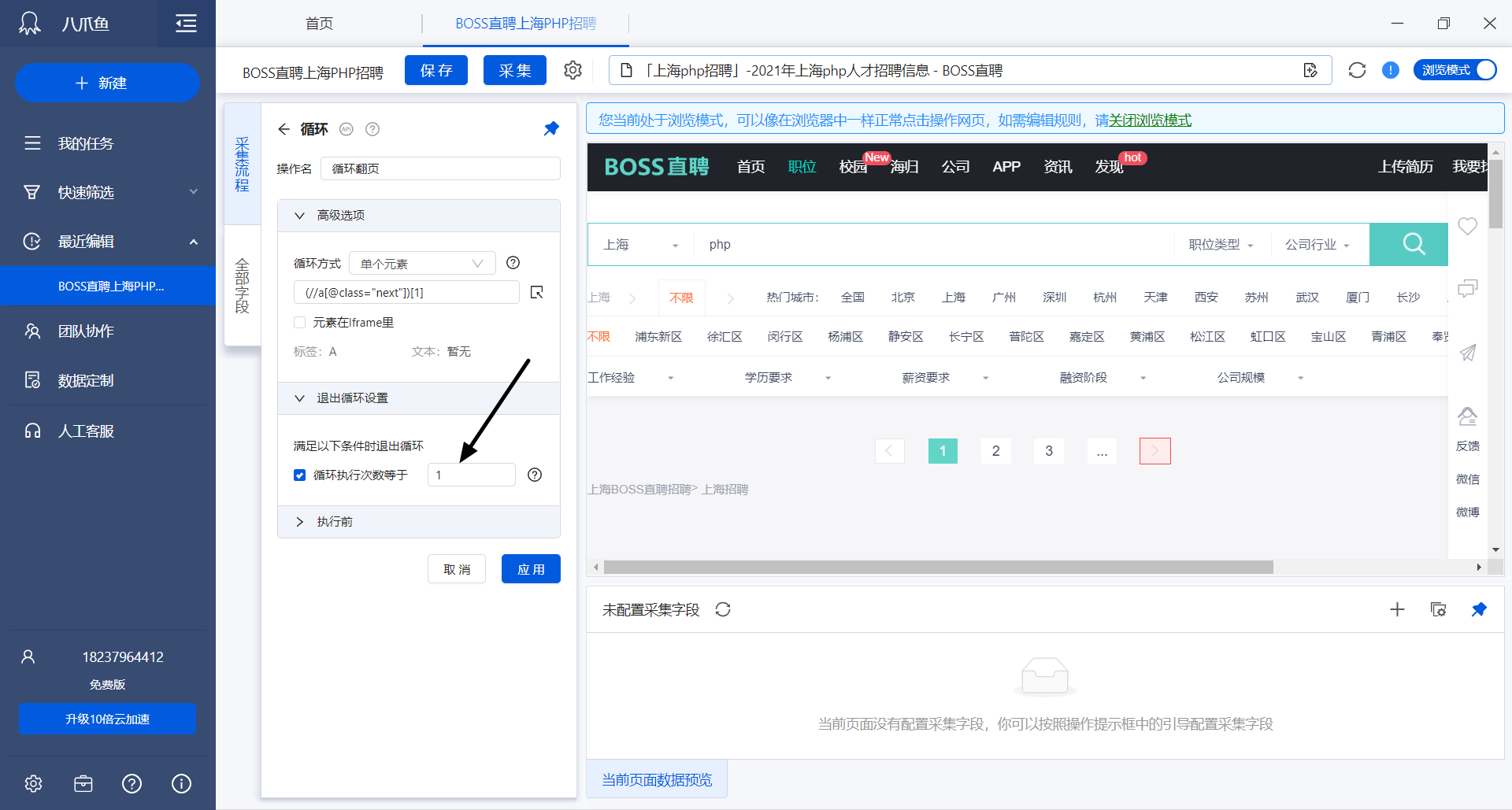
控制每个IP爬取数据个数
经过我们的测试,爬取BOSS直聘通常一个IP最多获取40多条数据就会触发IP封锁。所以这里我们将八爪鱼每次爬取设定为1页——即30条数据。爬取30条数据后就终止本次爬取。

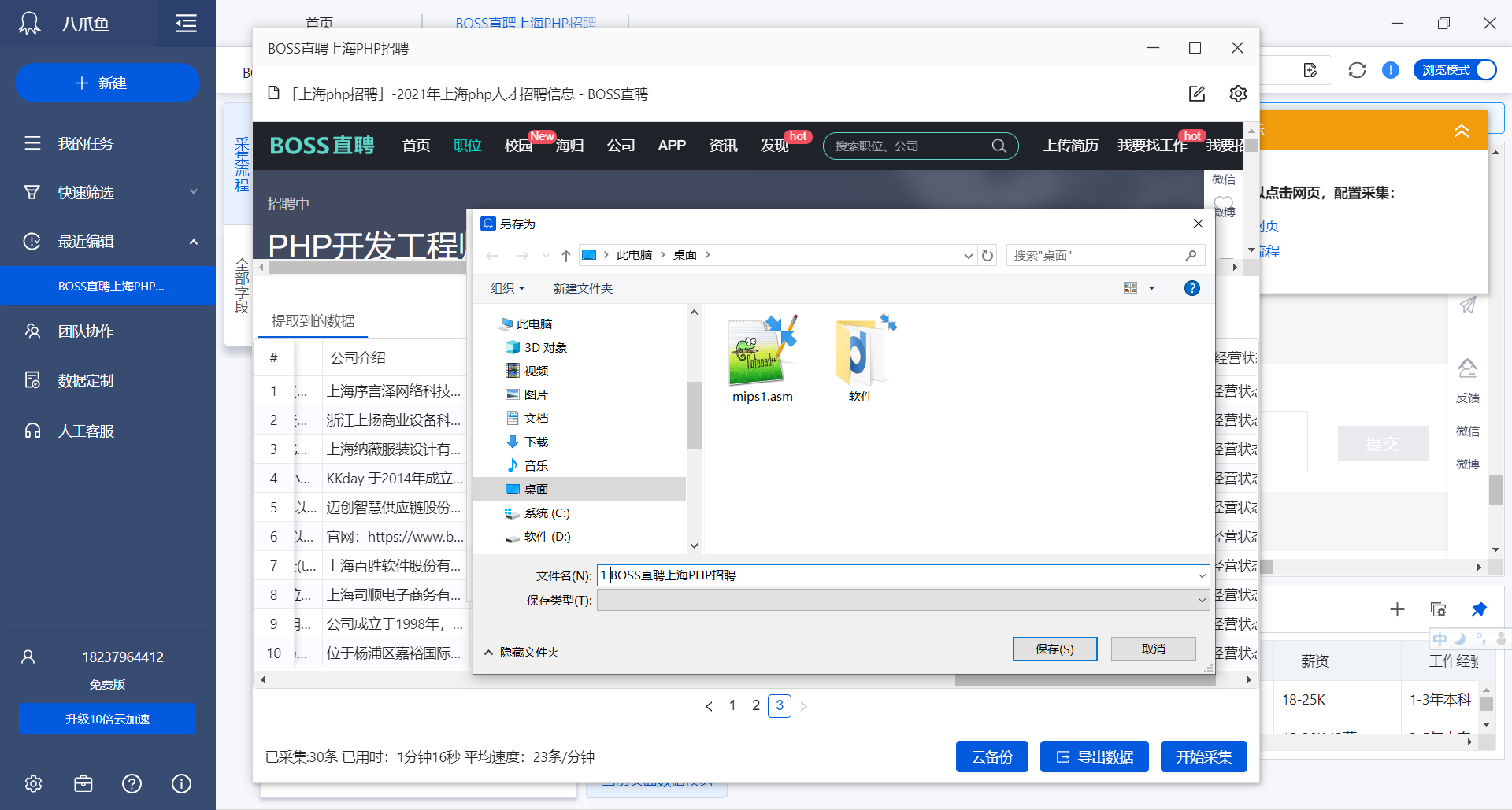
保存第一页数据,保存在excel格式:

切换IP,规避封锁
爬取30条数据后使用clash切换节点达到切换IP的目的。规避封锁。记得将clash调整为 Global全局代理。

切换IP后,继续爬取第2页、第3页 … 数据

最终获得前8页所有有关php招聘的数据:

数据合并——将若干个xlsx文件合并
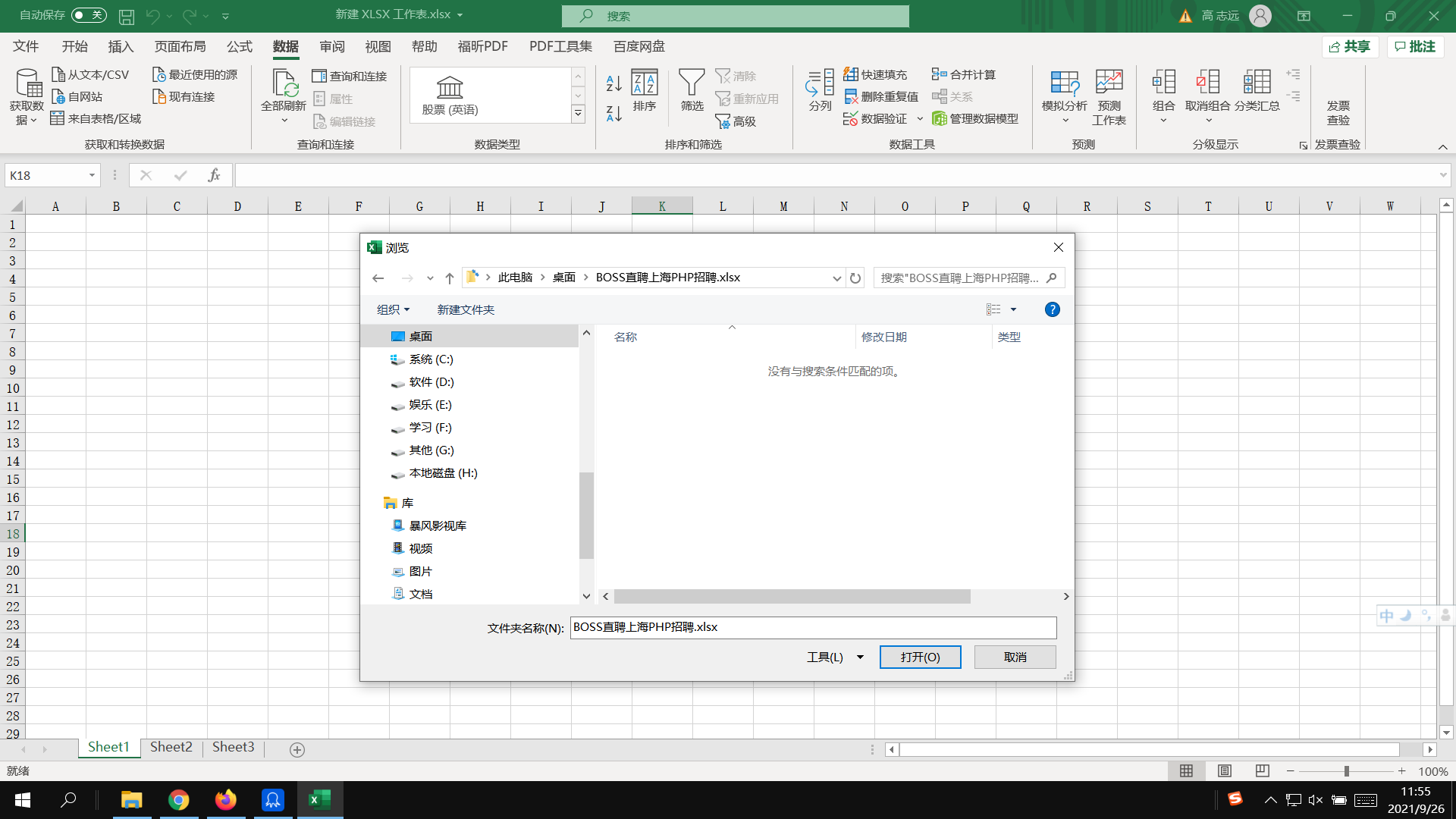
在桌面新建一个excel文件,打开它,选择“数据”-“获取数据”-“来自文件”-“从文件夹”:
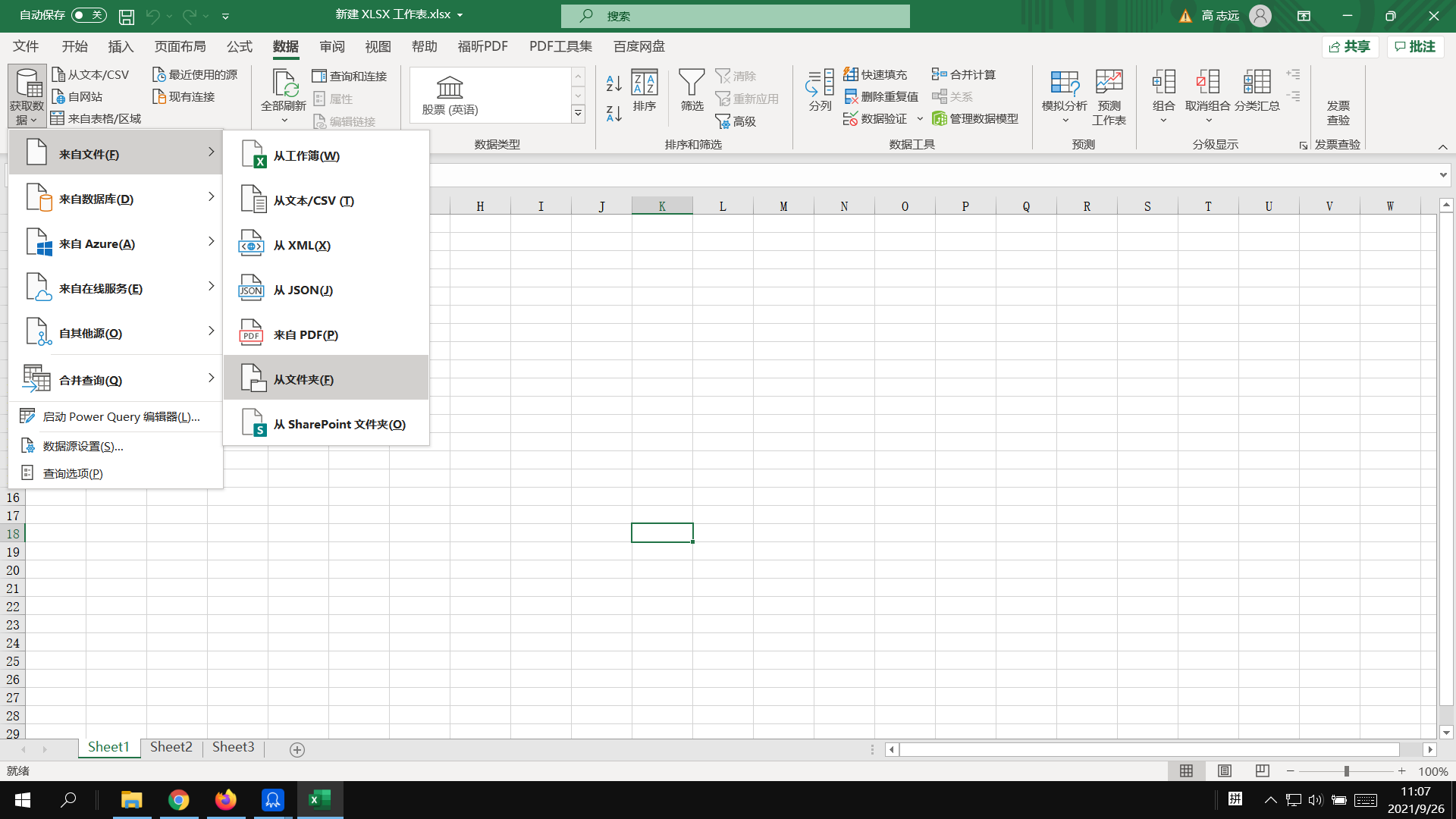
选中文件夹:
点击“转换数据”:

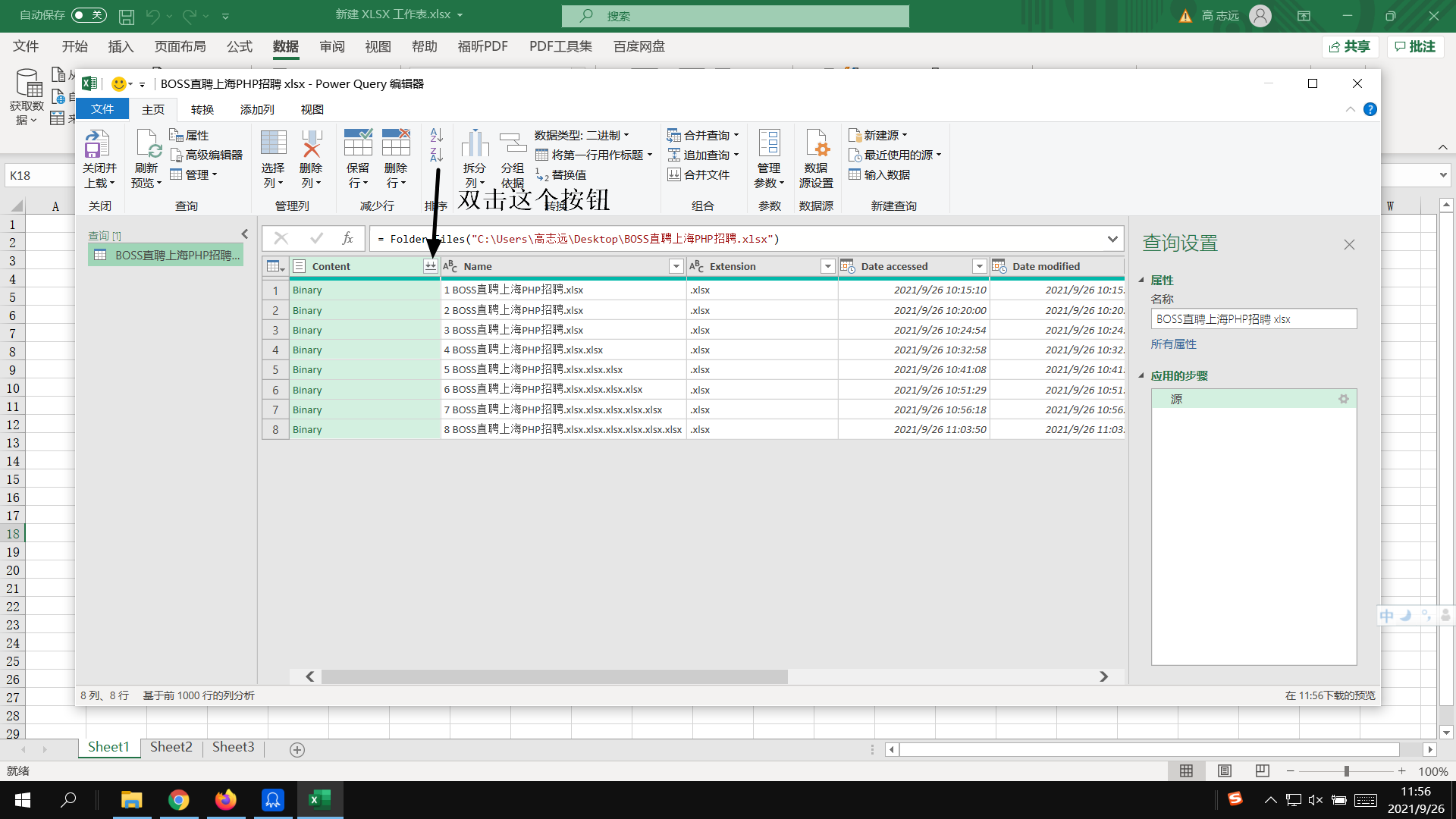

右边框起来的就是我们合并后的数据:

检查合并没有问题后点击“关闭并上载”。
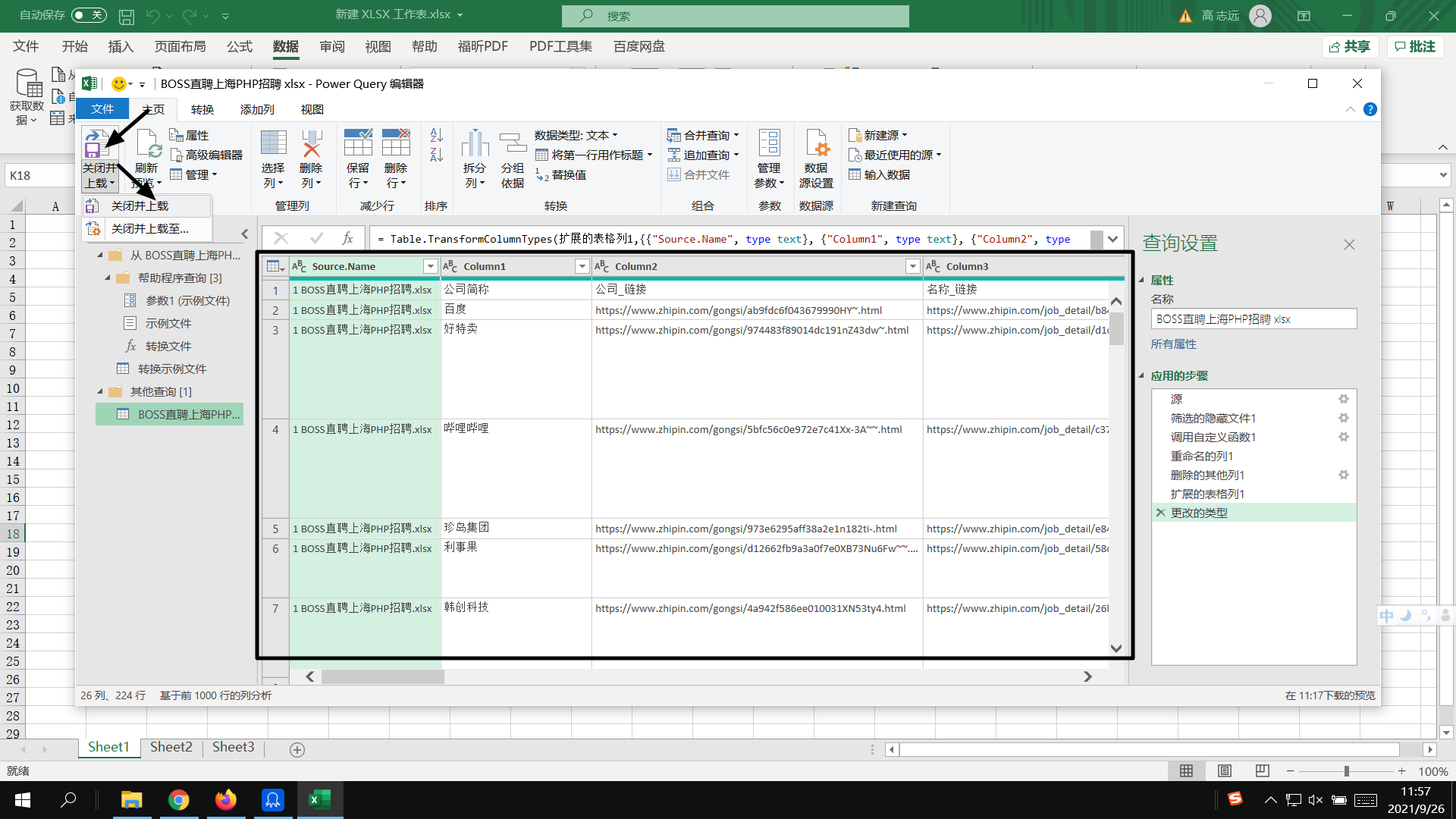
生成合并后的数据,简单的对其进行删除列,调整列宽即可得到最后的成品:
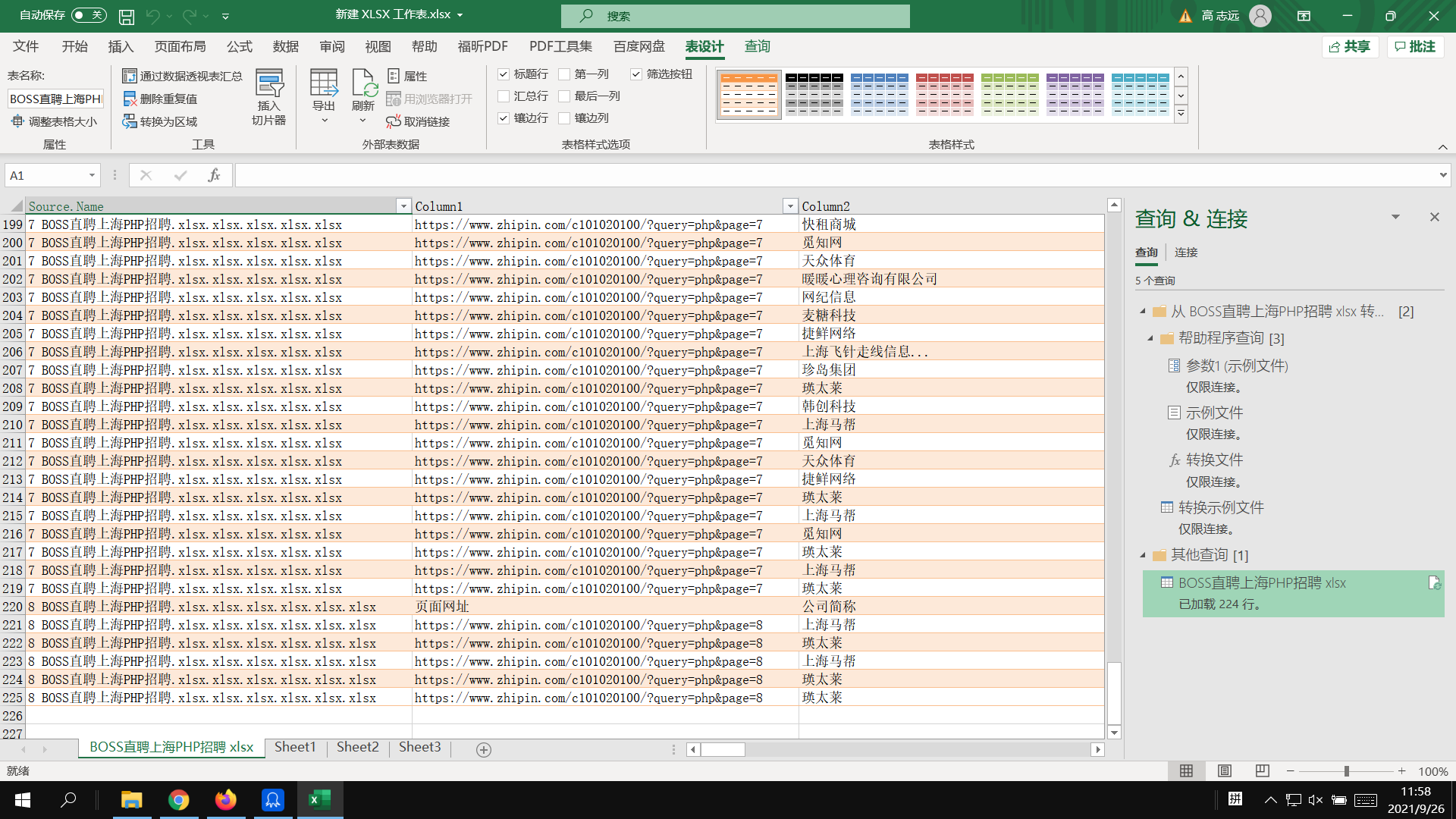
我们共采集到了216条数据。
数据下载
爬取到的8页有关上海php招聘的数据以及合并后的excel文件提供下载,需要的朋友自取,可用作后续的数据分析等领域: