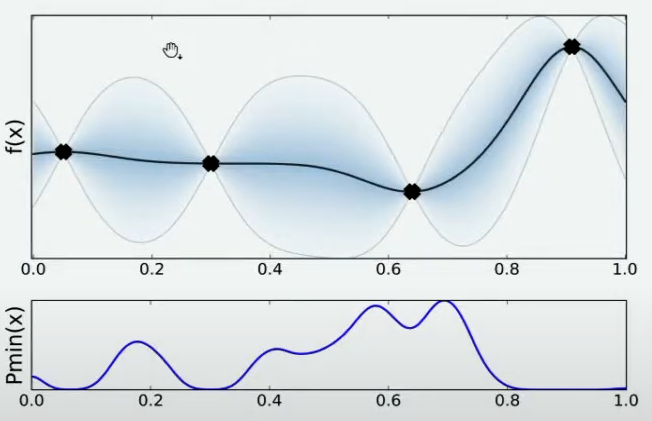
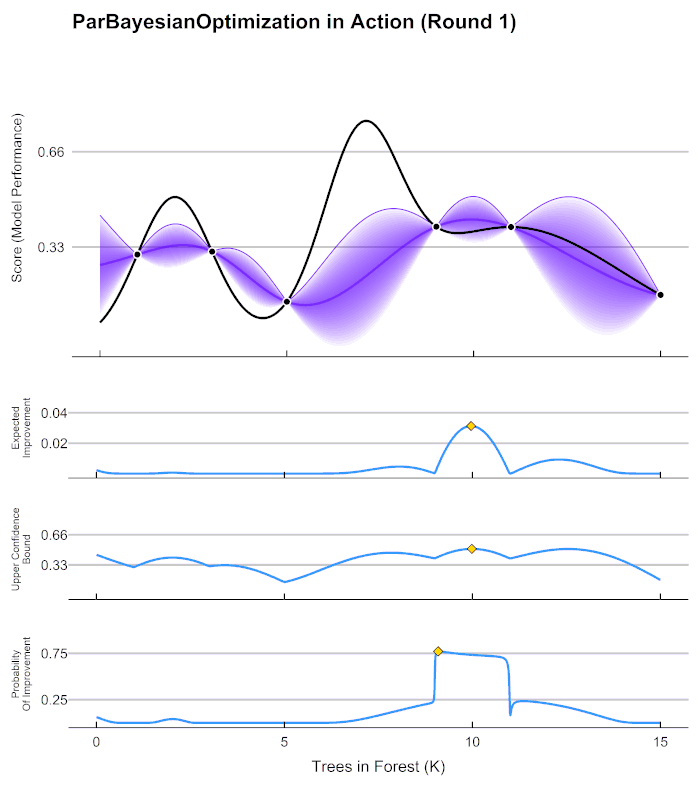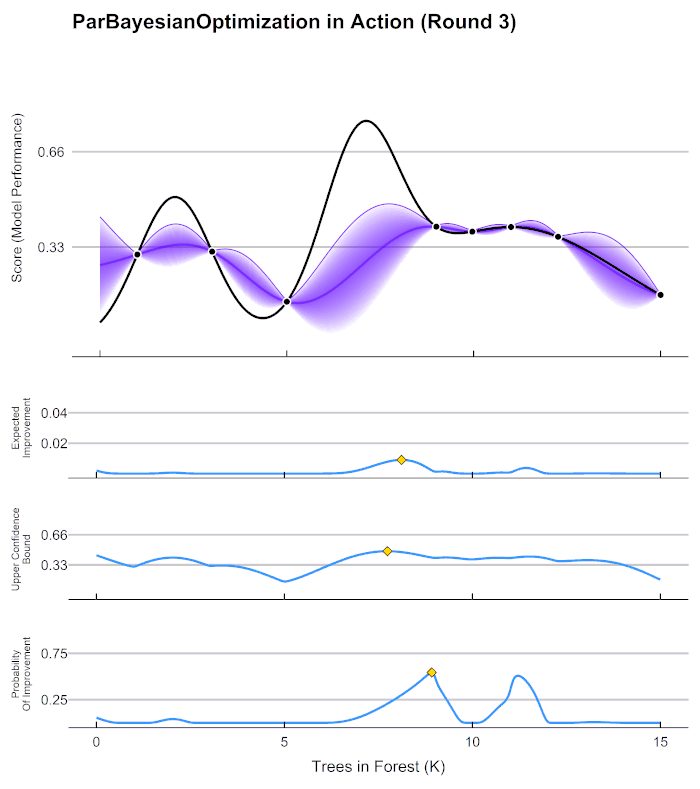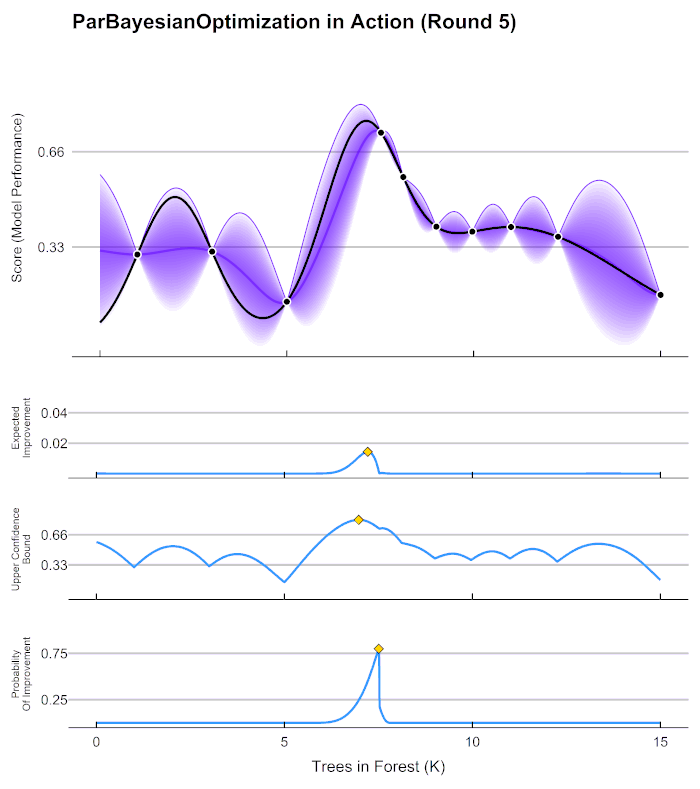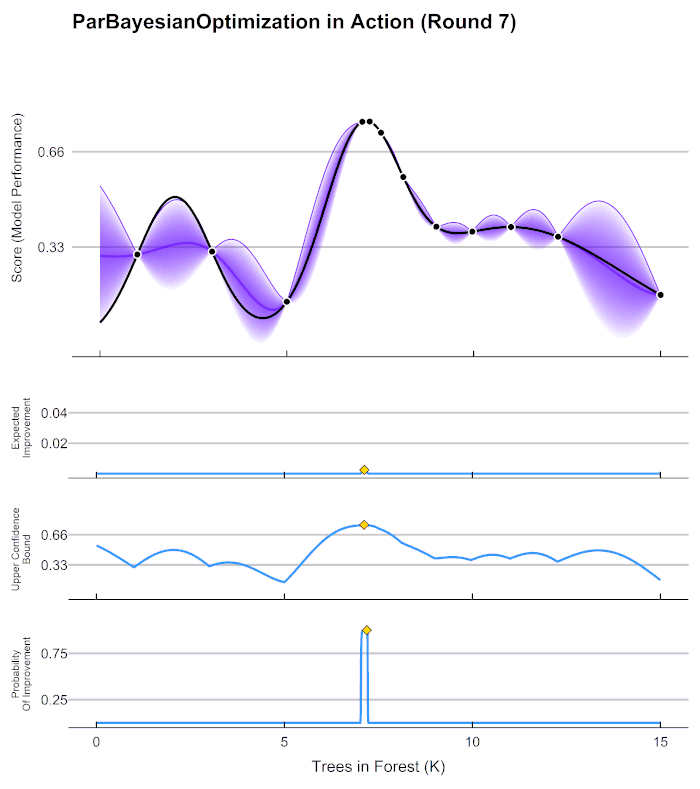
[I 2021-12-24 22:14:28,229] Trial 0 finished with value: 28848.70339210933 and parameters: {'n_estimators': 99, 'max_depth': 14, 'max_features': 16, 'min_impurity_decrease': 4}. Best is trial 0 with value: 28848.70339210933.
[I 2021-12-24 22:14:29,309] Trial 1 finished with value: 28632.395126147465 and parameters: {'n_estimators': 90, 'max_depth': 23, 'max_features': 16, 'min_impurity_decrease': 2}. Best is trial 1 with value: 28632.395126147465.
[I 2021-12-24 22:14:30,346] Trial 2 finished with value: 29301.159287113685 and parameters: {'n_estimators': 89, 'max_depth': 17, 'max_features': 12, 'min_impurity_decrease': 0}. Best is trial 1 with value: 28632.395126147465.
[I 2021-12-24 22:14:31,215] Trial 3 finished with value: 29756.446415640086 and parameters: {'n_estimators': 80, 'max_depth': 11, 'max_features': 14, 'min_impurity_decrease': 3}. Best is trial 1 with value: 28632.395126147465.
[I 2021-12-24 22:14:31,439] Trial 4 finished with value: 29784.547574554617 and parameters: {'n_estimators': 88, 'max_depth': 11, 'max_features': 15, 'min_impurity_decrease': 2}. Best is trial 1 with value: 28632.395126147465.
[I 2021-12-24 22:14:31,651] Trial 5 finished with value: 28854.291800282757 and parameters: {'n_estimators': 82, 'max_depth': 12, 'max_features': 18, 'min_impurity_decrease': 3}. Best is trial 1 with value: 28632.395126147465.
[I 2021-12-24 22:14:31,853] Trial 6 finished with value: 29268.28890743908 and parameters: {'n_estimators': 80, 'max_depth': 10, 'max_features': 19, 'min_impurity_decrease': 5}. Best is trial 1 with value: 28632.395126147465.
[I 2021-12-24 22:14:32,111] Trial 7 finished with value: 29302.5258321895 and parameters: {'n_estimators': 99, 'max_depth': 16, 'max_features': 14, 'min_impurity_decrease': 3}. Best is trial 1 with value: 28632.395126147465.
[I 2021-12-24 22:14:32,353] Trial 8 finished with value: 29449.903990989755 and parameters: {'n_estimators': 80, 'max_depth': 21, 'max_features': 17, 'min_impurity_decrease': 1}. Best is trial 1 with value: 28632.395126147465.
[I 2021-12-24 22:14:32,737] Trial 9 finished with value: 29168.76064401323 and parameters: {'n_estimators': 97, 'max_depth': 22, 'max_features': 17, 'min_impurity_decrease': 1}. Best is trial 1 with value: 28632.395126147465.
best params: {'n_estimators': 90, 'max_depth': 23, 'max_features': 16, 'min_impurity_decrease': 2}
best score: [28632.395126147465]