项目简介
爬取中国天气网的天气信息:http://www.weather.com.cn/textFC/hb.shtml
其中,中国天气网将全国分为华北、东北、华东、华中、华南、西北、西南和港澳台八个大区。网址分别如下:
http://www.weather.com.cn/textFC/hb.shtml
http://www.weather.com.cn/textFC/db.shtml
http://www.weather.com.cn/textFC/hd.shtml
http://www.weather.com.cn/textFC/hz.shtml
http://www.weather.com.cn/textFC/hn.shtml
http://www.weather.com.cn/textFC/xb.shtml
http://www.weather.com.cn/textFC/xn.shtml
http://www.weather.com.cn/textFC/gat.shtml
我们需要获取各个城市的天气基本信息。
项目思路
首先我们发现每个大区的地址是很有规律的,并且很少,我们不需要通过爬虫获取(像以前获取分页那样),只需要把他们放入数组中,用函数获取即可。
省份table分析
然后分析其中一个大区,我们以华北为例,发现每个省份都是单独的一个table表格:

普通的tr:第4个以后的tr
其中,分析每个省份table的函数如下:
# 分析每个省份table
def beautiful(res):
soup = BeautifulSoup(res.content, 'html.parser')
print(soup)
tr = soup.find('table', width="100%").find_all('tr') # .find定位到所需数据位置 .find_all查找所有的tr(表格)
province = '北京'
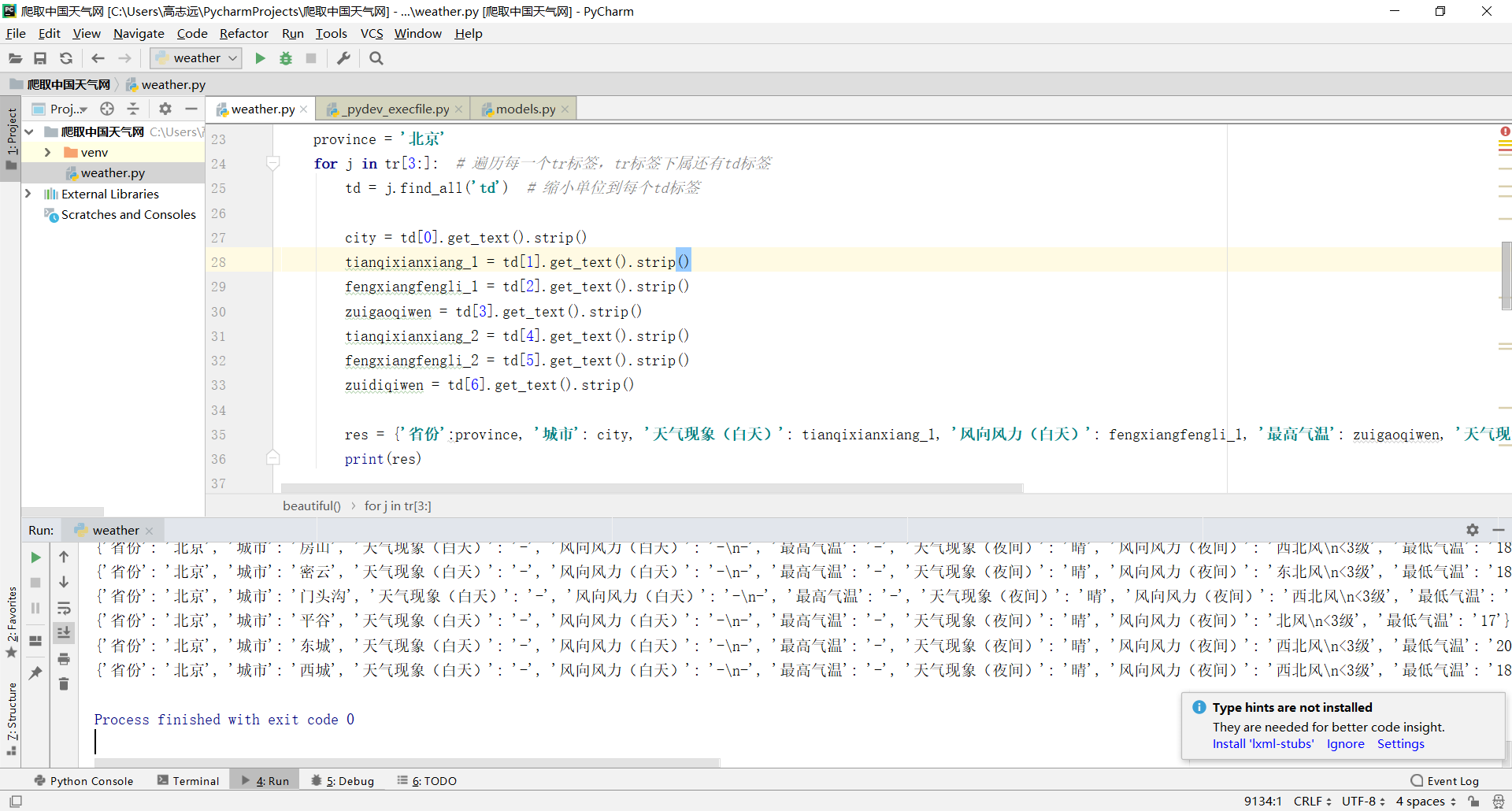
for j in tr[3:]: # 遍历每一个tr标签,tr标签下属还有td标签
td = j.find_all('td') # 缩小单位到每个td标签
city = td[0].get_text().strip()
tianqixianxiang_1 = td[1].get_text().strip()
fengxiangfengli_1 = td[2].get_text().strip()
zuigaoqiwen = td[3].get_text().strip()
tianqixianxiang_2 = td[4].get_text().strip()
fengxiangfengli_2 = td[5].get_text().strip()
zuidiqiwen = td[6].get_text().strip()
res = {'省份':province, '城市': city, '天气现象(白天)': tianqixianxiang_1, '风向风力(白天)': fengxiangfengli_1, '最高气温': zuigaoqiwen, '天气现象(夜间)': tianqixianxiang_2, '风向风力(夜间)': fengxiangfengli_2, '最低气温': zuidiqiwen}
print(res)
视频讲解
特殊的tr(第1、2、3个tr)
# 分析每个省份table
def beautiful(res):
soup = BeautifulSoup(res.content, 'html.parser')
print(soup)
tr = soup.find('table', width="100%").find_all('tr') # .find定位到所需数据位置 .find_all查找所有的tr(表格)
province = '北京'
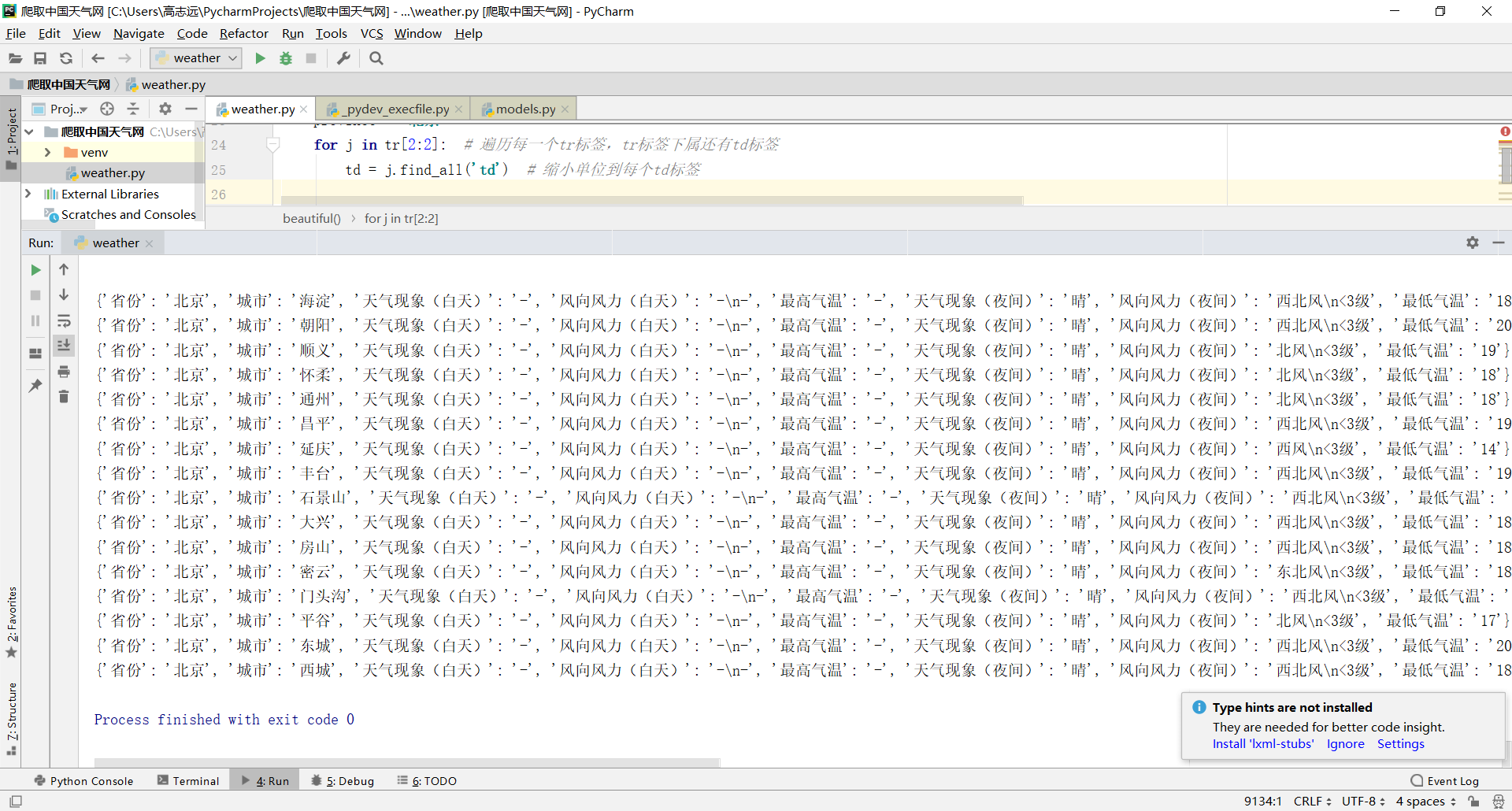
for j in tr[2:2]: # 遍历每一个tr标签,tr标签下属还有td标签
td = j.find_all('td') # 缩小单位到每个td标签
city = td[1].get_text().strip()
tianqixianxiang_1 = td[2].get_text().strip()
fengxiangfengli_1 = td[3].get_text().strip()
zuigaoqiwen = td[4].get_text().strip()
tianqixianxiang_2 = td[5].get_text().strip()
fengxiangfengli_2 = td[6].get_text().strip()
zuidiqiwen = td[7].get_text().strip()
res = {'省份':province, '城市': city, '天气现象(白天)': tianqixianxiang_1, '风向风力(白天)': fengxiangfengli_1, '最高气温': zuigaoqiwen, '天气现象(夜间)': tianqixianxiang_2, '风向风力(夜间)': fengxiangfengli_2, '最低气温': zuidiqiwen}
print(res)
for j in tr[3:]: # 遍历每一个tr标签,tr标签下属还有td标签
td = j.find_all('td') # 缩小单位到每个td标签
city = td[0].get_text().strip()
tianqixianxiang_1 = td[1].get_text().strip()
fengxiangfengli_1 = td[2].get_text().strip()
zuigaoqiwen = td[3].get_text().strip()
tianqixianxiang_2 = td[4].get_text().strip()
fengxiangfengli_2 = td[5].get_text().strip()
zuidiqiwen = td[6].get_text().strip()
res = {'省份':province, '城市': city, '天气现象(白天)': tianqixianxiang_1, '风向风力(白天)': fengxiangfengli_1, '最高气温': zuigaoqiwen, '天气现象(夜间)': tianqixianxiang_2, '风向风力(夜间)': fengxiangfengli_2, '最低气温': zuidiqiwen}
print(res)
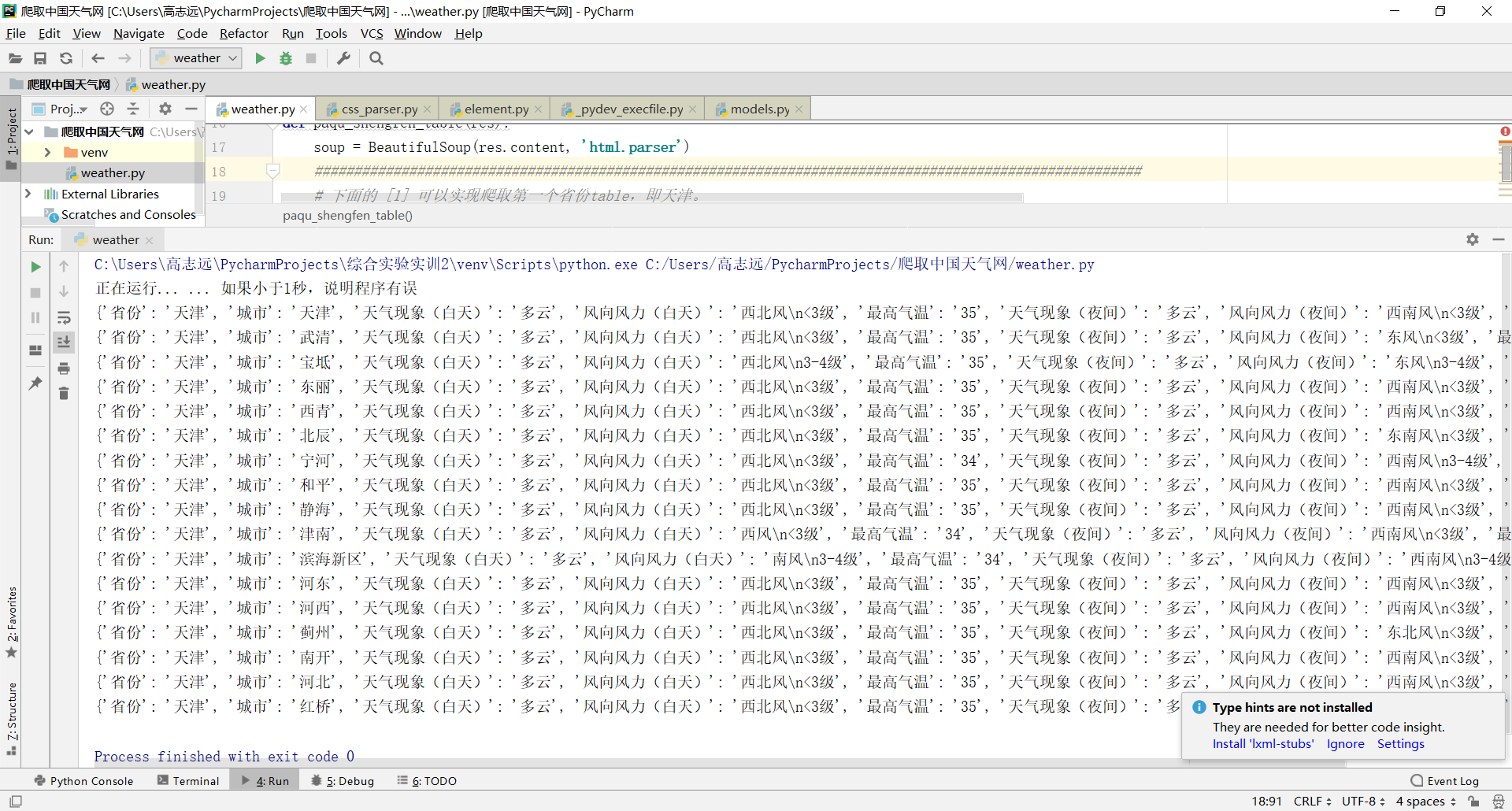
现在第一个省份的爬取已经完成,我们改造一下,新建一个函数 paqu_shengfen_table:
实现爬取大区下的任意省份城市天气
代码
下面的代码已经可以实现爬取任意省份的天气情况:
import re
import time
from lxml import etree
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'Cookie': ''
}
# 在商品内页中操作
def detail(detail_url, option):
url = detail_url
res = requests.get(url, headers = headers)
paqu_shengfen_table(res)
def paqu_shengfen_table(res):
soup = BeautifulSoup(res.content, 'html.parser')
#########################################################################################################
# 下面的 [1] 可以实现爬取第一个省份table,即天津。
# 如果设置为 [0],则是爬取北京table。
# 如果设置为 [2],则是爬取河北table
tr_all = soup.select('.conMidtab2 > table')[1] # .find定位到所需数据位置 .find_all查找所有的tr(表格)
#########################################################################################################
tr = tr_all.find_all('tr')
shengfen = (tr[2].get_text().split())[0]
# print(shengfen)
beautiful(res, tr, shengfen)
# 分析每个省份table
def beautiful(res, tr, shengfen):
td = tr[2].find_all('td') # 缩小单位到每个td标签
city = td[1].get_text().strip()
tianqixianxiang_1 = td[2].get_text().strip()
fengxiangfengli_1 = td[3].get_text().strip()
zuigaoqiwen = td[4].get_text().strip()
tianqixianxiang_2 = td[5].get_text().strip()
fengxiangfengli_2 = td[6].get_text().strip()
zuidiqiwen = td[7].get_text().strip()
res = {'省份':shengfen, '城市': city, '天气现象(白天)': tianqixianxiang_1, '风向风力(白天)': fengxiangfengli_1, '最高气温': zuigaoqiwen, '天气现象(夜间)': tianqixianxiang_2, '风向风力(夜间)': fengxiangfengli_2, '最低气温': zuidiqiwen}
print(res)
# 便利普通的tr
for j in tr[3:]: # 遍历每一个tr标签,tr标签下属还有td标签
td = j.find_all('td') # 缩小单位到每个td标签
city = td[0].get_text().strip()
tianqixianxiang_1 = td[1].get_text().strip()
fengxiangfengli_1 = td[2].get_text().strip()
zuigaoqiwen = td[3].get_text().strip()
tianqixianxiang_2 = td[4].get_text().strip()
fengxiangfengli_2 = td[5].get_text().strip()
zuidiqiwen = td[6].get_text().strip()
res = {'省份':shengfen, '城市': city, '天气现象(白天)': tianqixianxiang_1, '风向风力(白天)': fengxiangfengli_1, '最高气温': zuigaoqiwen, '天气现象(夜间)': tianqixianxiang_2, '风向风力(夜间)': fengxiangfengli_2, '最低气温': zuidiqiwen}
print(res)
def get_datail_url(url, option):
detail(url, option)
def start(option):
# base_url = 'https://www.guazi.com/zz/honda/o{}/'
# urls = []
# for x in range(1, 3):
# urls.append(base_url.format(x))
# 对网页进行翻页
url = 'http://www.weather.com.cn/textFC/hb.shtml'
get_datail_url(url, option)
if __name__ == '__main__':
print("正在运行... ... 如果小于1秒,说明程序有误")
start(1)
实现爬取一个大区下的所有省份,所有城市天气
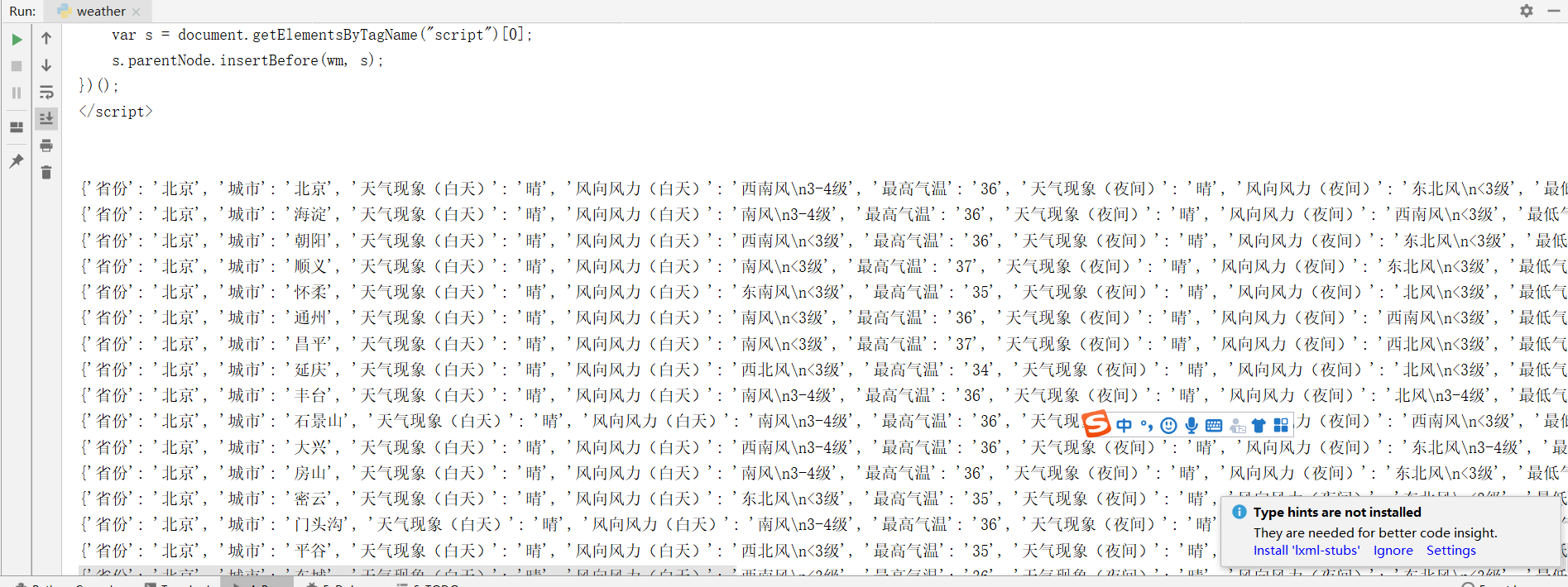

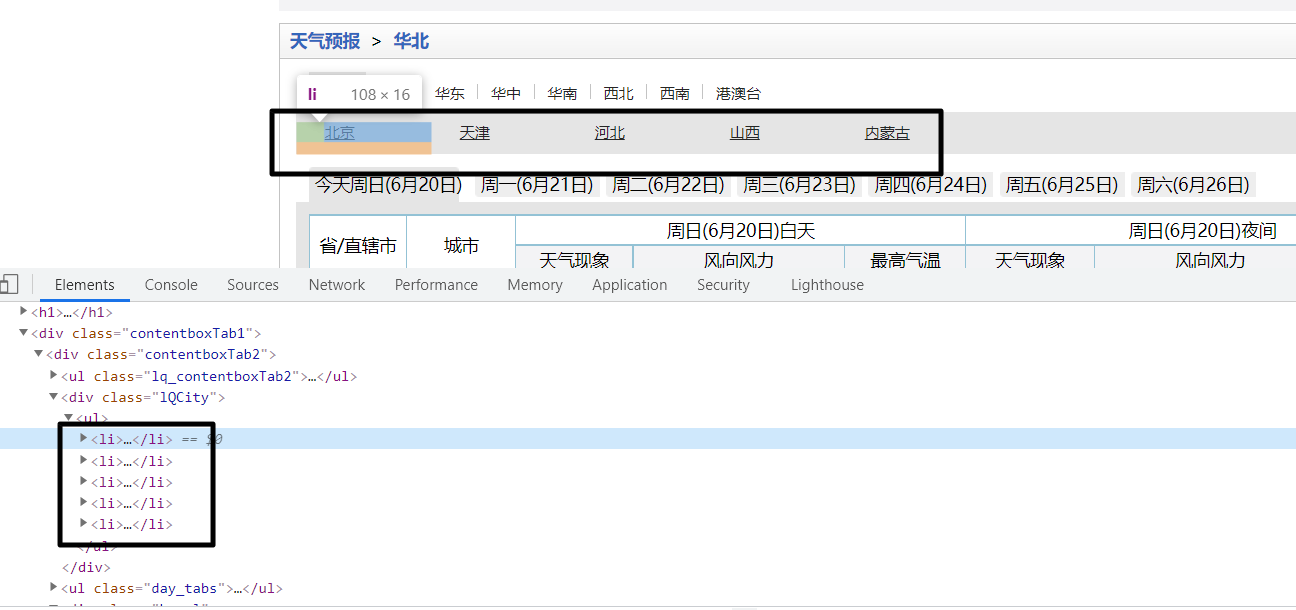
基本思路是获取一个大区下有多少省份,使用:
table_nums = soup.select('.lQCity > ul > li').__len__()
table_nums的值为5。
即通过获取ul下有多少个li标签,然后取出个数得到。
代码
代码如下:
import re
import time
from lxml import etree
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'Cookie': ''
}
# 在商品内页中操作
def detail(detail_url, option):
url = detail_url
res = requests.get(url, headers = headers)
paqu_shengfen_table(res)
def paqu_shengfen_table(res):
soup = BeautifulSoup(res.content, 'html.parser')
# 获取一个大区中有多少省份
print(soup)
table_nums = soup.select('.lQCity > ul > li').__len__()
for i in range(table_nums):
# 爬取每个省份table
#########################################################################################################
# 下面的 [1] 可以实现爬取第一个省份table,即天津。
# 如果设置为 [0],则是爬取北京table。
# 如果设置为 [2],则是爬取河北table
tr_all = soup.select('.conMidtab2 > table')[i] # .find定位到所需数据位置 .find_all查找所有的tr(表格)
#########################################################################################################
tr = tr_all.find_all('tr')
shengfen = (tr[2].get_text().split())[0]
# print(shengfen)
beautiful(res, tr, shengfen)
# 分析每个省份table
def beautiful(res, tr, shengfen):
td = tr[2].find_all('td') # 缩小单位到每个td标签
city = td[1].get_text().strip()
tianqixianxiang_1 = td[2].get_text().strip()
fengxiangfengli_1 = td[3].get_text().strip()
zuigaoqiwen = td[4].get_text().strip()
tianqixianxiang_2 = td[5].get_text().strip()
fengxiangfengli_2 = td[6].get_text().strip()
zuidiqiwen = td[7].get_text().strip()
res = {'省份':shengfen, '城市': city, '天气现象(白天)': tianqixianxiang_1, '风向风力(白天)': fengxiangfengli_1, '最高气温': zuigaoqiwen, '天气现象(夜间)': tianqixianxiang_2, '风向风力(夜间)': fengxiangfengli_2, '最低气温': zuidiqiwen}
print(res)
# 便利普通的tr
for j in tr[3:]: # 遍历每一个tr标签,tr标签下属还有td标签
td = j.find_all('td') # 缩小单位到每个td标签
city = td[0].get_text().strip()
tianqixianxiang_1 = td[1].get_text().strip()
fengxiangfengli_1 = td[2].get_text().strip()
zuigaoqiwen = td[3].get_text().strip()
tianqixianxiang_2 = td[4].get_text().strip()
fengxiangfengli_2 = td[5].get_text().strip()
zuidiqiwen = td[6].get_text().strip()
res = {'省份':shengfen, '城市': city, '天气现象(白天)': tianqixianxiang_1, '风向风力(白天)': fengxiangfengli_1, '最高气温': zuigaoqiwen, '天气现象(夜间)': tianqixianxiang_2, '风向风力(夜间)': fengxiangfengli_2, '最低气温': zuidiqiwen}
print(res)
def get_datail_url(url, option):
detail(url, option)
def start(option):
# base_url = 'https://www.guazi.com/zz/honda/o{}/'
# urls = []
# for x in range(1, 3):
# urls.append(base_url.format(x))
# 对网页进行翻页
url = 'http://www.weather.com.cn/textFC/hb.shtml'
get_datail_url(url, option)
if __name__ == '__main__':
print("正在运行... ... 如果小于1秒,说明程序有误")
start(1)
实现爬取除港澳台外所有城市天气
下面我们只需要把所有的大区url写在数组中,分别去调用 get_datail_url 函数即可。
因为 港澳台大区的table表格与前面的都不相同,http://www.weather.com.cn/textFC/gat.shtml
所以我们暂时剔除掉港澳台大区的天气爬取。随后有时间我会完善这只爬虫。
代码
import re
import time
from lxml import etree
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'Cookie': ''
}
# 在商品内页中操作
def detail(detail_url, option):
url = detail_url
res = requests.get(url, headers = headers)
paqu_shengfen_table(res)
def paqu_shengfen_table(res):
soup = BeautifulSoup(res.content, 'html.parser')
# 获取一个大区中有多少省份
table_nums = soup.select('.lQCity > ul > li').__len__()
for i in range(table_nums):
# 爬取每个省份table
#########################################################################################################
# 下面的 [1] 可以实现爬取第一个省份table,即天津。
# 如果设置为 [0],则是爬取北京table。
# 如果设置为 [2],则是爬取河北table
tr_all = soup.select('.conMidtab2 > table')[i] # .find定位到所需数据位置 .find_all查找所有的tr(表格)
#########################################################################################################
tr = tr_all.find_all('tr')
shengfen = (tr[2].get_text().split())[0]
# print(shengfen)
beautiful(res, tr, shengfen)
# 分析每个省份table
def beautiful(res, tr, shengfen):
td = tr[2].find_all('td') # 缩小单位到每个td标签
city = td[1].get_text().strip()
tianqixianxiang_1 = td[2].get_text().strip()
fengxiangfengli_1 = td[3].get_text().strip()
zuigaoqiwen = td[4].get_text().strip()
tianqixianxiang_2 = td[5].get_text().strip()
fengxiangfengli_2 = td[6].get_text().strip()
zuidiqiwen = td[7].get_text().strip()
res = {'省份':shengfen, '城市': city, '天气现象(白天)': tianqixianxiang_1, '风向风力(白天)': fengxiangfengli_1, '最高气温': zuigaoqiwen, '天气现象(夜间)': tianqixianxiang_2, '风向风力(夜间)': fengxiangfengli_2, '最低气温': zuidiqiwen}
print(res)
# 便利普通的tr
for j in tr[3:]: # 遍历每一个tr标签,tr标签下属还有td标签
td = j.find_all('td') # 缩小单位到每个td标签
city = td[0].get_text().strip()
tianqixianxiang_1 = td[1].get_text().strip()
fengxiangfengli_1 = td[2].get_text().strip()
zuigaoqiwen = td[3].get_text().strip()
tianqixianxiang_2 = td[4].get_text().strip()
fengxiangfengli_2 = td[5].get_text().strip()
zuidiqiwen = td[6].get_text().strip()
res = {'省份':shengfen, '城市': city, '天气现象(白天)': tianqixianxiang_1, '风向风力(白天)': fengxiangfengli_1, '最高气温': zuigaoqiwen, '天气现象(夜间)': tianqixianxiang_2, '风向风力(夜间)': fengxiangfengli_2, '最低气温': zuidiqiwen}
print(res)
def get_datail_url(url, option):
detail(url, option)
def start(option):
urls = ['http://www.weather.com.cn/textFC/hb.shtml',
'http://www.weather.com.cn/textFC/db.shtml',
'http://www.weather.com.cn/textFC/hd.shtml',
'http://www.weather.com.cn/textFC/hz.shtml',
'http://www.weather.com.cn/textFC/hn.shtml',
'http://www.weather.com.cn/textFC/xb.shtml',
'http://www.weather.com.cn/textFC/xn.shtml',
'http://www.weather.com.cn/textFC/gat.shtml' # 港澳台的table跟前面的都不太一样,我们先将其去除。
]
for i in range(0, 7):
get_datail_url(urls[i], option)
if __name__ == '__main__':
print("正在运行... ... 如果小于1秒,说明程序有误")
start(1)

参考文献:https://blog.csdn.net/python918/article/details/105030833