本文已收录到:中科大编译原理学习笔记 专题
简述
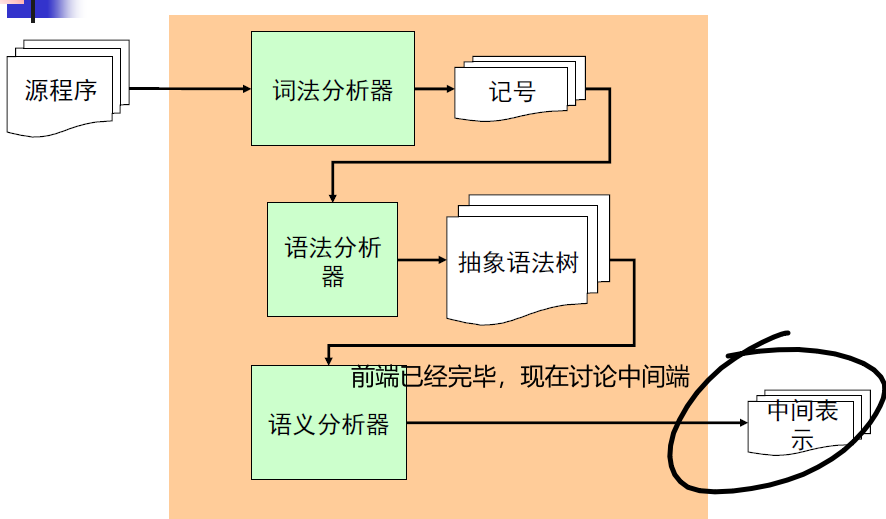
有时候直接直接翻译成汇编指令较为困难,认为的拆成几个单独的步骤和模块。

如果简化下中间只翻译一次就得到汇编指令,这种简化后的可以直接叫代码生成器。
代码生成的任务
真实物理机器也可,java虚拟机也可。

代码的等价性非常重要,源程序想输出4,编译器处理后的汇编代码不能是输出5。当然,现在像gcc编译器也有一些bug,会将代码翻译错。
分配计算资源

答:变量可以放在内存也可以放在寄存器中,当然放在堆中也是可以的,给变量直接malloc一个空间。但是这样做不太符合变量本身的生命周期,例如函数内部的变量放在堆中就显得不合适的,因为堆中的生命周期是比较长的。一个好的编译器应该尽可能的将变量放置在寄存器中,因为寄存器是高速的。如何将成千上万个变量尽可能的存储在那少的可怜的寄存器中,这是寄存器分配要研究的内容。
选择合适的机器指令

用机器指令实现高层代码,一定要属性指令集体系结构。可以学习下MIPS汇编指令哦 –> MIPS汇编语言学习笔记
代码生成技术

栈式计算机代码生成:很多虚拟机的代码生成技术、JVM等
栈式计算机的缺点是执行效率低,目前已经没有人用在物理机上了。但是目前虚拟机架构还在用,例如JVM、。
栈式计算机的生成代码是所有体系结构中最容易的,使用递归算法。
甚至你学完本节课,可以尝试下编译器生成的代码再JVM上运行哦~~~


Ps:上图中top指针指向的是“顶楼”,而不是“楼顶”,也就是指向顶部已存在的元素,不是那个空位置。这部分可参考下数据结构文章 –> 数据结构算法实现:顺序栈——栈的顺序表示和实现
下面的指令集是以java的字节码举例的:


从内存读到栈顶:
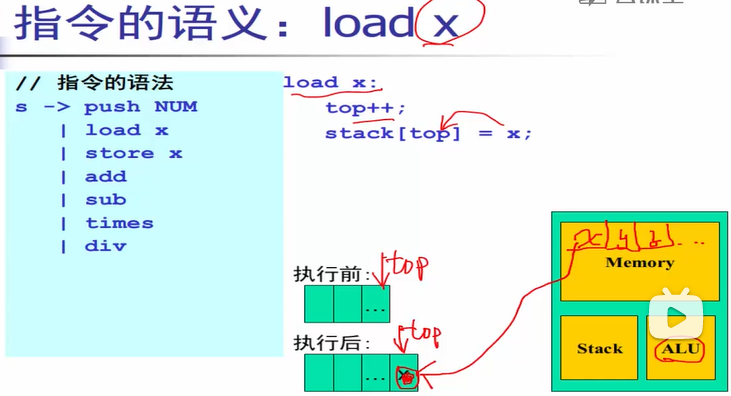
加法指令:在栈内通过top指针进行运算。

在内存中开辟空间:.int x 是一条伪指令,作用是在内存中开辟一块int类型大小的空间(例如C语言中int类型占4字节),存放变量x。

示例:
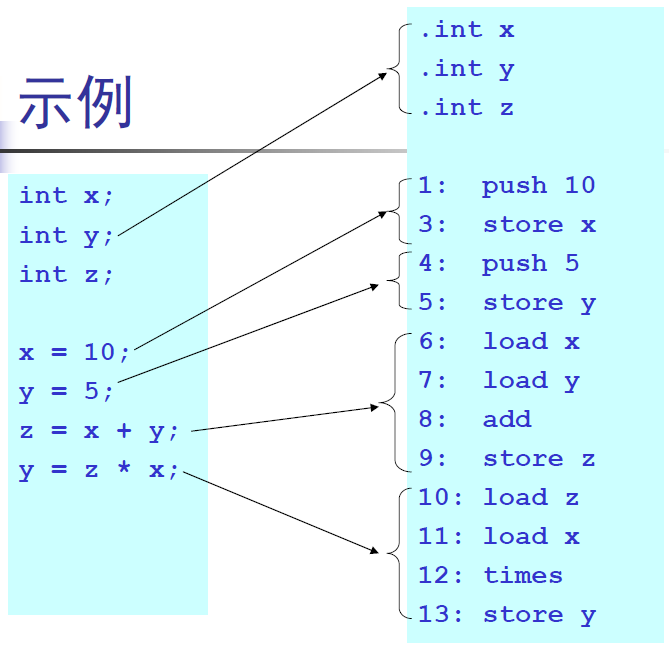
如何运行生成的代码?
有三种方法:
第一种方法可能比较难了,现在很少有栈式计算机了。
第二种方式需要自己动手写虚拟机,这又开辟了一个大坑。hhh。回头有时间可以学学如何自己写JVM。
第三种方法就是用模拟器,在不同的架构上运行另一种汇编。比如MIPS汇编就有Windows下的名叫MARS的模拟期,在Linux上还可以用spim。说到这可以参考下这篇文章 –> MIPS模拟器下载:MARS、SPIM和JsSpim

寄存器计算机代码生成:代表RISC精简指令集,MIPS,ARM等
特点:

eg:
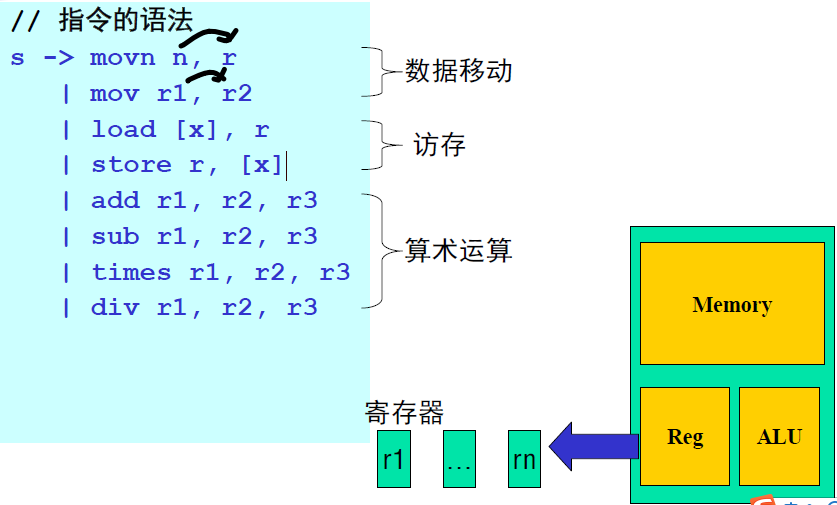
变量的寄存器分配伪指令

划重点:在本阶段(代码生成阶段)假设寄存器是无穷多个的,后面才会讨论寄存器的分配问题。
递归下降代码生成算法
这里我们以C–语言——一种简化版的C语言为例。来讲述递归下降代码生成算法。
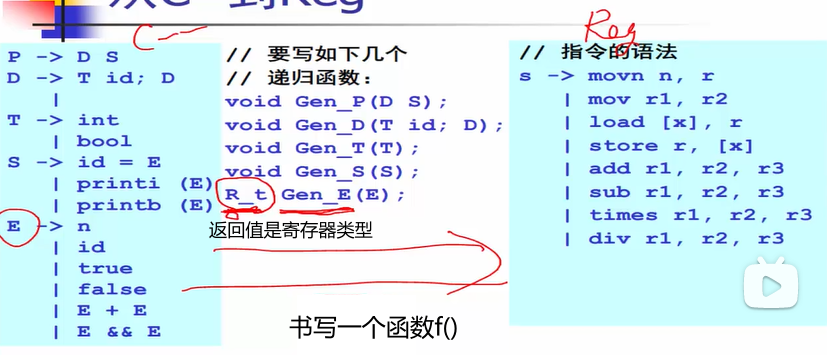
表达式的代码生成
讨论下表达式的赋值:
fresh()函数的内部就是一个 i++ 的操作,在每次调用fresh() 函数时就会有一个独一无二的数值,这个数值代表着独一无二的编译器。

下面来讨论下表达式的运算:

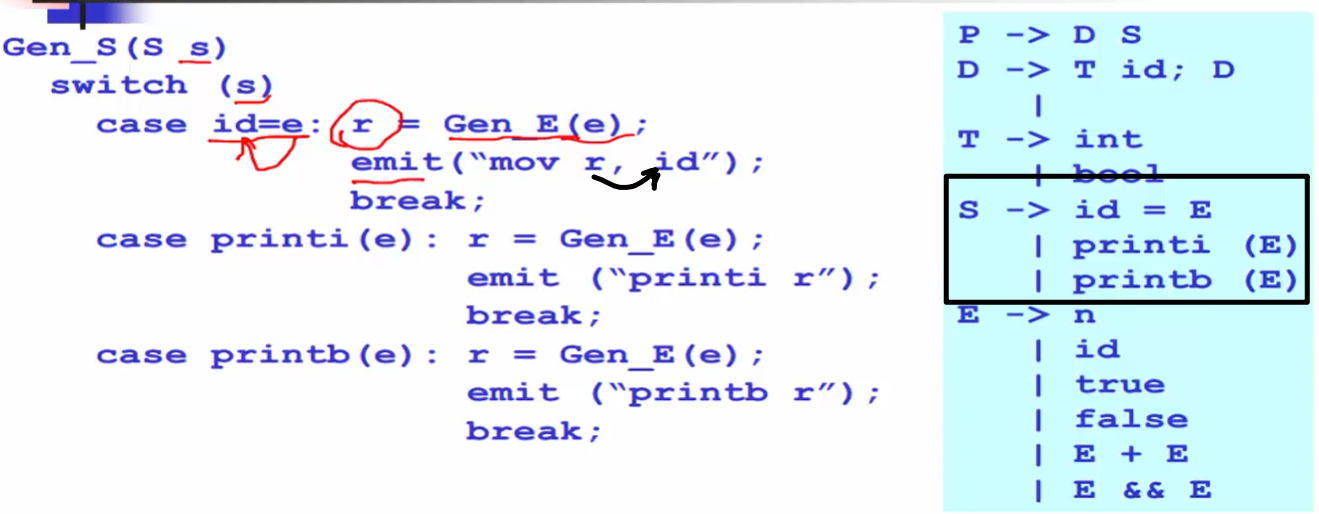
语句的代码生成
类型的代码生成

变量声明的代码生成

程序的代码生成


解释上图:其实这跟抽象语法树的生成很像,因为加法是左结合的,所以抽象语法树越靠下的优先级越高。
总结:代码生成的本质和语义检查差不多,都是对抽象语法树做操作,只不过一个是生成目标代码,一个是对树做语义检查。用的的算法思想也一样,都是递归下降算法。本节代码生成最终生成的代码是伪代码,或者叫中间代码,并不是具体的某种汇编指令。
如何运行生成的代码?
- 写一个虚拟机(解释器)
- 在真实的机器上运行(还需要进行分配)